 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaxPoolBERT: Enhancing BERT Classification via Layer- and Token-Wise Aggregation
May 21, 2025The [CLS] token in BERT is commonly used as a fixed-length representation for classification tasks, yet prior work has shown that both other tokens and intermediate layers encode valuable contextual information. In this work, we propose MaxPoolBERT, a lightweight extension to BERT that refines the [CLS] representation by aggregating information across layers and tokens. Specifically, we explore three modifications: (i) max-pooling the [CLS] token across multiple layers, (ii) enabling the [CLS] token to attend over the entire final layer using an additional multi-head attention (MHA) layer, and (iii) combining max-pooling across the full sequence with MHA. Our approach enhances BERT's classification accuracy (especially on low-resource tasks) without requiring pre-training or significantly increasing model size. Experiments on the GLUE benchmark show that MaxPoolBERT consistently achieves a better performance on the standard BERT-base model.
Object-Aware DINO (Oh-A-Dino): Enhancing Self-Supervised Representations for Multi-Object Instance Retrieval
Mar 12, 2025Object-centric learning is fundamental to human vision and crucial for models requiring complex reasoning. Traditional approaches rely on slot-based bottlenecks to learn object properties explicitly, while recent self-supervised vision models like DINO have shown emergent object understanding. However, DINO representations primarily capture global scene features, often confounding individual object attributes. We investigate the effectiveness of DINO representations and slot-based methods for multi-object instance retrieval. Our findings reveal that DINO representations excel at capturing global object attributes such as object shape and size, but struggle with object-level details like colour, whereas slot-based representations struggle at both global and object-level understanding. To address this, we propose a method that combines global and local features by augmenting DINO representations with object-centric latent vectors from a Variational Autoencoder trained on segmented image patches that are extracted from the DINO features. This approach improves multi-object instance retrieval performance, bridging the gap between global scene understanding and fine-grained object representation without requiring full model retraining.
Supporting Online Discussions: Integrating AI Into the adhocracy+ Participation Platform To Enhance Deliberation
Sep 12, 2024Online spaces allow people to discuss important issues and make joint decisions, regardless of their location or time zone. However, without proper support and thoughtful design, these discussions often lack structure and politeness during the exchanges of opinions. Artificial intelligence (AI) represents an opportunity to support both participants and organizers of large-scale online participation processes. In this paper, we present an extension of adhocracy+, a large-scale open source participation platform, that provides two additional debate modules that are supported by AI to enhance the discussion quality and participant interaction.
The Power of LLM-Generated Synthetic Data for Stance Detection in Online Political Discussions
Jun 18, 2024Stance detection holds great potential for enhancing the quality of online political discussions, as it has shown to be useful for summarizing discussions, detecting misinformation, and evaluating opinion distributions. Usually, transformer-based models are used directly for stance detection, which require large amounts of data. However, the broad range of debate questions in online political discussion creates a variety of possible scenarios that the model is faced with and thus makes data acquisition for model training difficult. In this work, we show how to leverage LLM-generated synthetic data to train and improve stance detection agents for online political discussions:(i) We generate synthetic data for specific debate questions by prompting a Mistral-7B model and show that fine-tuning with the generated synthetic data can substantially improve the performance of stance detection. (ii) We examine the impact of combining synthetic data with the most informative samples from an unlabelled dataset. First, we use the synthetic data to select the most informative samples, second, we combine both these samples and the synthetic data for fine-tuning. This approach reduces labelling effort and consistently surpasses the performance of the baseline model that is trained with fully labeled data. Overall, we show in comprehensive experiments that LLM-generated data greatly improves stance detection performance for online political discussions.
SQBC: Active Learning using LLM-Generated Synthetic Data for Stance Detection in Online Political Discussions
Apr 11, 2024Stance detection is an important task for many applications that analyse or support online political discussions. Common approaches include fine-tuning transformer based models. However, these models require a large amount of labelled data, which might not be available. In this work, we present two different ways to leverage LLM-generated synthetic data to train and improve stance detection agents for online political discussions: first, we show that augmenting a small fine-tuning dataset with synthetic data can improve the performance of the stance detection model. Second, we propose a new active learning method called SQBC based on the "Query-by-Comittee" approach. The key idea is to use LLM-generated synthetic data as an oracle to identify the most informative unlabelled samples, that are selected for manual labelling. Comprehensive experiments show that both ideas can improve the stance detection performance. Curiously, we observed that fine-tuning on actively selected samples can exceed the performance of using the full dataset.
AQuA -- Combining Experts' and Non-Experts' Views To Assess Deliberation Quality in Online Discussions Using LLMs
Apr 04, 2024Measuring the quality of contributions in political online discussions is crucial in deliberation research and computer science. Research has identified various indicators to assess online discussion quality, and with deep learning advancements, automating these measures has become feasible. While some studies focus on analyzing specific quality indicators, a comprehensive quality score incorporating various deliberative aspects is often preferred. In this work, we introduce AQuA, an additive score that calculates a unified deliberative quality score from multiple indices for each discussion post. Unlike other singular scores, AQuA preserves information on the deliberative aspects present in comments, enhancing model transparency. We develop adapter models for 20 deliberative indices, and calculate correlation coefficients between experts' annotations and the perceived deliberativeness by non-experts to weigh the individual indices into a single deliberative score. We demonstrate that the AQuA score can be computed easily from pre-trained adapters and aligns well with annotations on other datasets that have not be seen during training. The analysis of experts' vs. non-experts' annotations confirms theoretical findings in the social science literature.
