 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackward Learning for Goal-Conditioned Policies
Dec 08, 2023Can we learn policies in reinforcement learning without rewards? Can we learn a policy just by trying to reach a goal state? We answer these questions positively by proposing a multi-step procedure that first learns a world model that goes backward in time, secondly generates goal-reaching backward trajectories, thirdly improves those sequences using shortest path finding algorithms, and finally trains a neural network policy by imitation learning. We evaluate our method on a deterministic maze environment where the observations are $64\times 64$ pixel bird's eye images and can show that it consistently reaches several goals.
Limited-Angle Tomography Reconstruction via Deep End-To-End Learning on Synthetic Data
Sep 13, 2023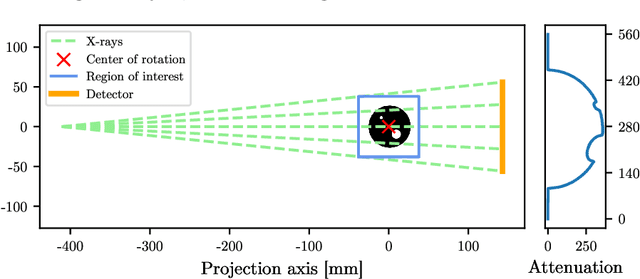

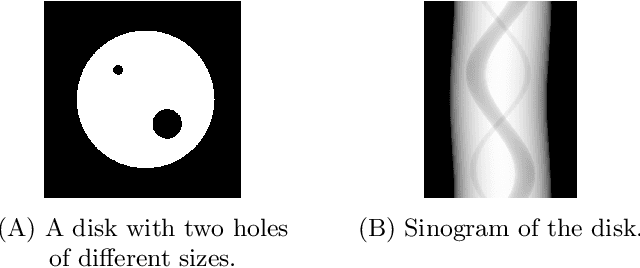
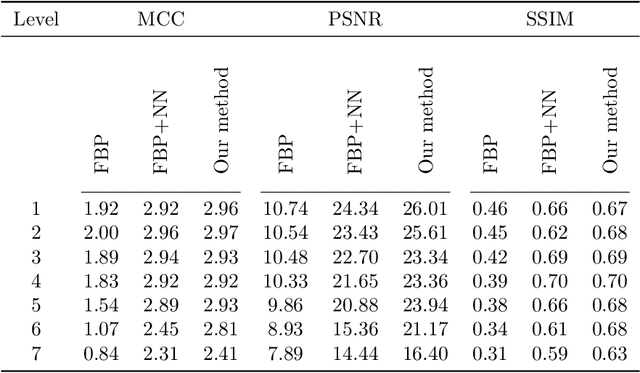
Computed tomography (CT) has become an essential part of modern science and medicine. A CT scanner consists of an X-ray source that is spun around an object of interest. On the opposite end of the X-ray source, a detector captures X-rays that are not absorbed by the object. The reconstruction of an image is a linear inverse problem, which is usually solved by filtered back projection. However, when the number of measurements is small, the reconstruction problem is ill-posed. This is for example the case when the X-ray source is not spun completely around the object, but rather irradiates the object only from a limited angle. To tackle this problem, we present a deep neural network that is trained on a large amount of carefully-crafted synthetic data and can perform limited-angle tomography reconstruction even for only 30{\deg} or 40{\deg} sinograms. With our approach we won the first place in the Helsinki Tomography Challenge 2022.
Cyclophobic Reinforcement Learning
Aug 30, 2023In environments with sparse rewards, finding a good inductive bias for exploration is crucial to the agent's success. However, there are two competing goals: novelty search and systematic exploration. While existing approaches such as curiosity-driven exploration find novelty, they sometimes do not systematically explore the whole state space, akin to depth-first-search vs breadth-first-search. In this paper, we propose a new intrinsic reward that is cyclophobic, i.e., it does not reward novelty, but punishes redundancy by avoiding cycles. Augmenting the cyclophobic intrinsic reward with a sequence of hierarchical representations based on the agent's cropped observations we are able to achieve excellent results in the MiniGrid and MiniHack environments. Both are particularly hard, as they require complex interactions with different objects in order to be solved. Detailed comparisons with previous approaches and thorough ablation studies show that our newly proposed cyclophobic reinforcement learning is more sample efficient than other state of the art methods in a variety of tasks.
A Survey on Self-Supervised Representation Learning
Aug 22, 2023

