 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGENPACK: KPI-Guided Multi-Objective Genetic Algorithm for Industrial 3D Bin Packing
Jan 16, 2026The three-dimensional bin packing problem (3D-BPP) is a longstanding challenge in operations research and logistics. Classical heuristics and constructive methods can generate packings quickly, but often fail to address industrial constraints such as stability, balance, and handling feasibility. Metaheuristics such as genetic algorithms (GAs) provide flexibility and the ability to optimize across multiple objectives; however, pure GA approaches frequently struggle with efficiency, parameter sensitivity, and scalability to industrial order sizes. This gap is especially evident when scaling to real-world pallet dimensions, where even state-of-the-art algorithms often fail to achieve robust, deployable solutions. We propose a KPI-driven GA-based pipeline for industrial 3D-BPP that integrates key performance indicators directly into a multi-objective fitness function. The methodology combines a layer-based chromosome representation with domain-specific operators and constructive heuristics to balance efficiency and feasibility. On the BED-BPP benchmark of 1,500 real-world orders, our Hybrid-GA pipeline consistently outperforms heuristic- and learning-based state-of-the-art methods, achieving up to 35% higher space utilization and 15 to 20% stronger surface support, with lower variance across orders. These improvements come at a modest runtime cost but remain feasible for batch-scale deployment, yielding stable, balanced, and space-efficient packings.
Reliable Trajectory Prediction and Uncertainty Quantification with Conditioned Diffusion Models
May 23, 2024This work introduces the conditioned Vehicle Motion Diffusion (cVMD) model, a novel network architecture for highway trajectory prediction using diffusion models. The proposed model ensures the drivability of the predicted trajectory by integrating non-holonomic motion constraints and physical constraints into the generative prediction module. Central to the architecture of cVMD is its capacity to perform uncertainty quantification, a feature that is crucial in safety-critical applications. By integrating the quantified uncertainty into the prediction process, the cVMD's trajectory prediction performance is improved considerably. The model's performance was evaluated using the publicly available highD dataset. Experiments show that the proposed architecture achieves competitive trajectory prediction accuracy compared to state-of-the-art models, while providing guaranteed drivable trajectories and uncertainty quantification.
Optimization and Interpretability of Graph Attention Networks for Small Sparse Graph Structures in Automotive Applications
May 25, 2023For automotive applications, the Graph Attention Network (GAT) is a prominently used architecture to include relational information of a traffic scenario during feature embedding. As shown in this work, however, one of the most popular GAT realizations, namely GATv2, has potential pitfalls that hinder an optimal parameter learning. Especially for small and sparse graph structures a proper optimization is problematic. To surpass limitations, this work proposes architectural modifications of GATv2. In controlled experiments, it is shown that the proposed model adaptions improve prediction performance in a node-level regression task and make it more robust to parameter initialization. This work aims for a better understanding of the attention mechanism and analyzes its interpretability of identifying causal importance.
Gradient Derivation for Learnable Parameters in Graph Attention Networks
Apr 21, 2023

This work provides a comprehensive derivation of the parameter gradients for GATv2 [4], a widely used implementation of Graph Attention Networks (GATs). GATs have proven to be powerful frameworks for processing graph-structured data and, hence, have been used in a range of applications. However, the achieved performance by these attempts has been found to be inconsistent across different datasets and the reasons for this remains an open research question. As the gradient flow provides valuable insights into the training dynamics of statistically learning models, this work obtains the gradients for the trainable model parameters of GATv2. The gradient derivations supplement the efforts of [2], where potential pitfalls of GATv2 are investigated.
