 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimited-Angle Tomography Reconstruction via Deep End-To-End Learning on Synthetic Data
Sep 13, 2023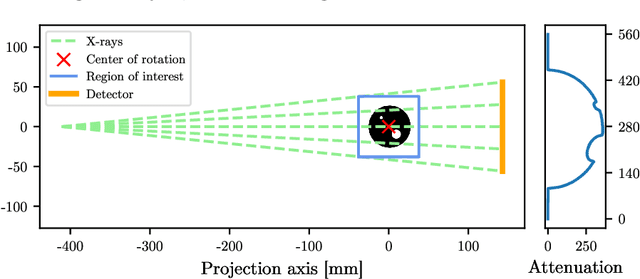

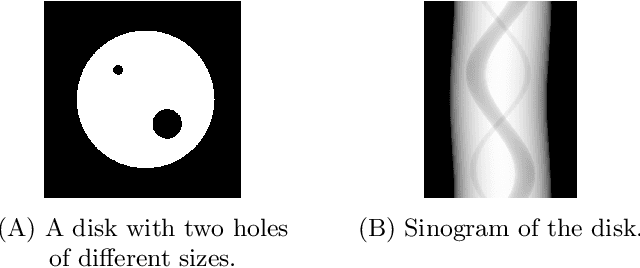
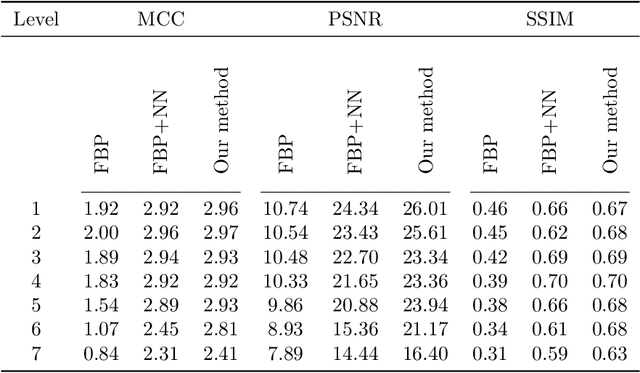
Computed tomography (CT) has become an essential part of modern science and medicine. A CT scanner consists of an X-ray source that is spun around an object of interest. On the opposite end of the X-ray source, a detector captures X-rays that are not absorbed by the object. The reconstruction of an image is a linear inverse problem, which is usually solved by filtered back projection. However, when the number of measurements is small, the reconstruction problem is ill-posed. This is for example the case when the X-ray source is not spun completely around the object, but rather irradiates the object only from a limited angle. To tackle this problem, we present a deep neural network that is trained on a large amount of carefully-crafted synthetic data and can perform limited-angle tomography reconstruction even for only 30{\deg} or 40{\deg} sinograms. With our approach we won the first place in the Helsinki Tomography Challenge 2022.
A Survey on Self-Supervised Representation Learning
Aug 22, 2023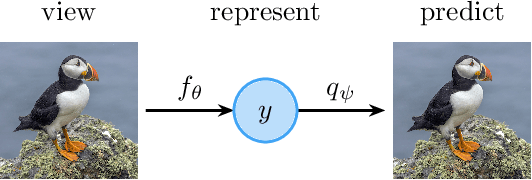

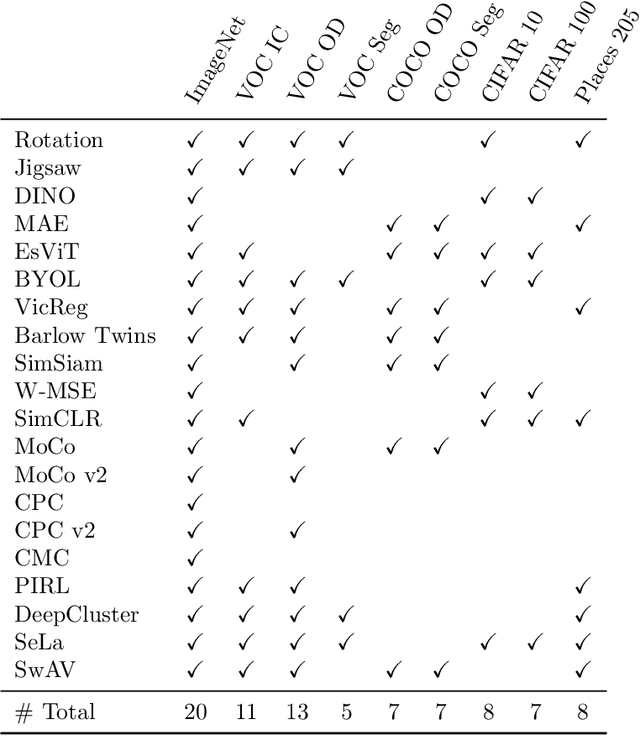
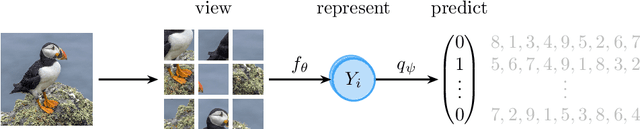
Learning meaningful representations is at the heart of many tasks in the field of modern machine learning. Recently, a lot of methods were introduced that allow learning of image representations without supervision. These representations can then be used in downstream tasks like classification or object detection. The quality of these representations