 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior-Centric Extraction of Scenarios from Highway Traffic Data and their Domain-Knowledge-Guided Clustering using CVQ-VAE
Mar 17, 2026Approval of ADS depends on evaluating its behavior within representative real-world traffic scenarios. A common way to obtain such scenarios is to extract them from real-world data recordings. These can then be grouped and serve as basis on which the ADS is subsequently tested. This poses two central challenges: how scenarios are extracted and how they are grouped. Existing extraction methods rely on heterogeneous definitions, hindering scenario comparability. For the grouping of scenarios, rule-based or ML-based methods can be utilized. However, while modern ML-based approaches can handle the complexity of traffic scenarios, unlike rule-based approaches, they lack interpretability and may not align with domain-knowledge. This work contributes to a standardized scenario extraction based on the Scenario-as-Specification concept, as well as a domain-knowledge-guided scenario clustering process. Experiments on the highD dataset demonstrate that scenarios can be extracted reliably and that domain-knowledge can be effectively integrated into the clustering process. As a result, the proposed methodology supports a more standardized process for deriving scenario categories from highway data recordings and thus enables a more efficient validation process of automated vehicles.
Uncertainty-Aware Diffusion Model for Multimodal Highway Trajectory Prediction via DDIM Sampling
Feb 24, 2026Accurate and uncertainty-aware trajectory prediction remains a core challenge for autonomous driving, driven by complex multi-agent interactions, diverse scene contexts and the inherently stochastic nature of future motion. Diffusion-based generative models have recently shown strong potential for capturing multimodal futures, yet existing approaches such as cVMD suffer from slow sampling, limited exploitation of generative diversity and brittle scenario encodings. This work introduces cVMDx, an enhanced diffusion-based trajectory prediction framework that improves efficiency, robustness and multimodal predictive capability. Through DDIM sampling, cVMDx achieves up to a 100x reduction in inference time, enabling practical multi-sample generation for uncertainty estimation. A fitted Gaussian Mixture Model further provides tractable multimodal predictions from the generated trajectories. In addition, a CVQ-VAE variant is evaluated for scenario encoding. Experiments on the publicly available highD dataset show that cVMDx achieves higher accuracy and significantly improved efficiency over cVMD, enabling fully stochastic, multimodal trajectory prediction.
Online Monitoring Framework for Automotive Time Series Data using JEPA Embeddings
Feb 10, 2026As autonomous vehicles are rolled out, measures must be taken to ensure their safe operation. In order to supervise a system that is already in operation, monitoring frameworks are frequently employed. These run continuously online in the background, supervising the system status and recording anomalies. This work proposes an online monitoring framework to detect anomalies in object state representations. Thereby, a key challenge is creating a framework for anomaly detection without anomaly labels, which are usually unavailable for unknown anomalies. To address this issue, this work applies a self-supervised embedding method to translate object data into a latent representation space. For this, a JEPA-based self-supervised prediction task is constructed, allowing training without anomaly labels and the creation of rich object embeddings. The resulting expressive JEPA embeddings serve as input for established anomaly detection methods, in order to identify anomalies within object state representations. This framework is particularly useful for applications in real-world environments, where new or unknown anomalies may occur during operation for which there are no labels available. Experiments performed on the publicly available, real-world nuScenes dataset illustrate the framework's capabilities.
