 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Few Hypocrites: Few-Shot Learning and Subtype Definitions for Detecting Hypocrisy Accusations in Online Climate Change Debates
Sep 25, 2024



The climate crisis is a salient issue in online discussions, and hypocrisy accusations are a central rhetorical element in these debates. However, for large-scale text analysis, hypocrisy accusation detection is an understudied tool, most often defined as a smaller subtask of fallacious argument detection. In this paper, we define hypocrisy accusation detection as an independent task in NLP, and identify different relevant subtypes of hypocrisy accusations. Our Climate Hypocrisy Accusation Corpus (CHAC) consists of 420 Reddit climate debate comments, expert-annotated into two different types of hypocrisy accusations: personal versus political hypocrisy. We evaluate few-shot in-context learning with 6 shots and 3 instruction-tuned Large Language Models (LLMs) for detecting hypocrisy accusations in this dataset. Results indicate that the GPT-4o and Llama-3 models in particular show promise in detecting hypocrisy accusations (F1 reaching 0.68, while previous work shows F1 of 0.44). However, context matters for a complex semantic concept such as hypocrisy accusations, and we find models struggle especially at identifying political hypocrisy accusations compared to personal moral hypocrisy. Our study contributes new insights in hypocrisy detection and climate change discourse, and is a stepping stone for large-scale analysis of hypocrisy accusation in online climate debates.
On the Verge of Solving Rocket League using Deep Reinforcement Learning and Sim-to-sim Transfer
May 24, 2022
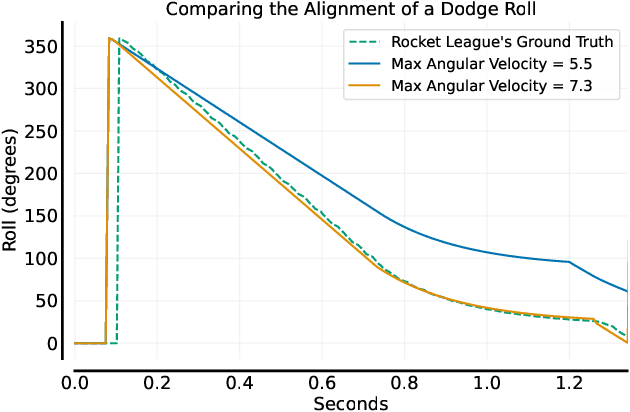
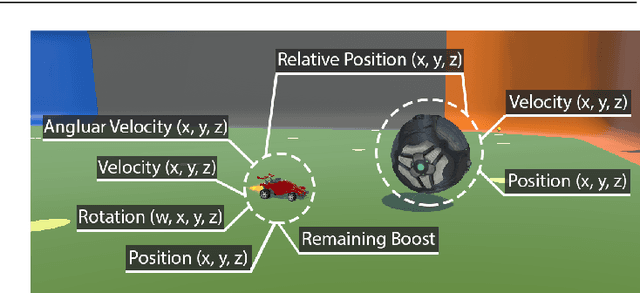
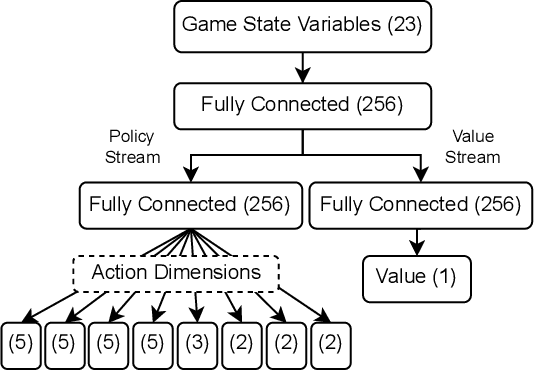
Autonomously trained agents that are supposed to play video games reasonably well rely either on fast simulation speeds or heavy parallelization across thousands of machines running concurrently. This work explores a third way that is established in robotics, namely sim-to-real transfer, or if the game is considered a simulation itself, sim-to-sim transfer. In the case of Rocket League, we demonstrate that single behaviors of goalies and strikers can be successfully learned using Deep Reinforcement Learning in the simulation environment and transferred back to the original game. Although the implemented training simulation is to some extent inaccurate, the goalkeeping agent saves nearly 100% of its faced shots once transferred, while the striking agent scores in about 75% of cases. Therefore, the trained agent is robust enough and able to generalize to the target domain of Rocket League.