 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructuring a Training Strategy to Robustify Perception Models with Realistic Image Augmentations
Aug 30, 2024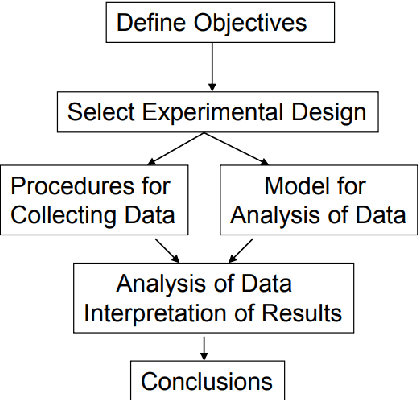


Advancing Machine Learning (ML)-based perception models for autonomous systems necessitates addressing weak spots within the models, particularly in challenging Operational Design Domains (ODDs). These are environmental operating conditions of an autonomous vehicle which can contain difficult conditions, e.g., lens flare at night or objects reflected in a wet street. This report introduces a novel methodology for training with augmentations to enhance model robustness and performance in such conditions. The proposed approach leverages customized physics-based augmentation functions, to generate realistic training data that simulates diverse ODD scenarios. We present a comprehensive framework that includes identifying weak spots in ML models, selecting suitable augmentations, and devising effective training strategies. The methodology integrates hyperparameter optimization and latent space optimization to fine-tune augmentation parameters, ensuring they maximally improve the ML models' performance. Experimental results demonstrate improvements in model performance, as measured by commonly used metrics such as mean Average Precision (mAP) and mean Intersection over Union (mIoU) on open-source object detection and semantic segmentation models and datasets. Our findings emphasize that optimal training strategies are model- and data-specific and highlight the benefits of integrating augmentations into the training pipeline. By incorporating augmentations, we observe enhanced robustness of ML-based perception models, making them more resilient to edge cases encountered in real-world ODDs. This work underlines the importance of customized augmentations and offers an effective solution for improving the safety and reliability of autonomous driving functions.
On Learning the Tail Quantiles of Driving Behavior Distributions via Quantile Regression and Flows
May 22, 2023Towards safe autonomous driving (AD), we consider the problem of learning models that accurately capture the diversity and tail quantiles of human driver behavior probability distributions, in interaction with an AD vehicle. Such models, which predict drivers' continuous actions from their states, are particularly relevant for closing the gap between AD simulation and reality. To this end, we adapt two flexible frameworks for this setting that avoid strong distributional assumptions: (1)~quantile regression (based on the titled absolute loss), and (2)~autoregressive quantile flows (a version of normalizing flows). Training happens in a behavior cloning-fashion. We evaluate our approach in a one-step prediction, as well as in multi-step simulation rollouts. We use the highD dataset consisting of driver trajectories on several highways. We report quantitative results using the tilted absolute loss as metric, give qualitative examples showing that realistic extremal behavior can be learned, and discuss the main insights.
Learning to Detect Adversarial Examples Based on Class Scores
Jul 09, 2021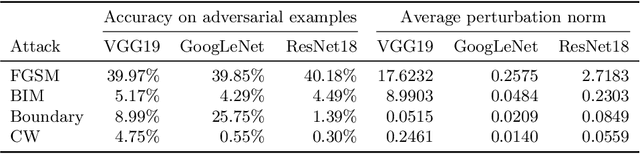

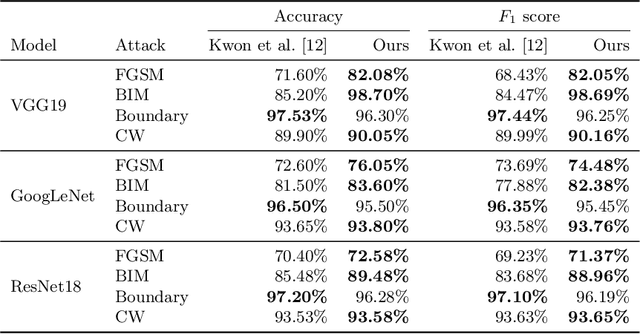
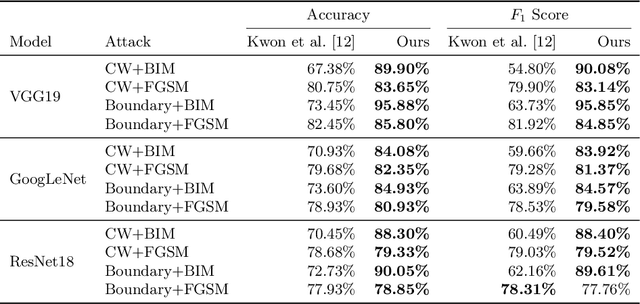
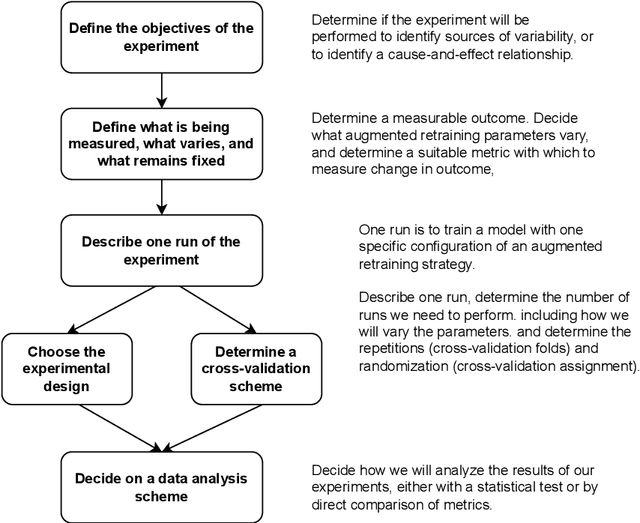
Given the increasing threat of adversarial attacks on deep neural networks (DNNs), research on efficient detection methods is more important than ever. In this work, we take a closer look at adversarial attack detection based on the class scores of an already trained classification model. We propose to train a support vector machine (SVM) on the class scores to detect adversarial examples. Our method is able to detect adversarial examples generated by various attacks, and can be easily adopted to a plethora of deep classification models. We show that our approach yields an improved detection rate compared to an existing method, whilst being easy to implement. We perform an extensive empirical analysis on different deep classification models, investigating various state-of-the-art adversarial attacks. Moreover, we observe that our proposed method is better at detecting a combination of adversarial attacks. This work indicates the potential of detecting various adversarial attacks simply by using the class scores of an already trained classification model.
