 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Few Hypocrites: Few-Shot Learning and Subtype Definitions for Detecting Hypocrisy Accusations in Online Climate Change Debates
Sep 25, 2024



The climate crisis is a salient issue in online discussions, and hypocrisy accusations are a central rhetorical element in these debates. However, for large-scale text analysis, hypocrisy accusation detection is an understudied tool, most often defined as a smaller subtask of fallacious argument detection. In this paper, we define hypocrisy accusation detection as an independent task in NLP, and identify different relevant subtypes of hypocrisy accusations. Our Climate Hypocrisy Accusation Corpus (CHAC) consists of 420 Reddit climate debate comments, expert-annotated into two different types of hypocrisy accusations: personal versus political hypocrisy. We evaluate few-shot in-context learning with 6 shots and 3 instruction-tuned Large Language Models (LLMs) for detecting hypocrisy accusations in this dataset. Results indicate that the GPT-4o and Llama-3 models in particular show promise in detecting hypocrisy accusations (F1 reaching 0.68, while previous work shows F1 of 0.44). However, context matters for a complex semantic concept such as hypocrisy accusations, and we find models struggle especially at identifying political hypocrisy accusations compared to personal moral hypocrisy. Our study contributes new insights in hypocrisy detection and climate change discourse, and is a stepping stone for large-scale analysis of hypocrisy accusation in online climate debates.
AQuA -- Combining Experts' and Non-Experts' Views To Assess Deliberation Quality in Online Discussions Using LLMs
Apr 04, 2024Measuring the quality of contributions in political online discussions is crucial in deliberation research and computer science. Research has identified various indicators to assess online discussion quality, and with deep learning advancements, automating these measures has become feasible. While some studies focus on analyzing specific quality indicators, a comprehensive quality score incorporating various deliberative aspects is often preferred. In this work, we introduce AQuA, an additive score that calculates a unified deliberative quality score from multiple indices for each discussion post. Unlike other singular scores, AQuA preserves information on the deliberative aspects present in comments, enhancing model transparency. We develop adapter models for 20 deliberative indices, and calculate correlation coefficients between experts' annotations and the perceived deliberativeness by non-experts to weigh the individual indices into a single deliberative score. We demonstrate that the AQuA score can be computed easily from pre-trained adapters and aligns well with annotations on other datasets that have not be seen during training. The analysis of experts' vs. non-experts' annotations confirms theoretical findings in the social science literature.
Compensating data shortages in manufacturing with monotonicity knowledge
Oct 29, 2020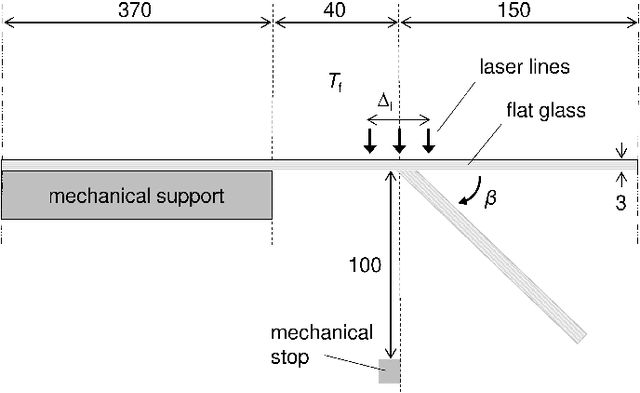

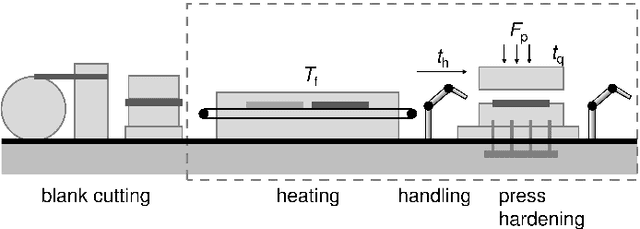
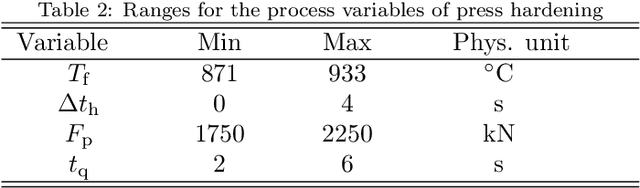
We present a regression method for enhancing the predictive power of a model by exploiting expert knowledge in the form of shape constraints, or more specifically, monotonicity constraints. Incorporating such information is particularly useful when the available data sets are small or do not cover the entire input space, as is often the case in manufacturing applications. We set up the regression subject to the considered monotonicity constraints as a semi-infinite optimization problem, and we propose an adaptive solution algorithm. The method is conceptually simple, applicable in multiple dimensions and can be extended to more general shape constraints. It is tested and validated on two real-world manufacturing processes, namely laser glass bending and press hardening of sheet metal. It is found that the resulting models both comply well with the expert's monotonicity knowledge and predict the training data accurately. The suggested approach leads to lower root-mean-squared errors than comparative methods from the literature for the sparse data sets considered in this work.