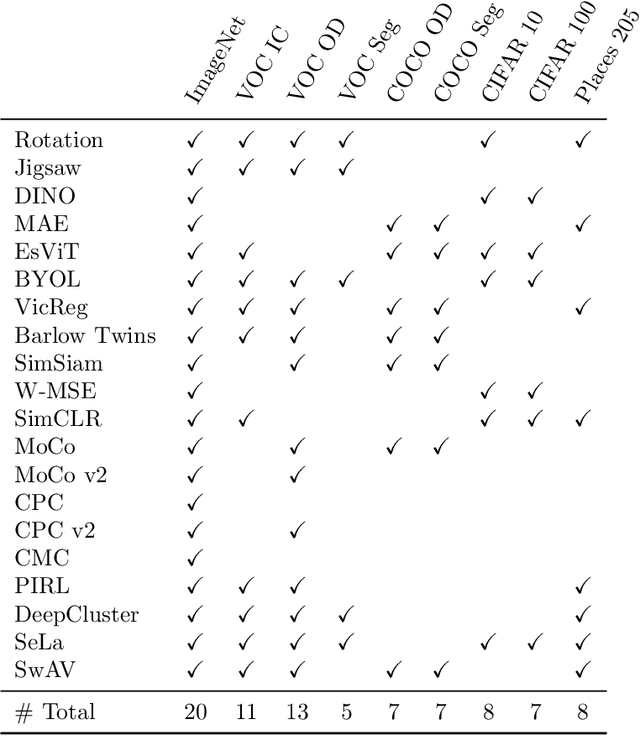
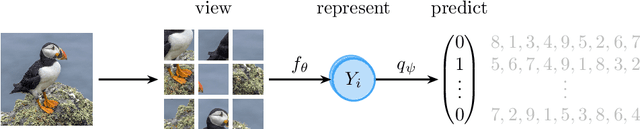
Learning meaningful representations is at the heart of many tasks in the field of modern machine learning. Recently, a lot of methods were introduced that allow learning of image representations without supervision. These representations can then be used in downstream tasks like classification or object detection. The quality of these representations is close to supervised learning, while no labeled images are needed. This survey paper provides a comprehensive review of these methods in a unified notation, points out similarities and differences of these methods, and proposes a taxonomy which sets these methods in relation to each other. Furthermore, our survey summarizes the most-recent experimental results reported in the literature in form of a meta-study. Our survey is intended as a starting point for researchers and practitioners who want to dive into the field of representation learning.
Transformer-based World Models Are Happy With 100k Interactions
Mar 13, 2023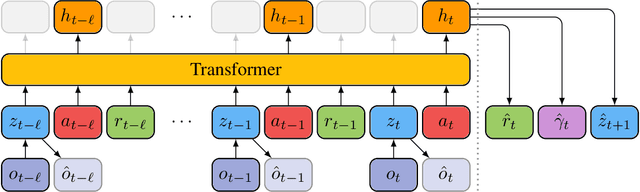
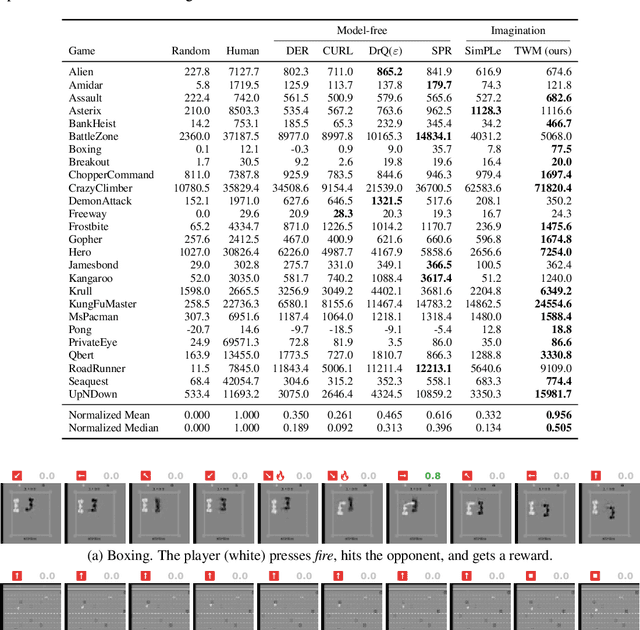
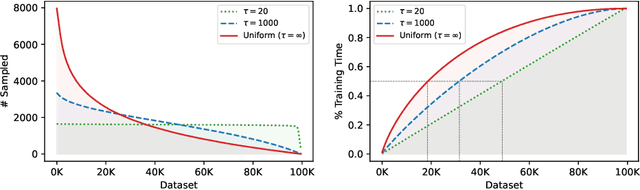
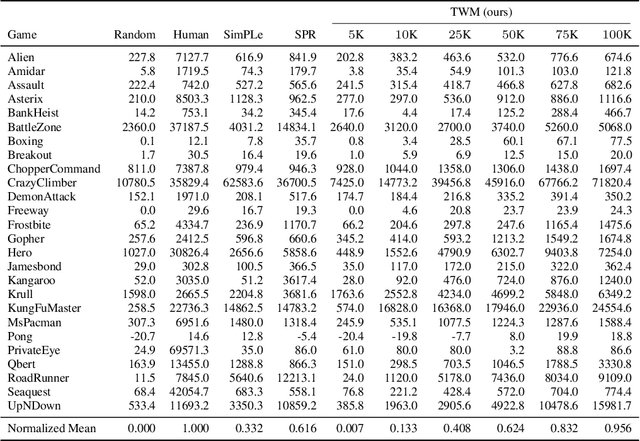
Deep neural networks have been successful in many reinforcement learning settings. However, compared to human learners they are overly data hungry. To build a sample-efficient world model, we apply a transformer to real-world episodes in an autoregressive manner: not only the compact latent states and the taken actions but also the experienced or predicted rewards are fed into the transformer, so that it can attend flexibly to all three modalities at different time steps. The transformer allows our world model to access previous states directly, instead of viewing them through a compressed recurrent state. By utilizing the Transformer-XL architecture, it is able to learn long-term dependencies while staying computationally efficient. Our transformer-based world model (TWM) generates meaningful, new experience, which is used to train a policy that outperforms previous model-free and model-based reinforcement learning algorithms on the Atari 100k benchmark.
Time-Myopic Go-Explore: Learning A State Representation for the Go-Explore Paradigm
Jan 13, 2023