Classification and Uncertainty Quantification of Corrupted Data using Semi-Supervised Autoencoders
May 27, 2021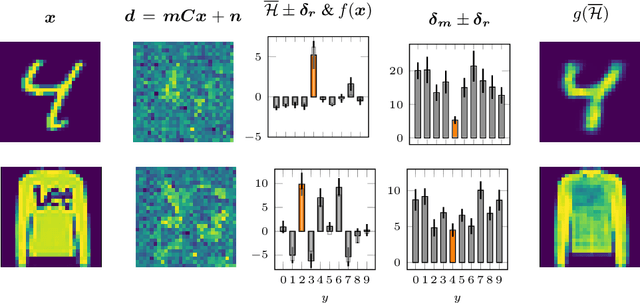
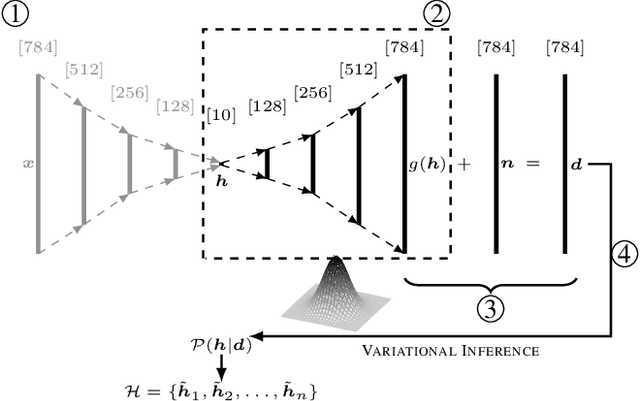
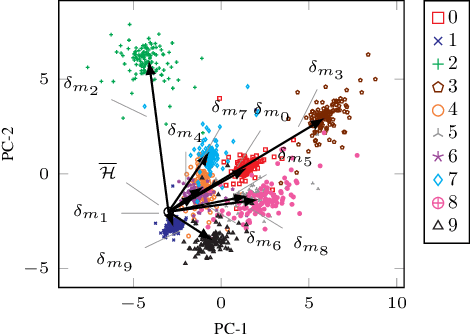
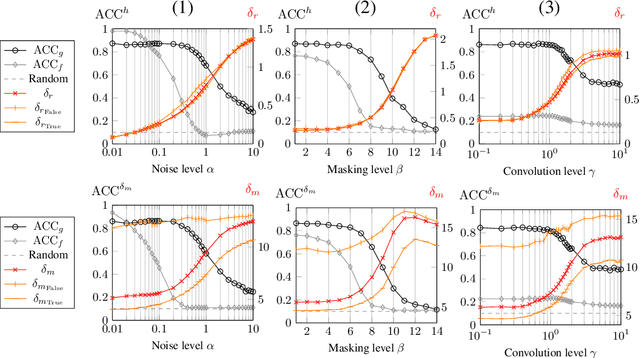
Parametric and non-parametric classifiers often have to deal with real-world data, where corruptions like noise, occlusions, and blur are unavoidable - posing significant challenges. We present a probabilistic approach to classify strongly corrupted data and quantify uncertainty, despite the model only having been trained with uncorrupted data. A semi-supervised autoencoder trained on uncorrupted data is the underlying architecture. We use the decoding part as a generative model for realistic data and extend it by convolutions, masking, and additive Gaussian noise to describe imperfections. This constitutes a statistical inference task in terms of the optimal latent space activations of the underlying uncorrupted datum. We solve this problem approximately with Metric Gaussian Variational Inference (MGVI). The supervision of the autoencoder's latent space allows us to classify corrupted data directly under uncertainty with the statistically inferred latent space activations. Furthermore, we demonstrate that the model uncertainty strongly depends on whether the classification is correct or wrong, setting a basis for a statistical "lie detector" of the classification. Independent of that, we show that the generative model can optimally restore the uncorrupted datum by decoding the inferred latent space activations.
Center3D: Center-based Monocular 3D Object Detection with Joint Depth Understanding
May 27, 2020
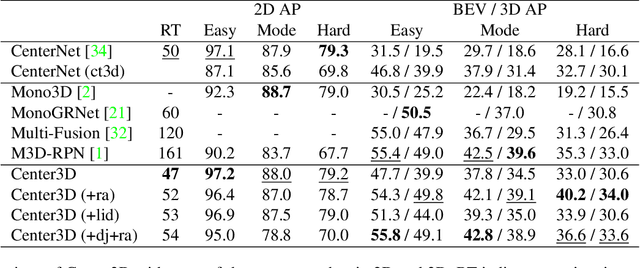

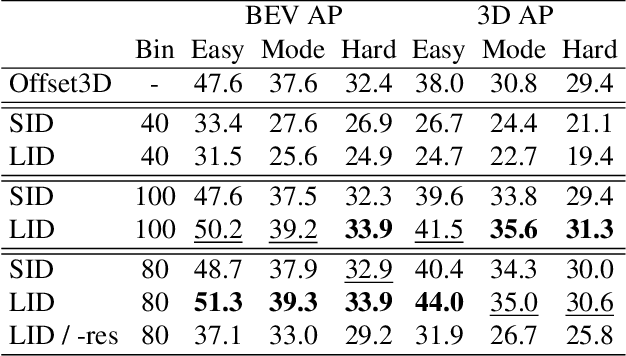
Localizing objects in 3D space and understanding their associated 3D properties is challenging given only monocular RGB images. The situation is compounded by the loss of depth information during perspective projection. We present Center3D, a one-stage anchor-free approach, to efficiently estimate 3D location and depth using only monocular RGB images. By exploiting the difference between 2D and 3D centers, we are able to estimate depth consistently. Center3D uses a combination of classification and regression to understand the hidden depth information more robustly than each method alone. Our method employs two joint approaches: (1) LID: a classification-dominated approach with sequential Linear Increasing Discretization. (2) DepJoint: a regression-dominated approach with multiple Eigen's transformations for depth estimation. Evaluating on KITTI dataset for moderate objects, Center3D improved the AP in BEV from $29.7\%$ to $42.8\%$, and the AP in 3D from $18.6\%$ to $39.1\%$. Compared with state-of-the-art detectors, Center3D has achieved the best speed-accuracy trade-off in realtime monocular object detection.