is close to supervised learning, while no labeled images are needed. This survey paper provides a comprehensive review of these methods in a unified notation, points out similarities and differences of these methods, and proposes a taxonomy which sets these methods in relation to each other. Furthermore, our survey summarizes the most-recent experimental results reported in the literature in form of a meta-study. Our survey is intended as a starting point for researchers and practitioners who want to dive into the field of representation learning.
Transformer-based World Models Are Happy With 100k Interactions
Mar 13, 2023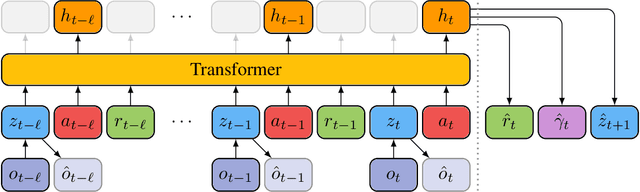
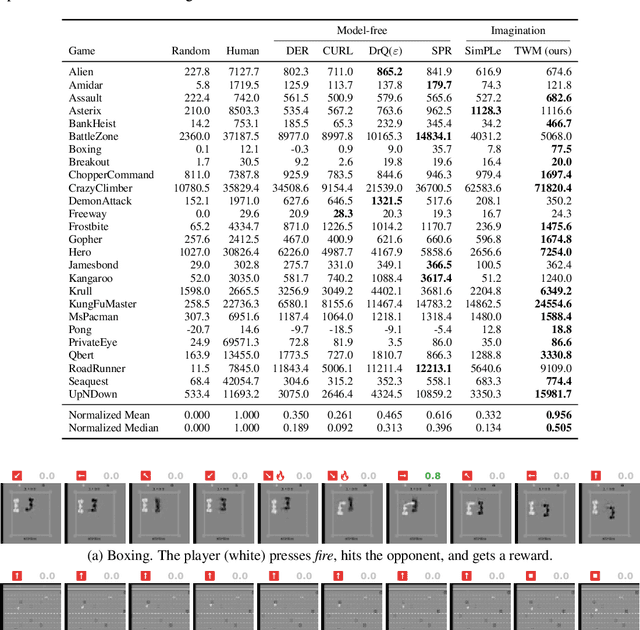
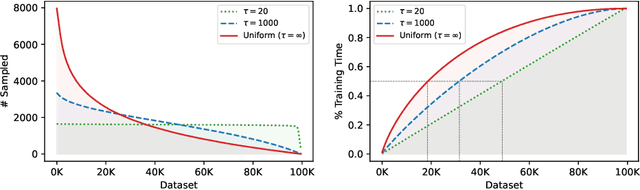
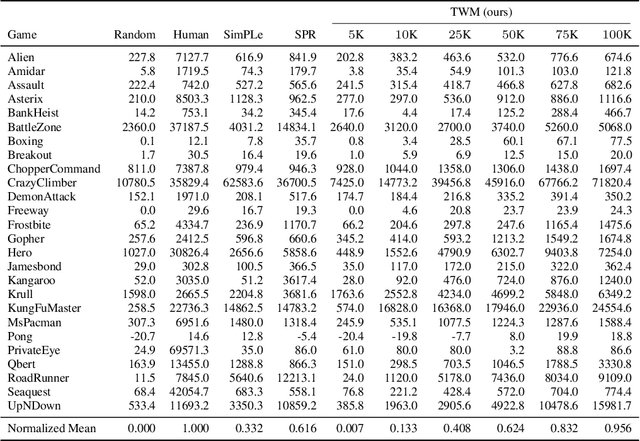
Deep neural networks have been successful in many reinforcement learning settings. However, compared to human learners they are overly data hungry. To build a sample-efficient world model, we apply a transformer to real-world episodes in an autoregressive manner: not only the compact latent states and the taken actions but also the experienced or predicted rewards are fed into the transformer, so that it can attend flexibly to all three modalities at different time steps. The transformer allows our world model to access previous states directly, instead of viewing them through a compressed recurrent state. By utilizing the Transformer-XL architecture, it is able to learn long-term dependencies while staying computationally efficient. Our transformer-based world model (TWM) generates meaningful, new experience, which is used to train a policy that outperforms previous model-free and model-based reinforcement learning algorithms on the Atari 100k benchmark.