Just Cluster It: An Approach for Exploration in High-Dimensions using Clustering and Pre-Trained Representations
Feb 05, 2024



In this paper we adopt a representation-centric perspective on exploration in reinforcement learning, viewing exploration fundamentally as a density estimation problem. We investigate the effectiveness of clustering representations for exploration in 3-D environments, based on the observation that the importance of pixel changes between transitions is less pronounced in 3-D environments compared to 2-D environments, where pixel changes between transitions are typically distinct and significant. We propose a method that performs episodic and global clustering on random representations and on pre-trained DINO representations to count states, i.e, estimate pseudo-counts. Surprisingly, even random features can be clustered effectively to count states in 3-D environments, however when these become visually more complex, pre-trained DINO representations are more effective thanks to the pre-trained inductive biases in the representations. Overall, this presents a pathway for integrating pre-trained biases into exploration. We evaluate our approach on the VizDoom and Habitat environments, demonstrating that our method surpasses other well-known exploration methods in these settings.
Backward Learning for Goal-Conditioned Policies
Dec 08, 2023Can we learn policies in reinforcement learning without rewards? Can we learn a policy just by trying to reach a goal state? We answer these questions positively by proposing a multi-step procedure that first learns a world model that goes backward in time, secondly generates goal-reaching backward trajectories, thirdly improves those sequences using shortest path finding algorithms, and finally trains a neural network policy by imitation learning. We evaluate our method on a deterministic maze environment where the observations are $64\times 64$ pixel bird's eye images and can show that it consistently reaches several goals.
Limited-Angle Tomography Reconstruction via Deep End-To-End Learning on Synthetic Data
Sep 13, 2023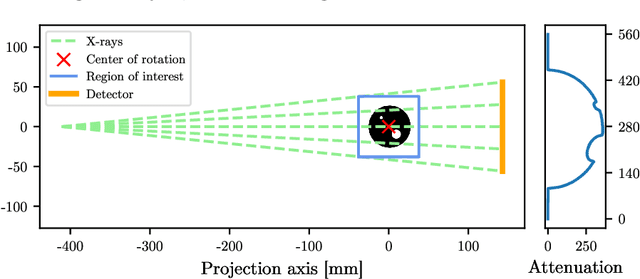

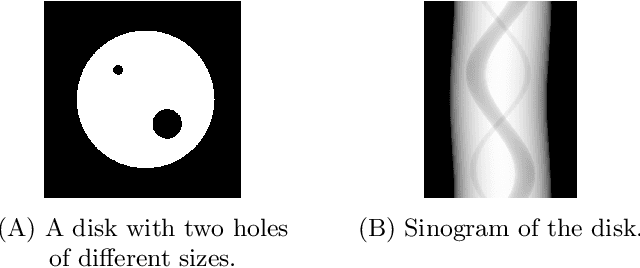
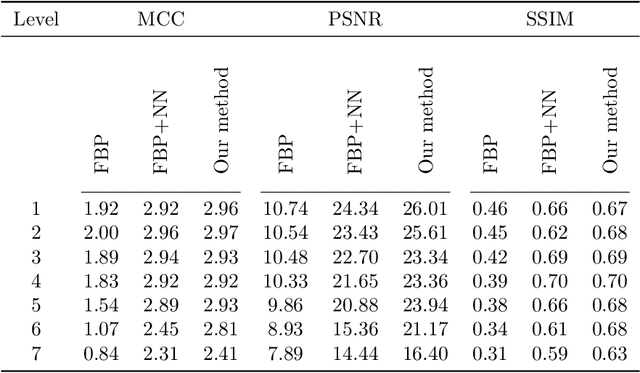
Computed tomography (CT) has become an essential part of modern science and medicine. A CT scanner consists of an X-ray source that is spun around an object of interest. On the opposite end of the X-ray source, a detector captures X-rays that are not absorbed by the object. The reconstruction of an image is a linear inverse problem, which is usually solved by filtered back projection. However, when the number of measurements is small, the reconstruction problem is ill-posed. This is for example the case when the X-ray source is not spun completely around the object, but rather irradiates the object only from a limited angle. To tackle this problem, we present a deep neural network that is trained on a large amount of carefully-crafted synthetic data and can perform limited-angle tomography reconstruction even for only 30{\deg} or 40{\deg} sinograms. With our approach we won the first place in the Helsinki Tomography Challenge 2022.
Cyclophobic Reinforcement Learning
Aug 30, 2023In environments with sparse rewards, finding a good inductive bias for exploration is crucial to the agent's success. However, there are two competing goals: novelty search and systematic exploration. While existing approaches such as curiosity-driven exploration find novelty, they sometimes do not systematically explore the whole state space, akin to depth-first-search vs breadth-first-search. In this paper, we propose a new intrinsic reward that is cyclophobic, i.e., it does not reward novelty, but punishes redundancy by avoiding cycles. Augmenting the cyclophobic intrinsic reward with a sequence of hierarchical representations based on the agent's cropped observations we are able to achieve excellent results in the MiniGrid and MiniHack environments. Both are particularly hard, as they require complex interactions with different objects in order to be solved. Detailed comparisons with previous approaches and thorough ablation studies show that our newly proposed cyclophobic reinforcement learning is more sample efficient than other state of the art methods in a variety of tasks.