A2D2: Audi Autonomous Driving Dataset
Apr 14, 2020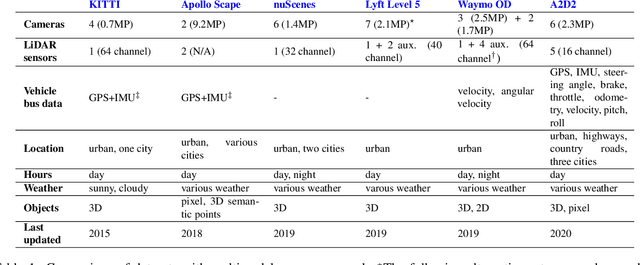



Research in machine learning, mobile robotics, and autonomous driving is accelerated by the availability of high quality annotated data. To this end, we release the Audi Autonomous Driving Dataset (A2D2). Our dataset consists of simultaneously recorded images and 3D point clouds, together with 3D bounding boxes, semantic segmentation, instance segmentation, and data extracted from the automotive bus. Our sensor suite consists of six cameras and five LiDAR units, providing full 360 degree coverage. The recorded data is time synchronized and mutually registered. Annotations are for non-sequential frames: 41,277 frames with semantic segmentation image and point cloud labels, of which 12,497 frames also have 3D bounding box annotations for objects within the field of view of the front camera. In addition, we provide 392,556 sequential frames of unannotated sensor data for recordings in three cities in the south of Germany. These sequences contain several loops. Faces and vehicle number plates are blurred due to GDPR legislation and to preserve anonymity. A2D2 is made available under the CC BY-ND 4.0 license, permitting commercial use subject to the terms of the license. Data and further information are available at http://www.a2d2.audi.
Signal inference with unknown response: Calibration-uncertainty renormalized estimator