Optimizing Intermediate Representations of Generative Models for Phase Retrieval
May 31, 2022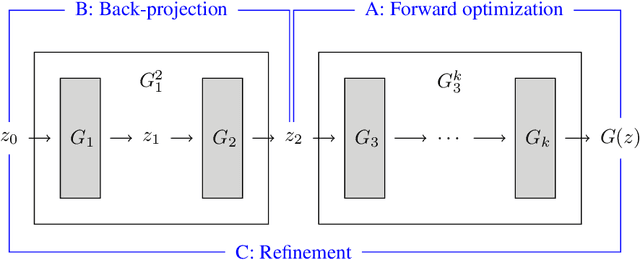
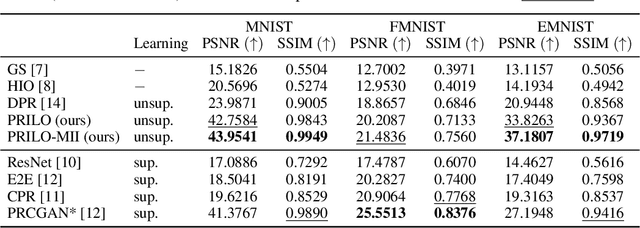
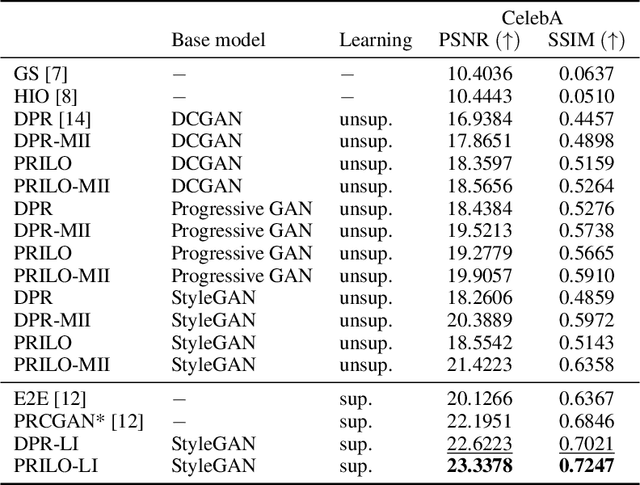

Phase retrieval is the problem of reconstructing images from magnitude-only measurements. In many real-world applications the problem is underdetermined. When training data is available, generative models are a new idea to constrain the solution set. However, not all possible solutions are within the range of the generator. Instead, they are represented with some error. To reduce this representation error in the context of phase retrieval, we first leverage a novel variation of intermediate layer optimization (ILO) to extend the range of the generator while still producing images consistent with the training data. Second, we introduce new initialization schemes that further improve the quality of the reconstruction. With extensive experiments on Fourier and Gaussian phase retrieval problems and thorough ablation studies, we can show the benefits of our modified ILO and the new initialization schemes.