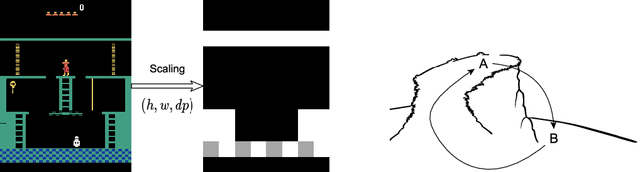
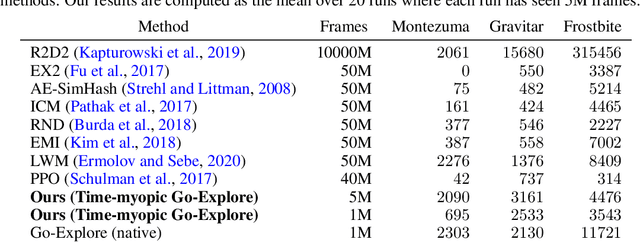
Very large state spaces with a sparse reward signal are difficult to explore. The lack of a sophisticated guidance results in a poor performance for numerous reinforcement learning algorithms. In these cases, the commonly used random exploration is often not helpful. The literature shows that this kind of environments require enormous efforts to systematically explore large chunks of the state space. Learned state representations can help here to improve the search by providing semantic context and build a structure on top of the raw observations. In this work we introduce a novel time-myopic state representation that clusters temporal close states together while providing a time prediction capability between them. By adapting this model to the Go-Explore paradigm (Ecoffet et al., 2021b), we demonstrate the first learned state representation that reliably estimates novelty instead of using the hand-crafted representation heuristic. Our method shows an improved solution for the detachment problem which still remains an issue at the Go-Explore Exploration Phase. We provide evidence that our proposed method covers the entire state space with respect to all possible time trajectories without causing disadvantageous conflict-overlaps in the cell archive. Analogous to native Go-Explore, our approach is evaluated on the hard exploration environments MontezumaRevenge, Gravitar and Frostbite (Atari) in order to validate its capabilities on difficult tasks. Our experiments show that time-myopic Go-Explore is an effective alternative for the domain-engineered heuristic while also being more general. The source code of the method is available on GitHub.
Discrete Latent Space World Models for Reinforcement Learning
Oct 12, 2020

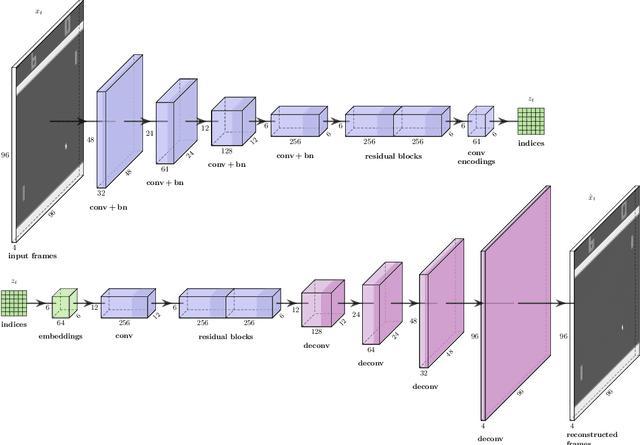

Sample efficiency remains a fundamental issue of reinforcement learning. Model-based algorithms try to make better use of data by simulating the environment with a model. We propose a new neural network architecture for world models based on a vector quantized-variational autoencoder (VQ-VAE) to encode observations and a convolutional LSTM to predict the next embedding indices. A model-free PPO agent is trained purely on simulated experience from the world model. We adopt the setup introduced by Kaiser et al. (2020), which only allows 100K interactions with the real environment, and show that we reach better performance than their SimPLe algorithm in five out of six randomly selected Atari environments, while our model is significantly smaller.