Mar 02, 2015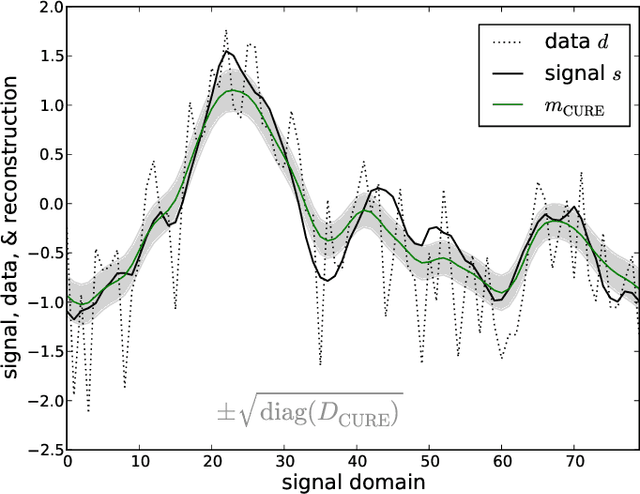
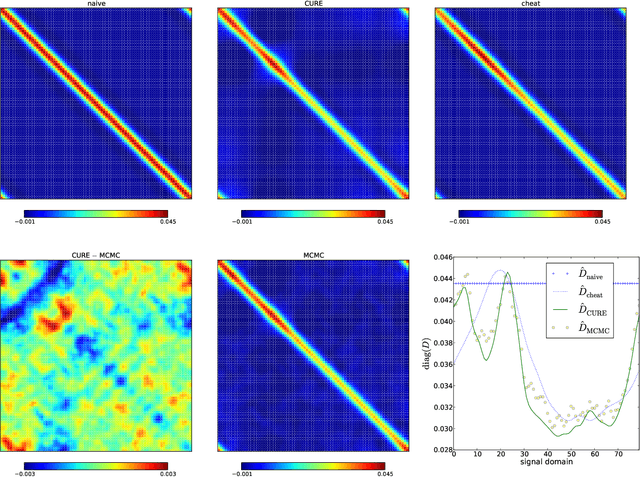
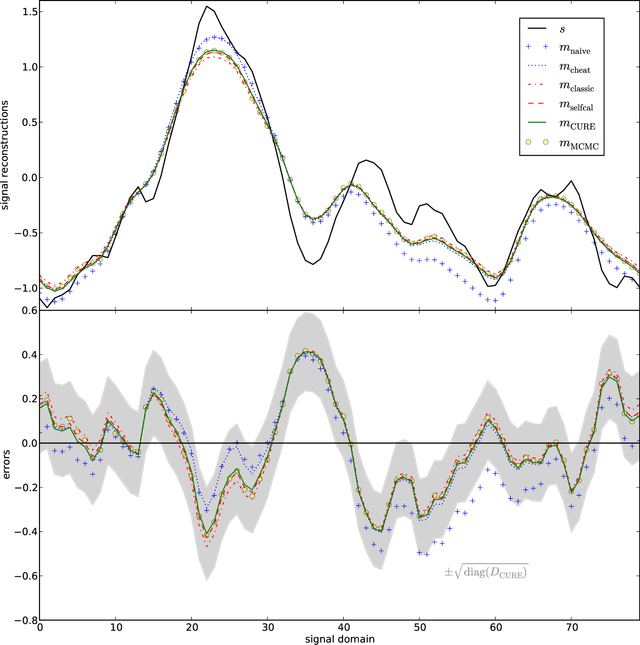
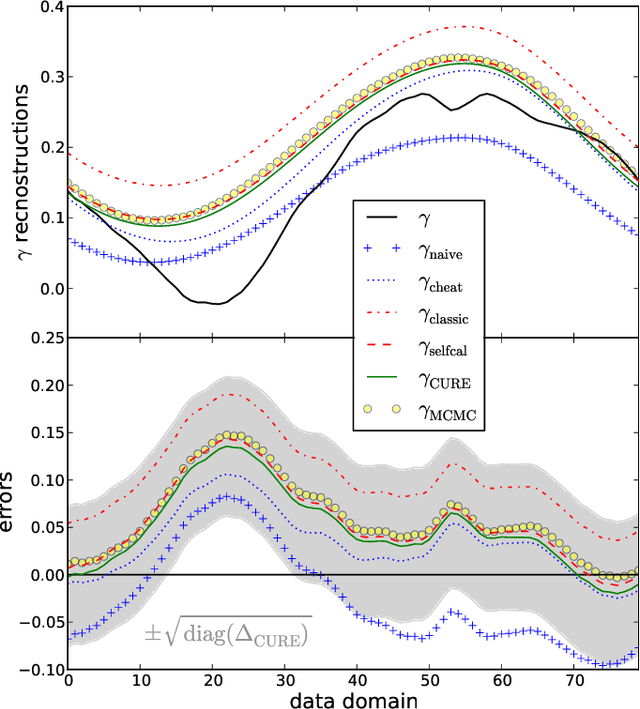
The calibration of a measurement device is crucial for every scientific experiment, where a signal has to be inferred from data. We present CURE, the calibration uncertainty renormalized estimator, to reconstruct a signal and simultaneously the instrument's calibration from the same data without knowing the exact calibration, but its covariance structure. The idea of CURE, developed in the framework of information field theory, is starting with an assumed calibration to successively include more and more portions of calibration uncertainty into the signal inference equations and to absorb the resulting corrections into renormalized signal (and calibration) solutions. Thereby, the signal inference and calibration problem turns into solving a single system of ordinary differential equations and can be identified with common resummation techniques used in field theories. We verify CURE by applying it to a simplistic toy example and compare it against existent self-calibration schemes, Wiener filter solutions, and Markov Chain Monte Carlo sampling. We conclude that the method is able to keep up in accuracy with the best self-calibration methods and serves as a non-iterative alternative to it.