Deblurring Photographs of Characters Using Deep Neural Networks
May 31, 2022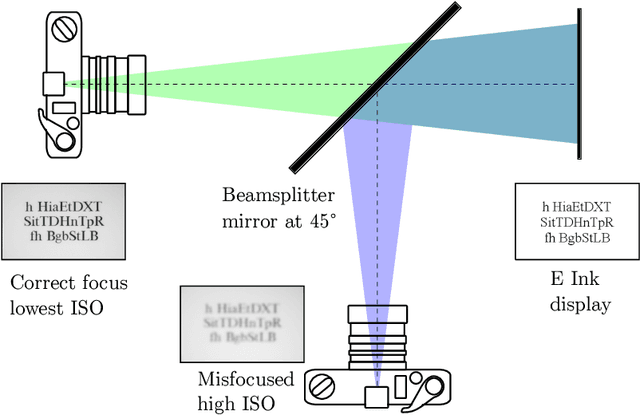
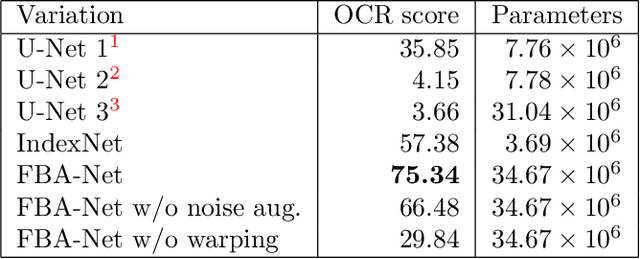

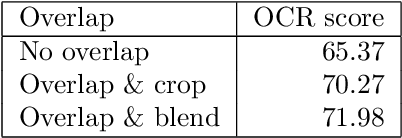
In this paper, we present our approach for the Helsinki Deblur Challenge (HDC2021). The task of this challenge is to deblur images of characters without knowing the point spread function (PSF). The organizers provided a dataset of pairs of sharp and blurred images. Our method consists of three steps: First, we estimate a warping transformation of the images to align the sharp images with the blurred ones. Next, we estimate the PSF using a quasi-Newton method. The estimated PSF allows to generate additional pairs of sharp and blurred images. Finally, we train a deep convolutional neural network to reconstruct the sharp images from the blurred images. Our method is able to successfully reconstruct images from the first 10 stages of the HDC 2021 data. Our code is available at https://github.com/hhu-machine-learning/hdc2021-psfnn.
A Closer Look at Reference Learning for Fourier Phase Retrieval
Oct 26, 2021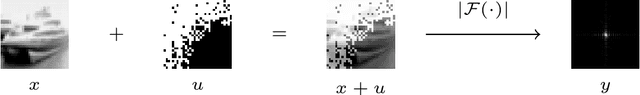
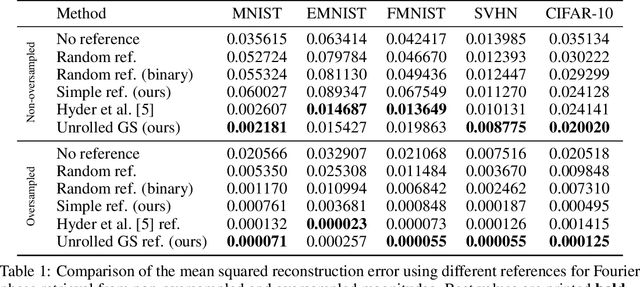

Reconstructing images from their Fourier magnitude measurements is a problem that often arises in different research areas. This process is also referred to as phase retrieval. In this work, we consider a modified version of the phase retrieval problem, which allows for a reference image to be added onto the image before the Fourier magnitudes are measured. We analyze an unrolled Gerchberg-Saxton (GS) algorithm that can be used to learn a good reference image from a dataset. Furthermore, we take a closer look at the learned reference images and propose a simple and efficient heuristic to construct reference images that, in some cases, yields reconstructions of comparable quality as approaches that learn references. Our code is available at https://github.com/tuelwer/reference-learning.
