 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Aware Attenuation Field Learning for Sparse-View CBCT Reconstruction
Paper and Code
Mar 26, 2023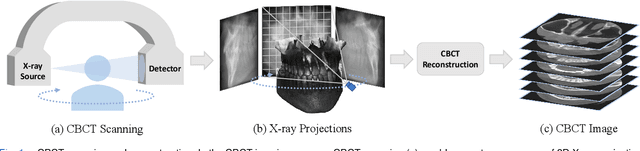
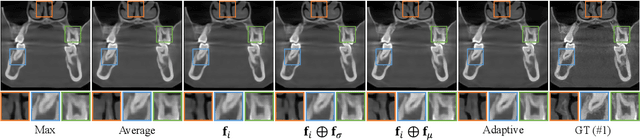
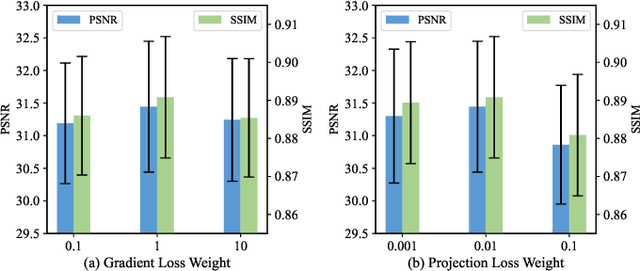
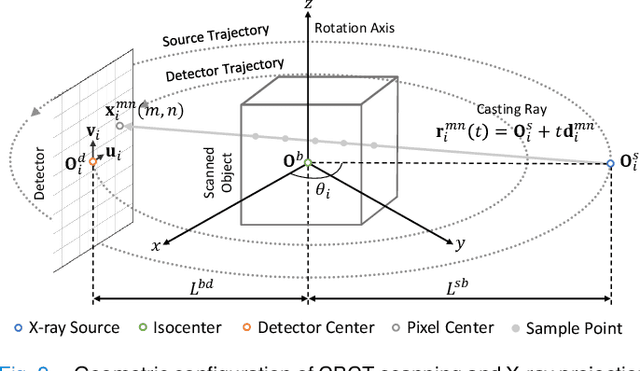
Cone Beam Computed Tomography (CBCT) is the most widely used imaging method in dentistry. As hundreds of X-ray projections are needed to reconstruct a high-quality CBCT image (i.e., the attenuation field) in traditional algorithms, sparse-view CBCT reconstruction has become a main focus to reduce radiation dose. Several attempts have been made to solve it while still suffering from insufficient data or poor generalization ability for novel patients. This paper proposes a novel attenuation field encoder-decoder framework by first encoding the volumetric feature from multi-view X-ray projections, then decoding it into the desired attenuation field. The key insight is when building the volumetric feature, we comply with the multi-view CBCT reconstruction nature and emphasize the view consistency property by geometry-aware spatial feature querying and adaptive feature fusing. Moreover, the prior knowledge information learned from data population guarantees our generalization ability when dealing with sparse view input. Comprehensive evaluations have demonstrated the superiority in terms of reconstruction quality, and the downstream application further validates the feasibility of our method in real-world clinics.