 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMK-SQuIT: Synthesizing Questions using Iterative Template-filling
Paper and Code

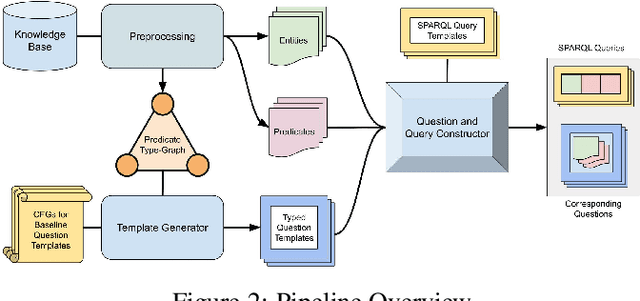


The aim of this work is to create a framework for synthetically generating question/query pairs with as little human input as possible. These datasets can be used to train machine translation systems to convert natural language questions into queries, a useful tool that could allow for more natural access to database information. Existing methods of dataset generation require human input that scales linearly with the size of the dataset, resulting in small datasets. Aside from a short initial configuration task, no human input is required during the query generation process of our system. We leverage WikiData, a knowledge base of RDF triples, as a source for generating the main content of questions and queries. Using multiple layers of question templating we are able to sidestep some of the most challenging parts of query generation that have been handled by humans in previous methods; humans never have to modify, aggregate, inspect, annotate, or generate any questions or queries at any step in the process. Our system is easily configurable to multiple domains and can be modified to generate queries in natural languages other than English. We also present an example dataset of 110,000 question/query pairs across four WikiData domains. We then present a baseline model that we train using the dataset which shows promise in a commercial QA setting.