Machine Learning Architectures for the Estimation of Predicted Occupancy Grids in Road Traffic
Dec 15, 2025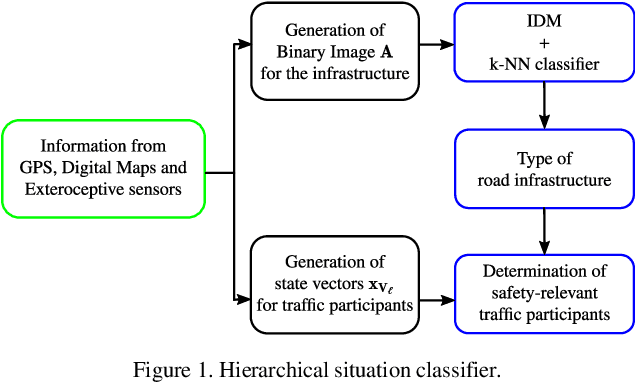
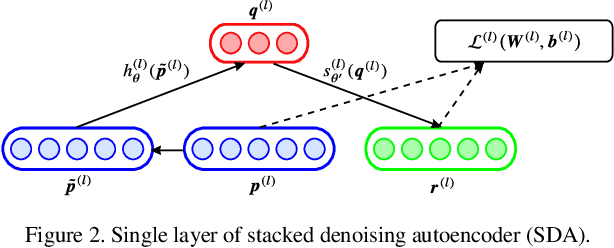
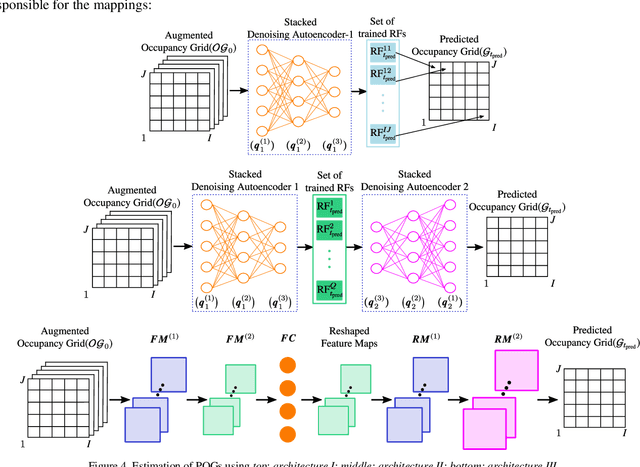
This paper introduces a novel machine learning architecture for an efficient estimation of the probabilistic space-time representation of complex traffic scenarios. A detailed representation of the future traffic scenario is of significant importance for autonomous driving and for all active safety systems. In order to predict the future space-time representation of the traffic scenario, first the type of traffic scenario is identified and then the machine learning algorithm maps the current state of the scenario to possible future states. The input to the machine learning algorithms is the current state representation of a traffic scenario, termed as the Augmented Occupancy Grid (AOG). The output is the probabilistic space-time representation which includes uncertainties regarding the behaviour of the traffic participants and is termed as the Predicted Occupancy Grid (POG). The novel architecture consists of two Stacked Denoising Autoencoders (SDAs) and a set of Random Forests. It is then compared with the other two existing architectures that comprise of SDAs and DeconvNet. The architectures are validated with the help of simulations and the comparisons are made both in terms of accuracy and computational time. Also, a brief overview on the applications of POGs in the field of active safety is presented.
Predicted-occupancy grids for vehicle safety applications based on autoencoders and the Random Forest algorithm
Dec 15, 2025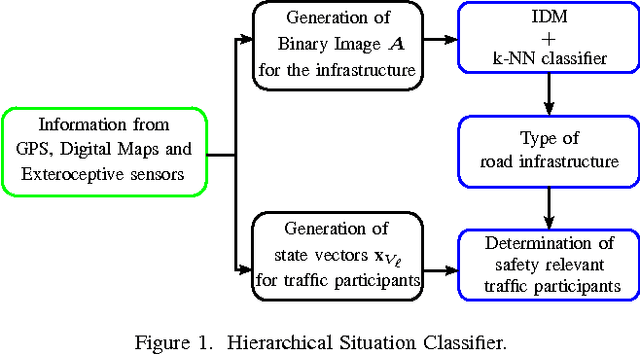
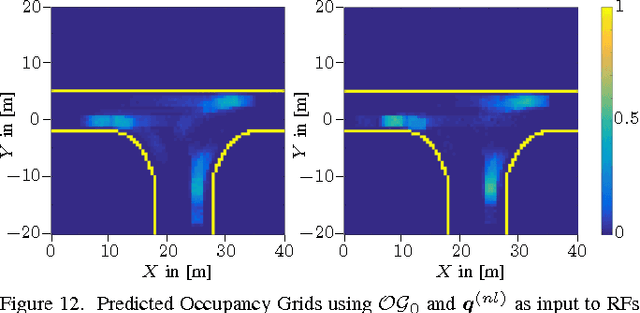

In this paper, a probabilistic space-time representation of complex traffic scenarios is predicted using machine learning algorithms. Such a representation is significant for all active vehicle safety applications especially when performing dynamic maneuvers in a complex traffic scenario. As a first step, a hierarchical situation classifier is used to distinguish the different types of traffic scenarios. This classifier is responsible for identifying the type of the road infrastructure and the safety-relevant traffic participants of the driving environment. With each class representing similar traffic scenarios, a set of Random Forests (RFs) is individually trained to predict the probabilistic space-time representation, which depicts the future behavior of traffic participants. This representation is termed as a Predicted-Occupancy Grid (POG). The input to the RFs is an Augmented Occupancy Grid (AOG). In order to increase the learning accuracy of the RFs and to perform better predictions, the AOG is reduced to low-dimensional features using a Stacked Denoising Autoencoder (SDA). The excellent performance of the proposed machine learning approach consisting of SDAs and RFs is demonstrated in simulations and in experiments with real vehicles. An application of POGs to estimate the criticality of traffic scenarios and to determine safe trajectories is also presented.