Learning to Detect Adversarial Examples Based on Class Scores
Jul 09, 2021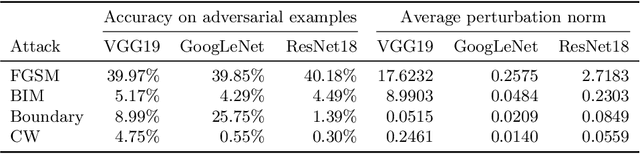

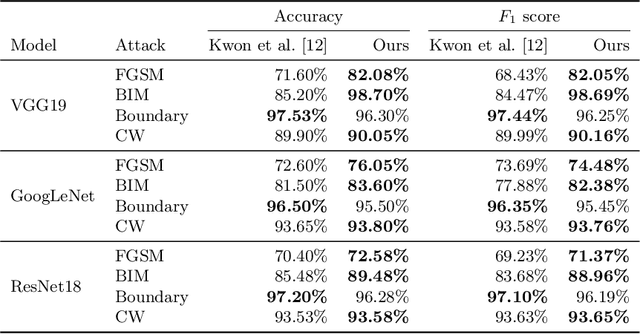
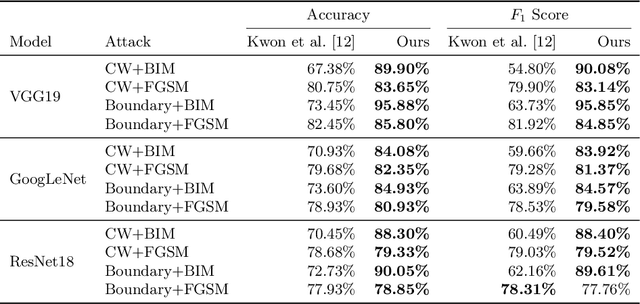
Given the increasing threat of adversarial attacks on deep neural networks (DNNs), research on efficient detection methods is more important than ever. In this work, we take a closer look at adversarial attack detection based on the class scores of an already trained classification model. We propose to train a support vector machine (SVM) on the class scores to detect adversarial examples. Our method is able to detect adversarial examples generated by various attacks, and can be easily adopted to a plethora of deep classification models. We show that our approach yields an improved detection rate compared to an existing method, whilst being easy to implement. We perform an extensive empirical analysis on different deep classification models, investigating various state-of-the-art adversarial attacks. Moreover, we observe that our proposed method is better at detecting a combination of adversarial attacks. This work indicates the potential of detecting various adversarial attacks simply by using the class scores of an already trained classification model.
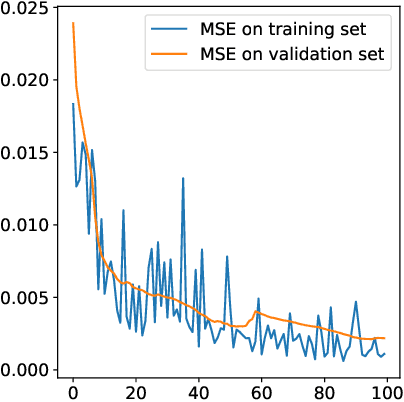
Non-Iterative Phase Retrieval With Cascaded Neural Networks
Jun 18, 2021
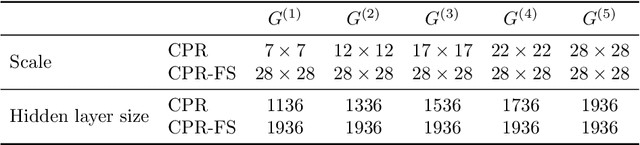

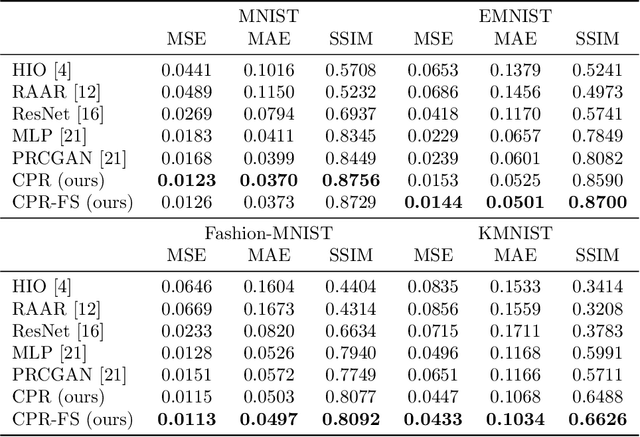
Fourier phase retrieval is the problem of reconstructing a signal given only the magnitude of its Fourier transformation. Optimization-based approaches, like the well-established Gerchberg-Saxton or the hybrid input output algorithm, struggle at reconstructing images from magnitudes that are not oversampled. This motivates the application of learned methods, which allow reconstruction from non-oversampled magnitude measurements after a learning phase. In this paper, we want to push the limits of these learned methods by means of a deep neural network cascade that reconstructs the image successively on different resolutions from its non-oversampled Fourier magnitude. We evaluate our method on four different datasets (MNIST, EMNIST, Fashion-MNIST, and KMNIST) and demonstrate that it yields improved performance over other non-iterative methods and optimization-based methods.