Classification and Uncertainty Quantification of Corrupted Data using Semi-Supervised Autoencoders
May 27, 2021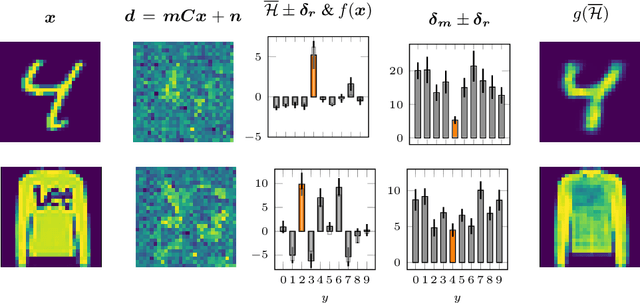
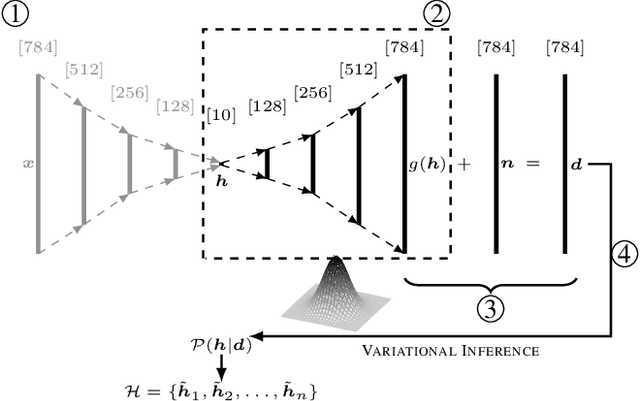
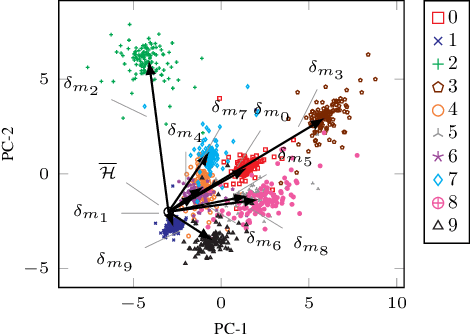
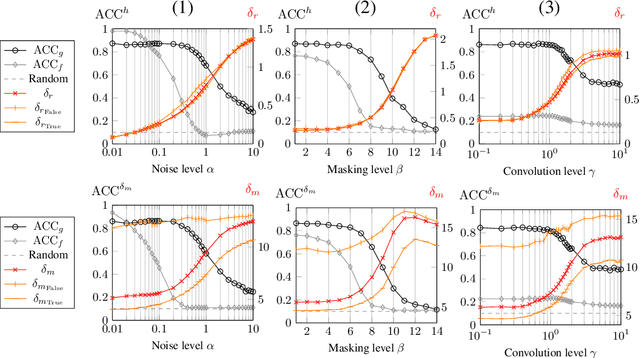
Parametric and non-parametric classifiers often have to deal with real-world data, where corruptions like noise, occlusions, and blur are unavoidable - posing significant challenges. We present a probabilistic approach to classify strongly corrupted data and quantify uncertainty, despite the model only having been trained with uncorrupted data. A semi-supervised autoencoder trained on uncorrupted data is the underlying architecture. We use the decoding part as a generative model for realistic data and extend it by convolutions, masking, and additive Gaussian noise to describe imperfections. This constitutes a statistical inference task in terms of the optimal latent space activations of the underlying uncorrupted datum. We solve this problem approximately with Metric Gaussian Variational Inference (MGVI). The supervision of the autoencoder's latent space allows us to classify corrupted data directly under uncertainty with the statistically inferred latent space activations. Furthermore, we demonstrate that the model uncertainty strongly depends on whether the classification is correct or wrong, setting a basis for a statistical "lie detector" of the classification. Independent of that, we show that the generative model can optimally restore the uncorrupted datum by decoding the inferred latent space activations.