Probability Estimation for Predicted-Occupancy Grids in Vehicle Safety Applications Based on Machine Learning
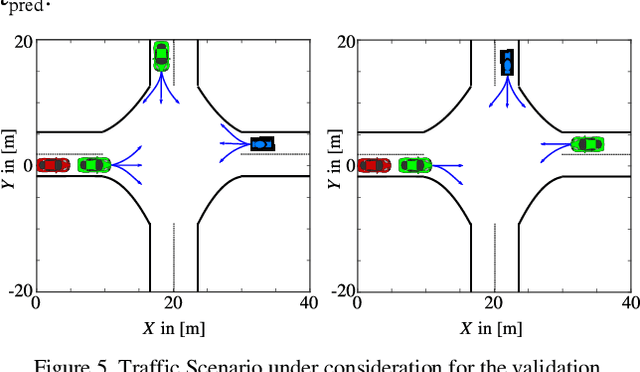
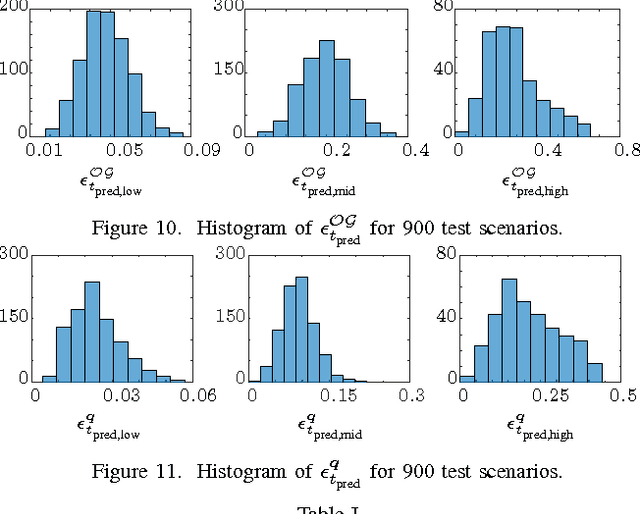
Dec 15, 2025This paper presents a method to predict the evolution of a complex traffic scenario with multiple objects. The current state of the scenario is assumed to be known from sensors and the prediction is taking into account various hypotheses about the behavior of traffic participants. This way, the uncertainties regarding the behavior of traffic participants can be modelled in detail. In the first part of this paper a model-based approach is presented to compute Predicted-Occupancy Grids (POG), which are introduced as a grid-based probabilistic representation of the future scenario hypotheses. However, due to the large number of possible trajectories for each traffic participant, the model-based approach comes with a very high computational load. Thus, a machine-learning approach is adopted for the computation of POGs. This work uses a novel grid-based representation of the current state of the traffic scenario and performs the mapping to POGs. This representation consists of augmented cells in an occupancy grid. The adopted machine-learning approach is based on the Random Forest algorithm. Simulations of traffic scenarios are performed to compare the machine-learning with the model-based approach. The results are promising and could enable the real-time computation of POGs for vehicle safety applications. With this detailed modelling of uncertainties, crucial components in vehicle safety systems like criticality estimation and trajectory planning can be improved.
