 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Abstract World Model for Value-preserving Planning with Options
Jun 22, 2024General-purpose agents require fine-grained controls and rich sensory inputs to perform a wide range of tasks. However, this complexity often leads to intractable decision-making. Traditionally, agents are provided with task-specific action and observation spaces to mitigate this challenge, but this reduces autonomy. Instead, agents must be capable of building state-action spaces at the correct abstraction level from their sensorimotor experiences. We leverage the structure of a given set of temporally-extended actions to learn abstract Markov decision processes (MDPs) that operate at a higher level of temporal and state granularity. We characterize state abstractions necessary to ensure that planning with these skills, by simulating trajectories in the abstract MDP, results in policies with bounded value loss in the original MDP. We evaluate our approach in goal-based navigation environments that require continuous abstract states to plan successfully and show that abstract model learning improves the sample efficiency of planning and learning.
RLang: A Declarative Language for Expression Prior Knowledge for Reinforcement Learning
Aug 16, 2022

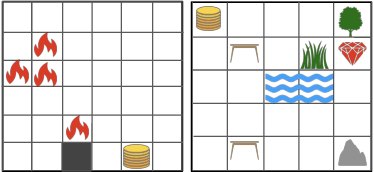
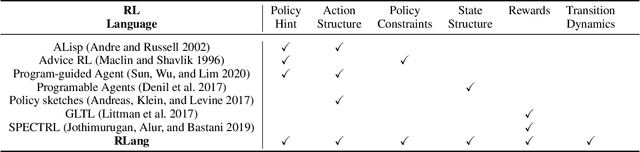
Communicating useful background knowledge to reinforcement learning (RL) agents is an important and effective method for accelerating learning. We introduce RLang, a domain-specific language (DSL) for communicating domain knowledge to an RL agent. Unlike other existing DSLs proposed by the RL community that ground to single elements of a decision-making formalism (e.g., the reward function or policy function), RLang can specify information about every element of a Markov decision process. We define precise syntax and grounding semantics for RLang, and provide a parser implementation that grounds RLang programs to an algorithm-agnostic partial world model and policy that can be exploited by an RL agent. We provide a series of example RLang programs, and demonstrate how different RL methods can exploit the resulting knowledge, including model-free and model-based tabular algorithms, hierarchical approaches, and deep RL algorithms (including both policy gradient and value-based methods).