Machine Learning for Material Characterization with an Application for Predicting Mechanical Properties
Oct 12, 2020
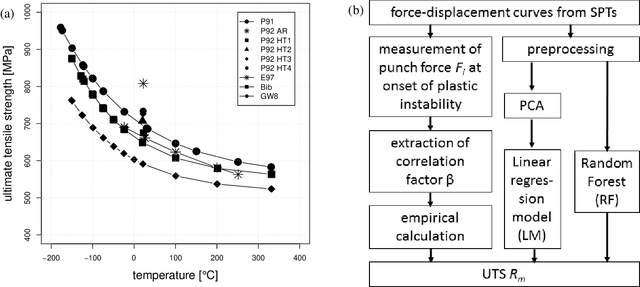
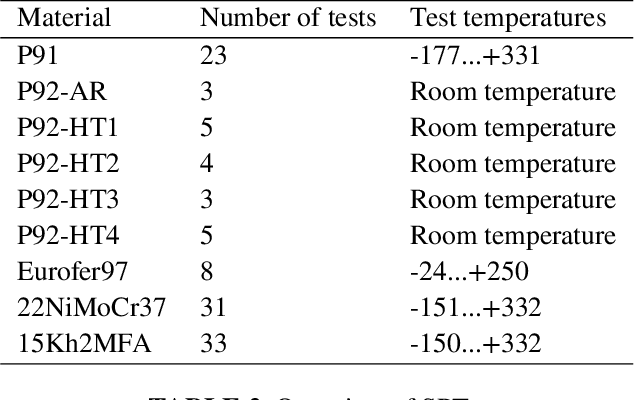
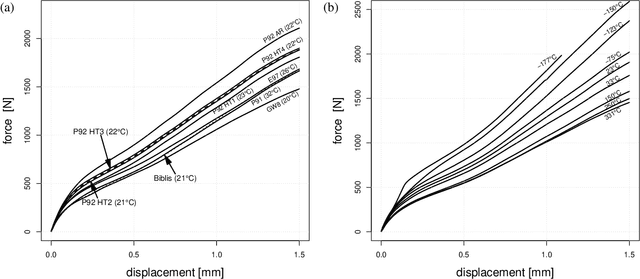
Currently, the growth of material data from experiments and simulations is expanding beyond processable amounts. This makes the development of new data-driven methods for the discovery of patterns among multiple lengthscales and time-scales and structure-property relationships essential. These data-driven approaches show enormous promise within materials science. The following review covers machine learning applications for metallic material characterization. Many parameters associated with the processing and the structure of materials affect the properties and the performance of manufactured components. Thus, this study is an attempt to investigate the usefulness of machine learning methods for material property prediction. Material characteristics such as strength, toughness, hardness, brittleness or ductility are relevant to categorize a material or component according to their quality. In industry, material tests like tensile tests, compression tests or creep tests are often time consuming and expensive to perform. Therefore, the application of machine learning approaches is considered helpful for an easier generation of material property information. This study also gives an application of machine learning methods on small punch test data for the determination of the property ultimate tensile strength for various materials. A strong correlation between small punch test data and tensile test data was found which ultimately allows to replace more costly tests by simple and fast tests in combination with machine learning.