Uncertainty-Aware Hybrid Machine Learning in Virtual Sensors for Vehicle Sideslip Angle Estimation
Apr 08, 2025Precise vehicle state estimation is crucial for safe and reliable autonomous driving. The number of measurable states and their precision offered by the onboard vehicle sensor system are often constrained by cost. For instance, measuring critical quantities such as the Vehicle Sideslip Angle (VSA) poses significant commercial challenges using current optical sensors. This paper addresses these limitations by focusing on the development of high-performance virtual sensors to enhance vehicle state estimation for active safety. The proposed Uncertainty-Aware Hybrid Learning (UAHL) architecture integrates a machine learning model with vehicle motion models to estimate VSA directly from onboard sensor data. A key aspect of the UAHL architecture is its focus on uncertainty quantification for individual model estimates and hybrid fusion. These mechanisms enable the dynamic weighting of uncertainty-aware predictions from machine learning and vehicle motion models to produce accurate and reliable hybrid VSA estimates. This work also presents a novel dataset named Real-world Vehicle State Estimation Dataset (ReV-StED), comprising synchronized measurements from advanced vehicle dynamic sensors. The experimental results demonstrate the superior performance of the proposed method for VSA estimation, highlighting UAHL as a promising architecture for advancing virtual sensors and enhancing active safety in autonomous vehicles.
Hybrid Machine Learning Model with a Constrained Action Space for Trajectory Prediction
Jan 07, 2025



Trajectory prediction is crucial to advance autonomous driving, improving safety, and efficiency. Although end-to-end models based on deep learning have great potential, they often do not consider vehicle dynamic limitations, leading to unrealistic predictions. To address this problem, this work introduces a novel hybrid model that combines deep learning with a kinematic motion model. It is able to predict object attributes such as acceleration and yaw rate and generate trajectories based on them. A key contribution is the incorporation of expert knowledge into the learning objective of the deep learning model. This results in the constraint of the available action space, thus enabling the prediction of physically feasible object attributes and trajectories, thereby increasing safety and robustness. The proposed hybrid model facilitates enhanced interpretability, thereby reinforcing the trustworthiness of deep learning methods and promoting the development of safe planning solutions. Experiments conducted on the publicly available real-world Argoverse dataset demonstrate realistic driving behaviour, with benchmark comparisons and ablation studies showing promising results.
Reliable Trajectory Prediction and Uncertainty Quantification with Conditioned Diffusion Models
May 23, 2024This work introduces the conditioned Vehicle Motion Diffusion (cVMD) model, a novel network architecture for highway trajectory prediction using diffusion models. The proposed model ensures the drivability of the predicted trajectory by integrating non-holonomic motion constraints and physical constraints into the generative prediction module. Central to the architecture of cVMD is its capacity to perform uncertainty quantification, a feature that is crucial in safety-critical applications. By integrating the quantified uncertainty into the prediction process, the cVMD's trajectory prediction performance is improved considerably. The model's performance was evaluated using the publicly available highD dataset. Experiments show that the proposed architecture achieves competitive trajectory prediction accuracy compared to state-of-the-art models, while providing guaranteed drivable trajectories and uncertainty quantification.
Optimization and Interpretability of Graph Attention Networks for Small Sparse Graph Structures in Automotive Applications
May 25, 2023For automotive applications, the Graph Attention Network (GAT) is a prominently used architecture to include relational information of a traffic scenario during feature embedding. As shown in this work, however, one of the most popular GAT realizations, namely GATv2, has potential pitfalls that hinder an optimal parameter learning. Especially for small and sparse graph structures a proper optimization is problematic. To surpass limitations, this work proposes architectural modifications of GATv2. In controlled experiments, it is shown that the proposed model adaptions improve prediction performance in a node-level regression task and make it more robust to parameter initialization. This work aims for a better understanding of the attention mechanism and analyzes its interpretability of identifying causal importance.