Learning to Plan via a Multi-Step Policy Regression Method
Jun 18, 2021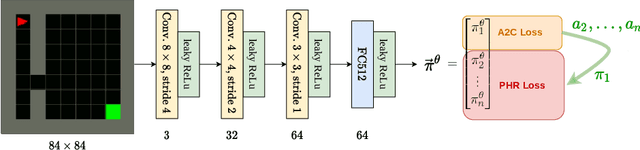
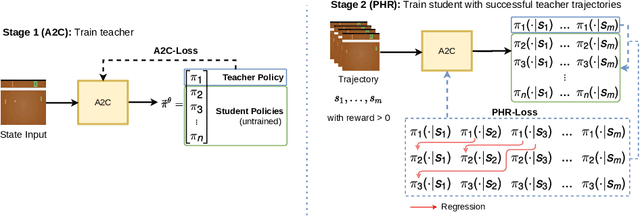

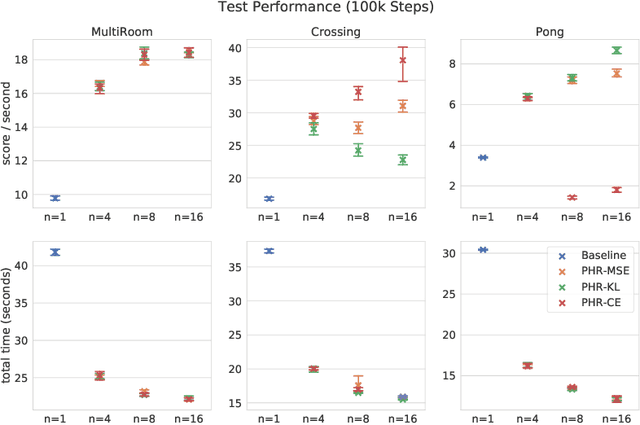
We propose a new approach to increase inference performance in environments that require a specific sequence of actions in order to be solved. This is for example the case for maze environments where ideally an optimal path is determined. Instead of learning a policy for a single step, we want to learn a policy that can predict n actions in advance. Our proposed method called policy horizon regression (PHR) uses knowledge of the environment sampled by A2C to learn an n dimensional policy vector in a policy distillation setup which yields n sequential actions per observation. We test our method on the MiniGrid and Pong environments and show drastic speedup during inference time by successfully predicting sequences of actions on a single observation.
Discrete Latent Space World Models for Reinforcement Learning
Oct 12, 2020

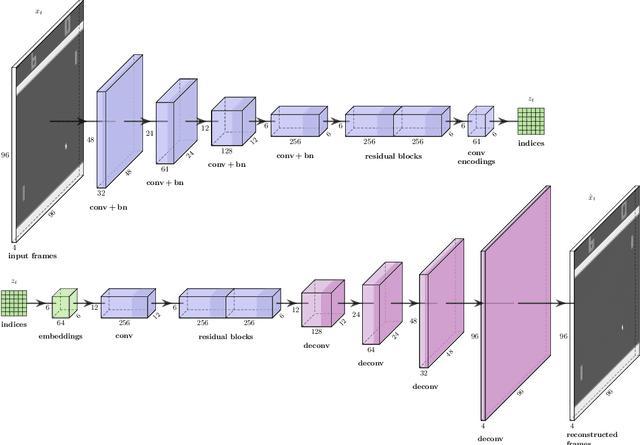

Sample efficiency remains a fundamental issue of reinforcement learning. Model-based algorithms try to make better use of data by simulating the environment with a model. We propose a new neural network architecture for world models based on a vector quantized-variational autoencoder (VQ-VAE) to encode observations and a convolutional LSTM to predict the next embedding indices. A model-free PPO agent is trained purely on simulated experience from the world model. We adopt the setup introduced by Kaiser et al. (2020), which only allows 100K interactions with the real environment, and show that we reach better performance than their SimPLe algorithm in five out of six randomly selected Atari environments, while our model is significantly smaller.