 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Plan via a Multi-Step Policy Regression Method
Jun 18, 2021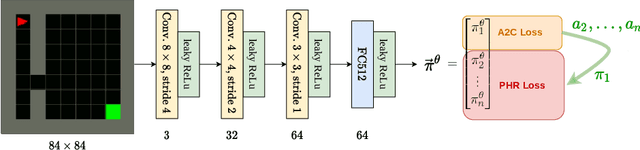
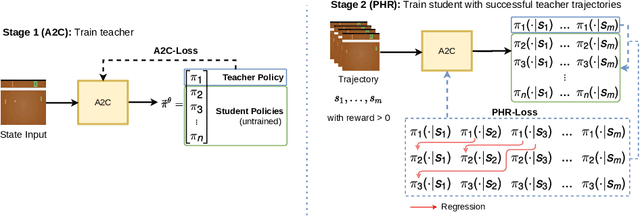

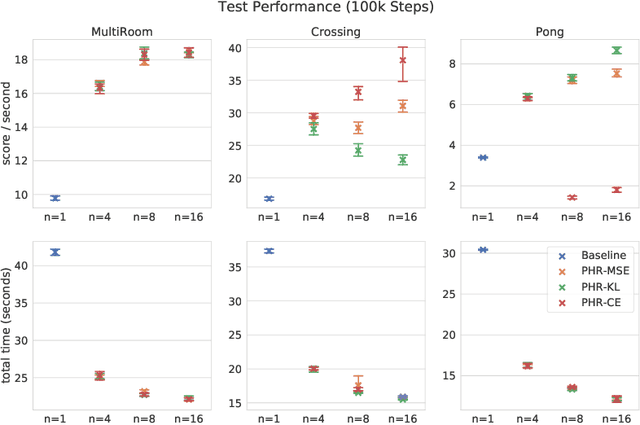
We propose a new approach to increase inference performance in environments that require a specific sequence of actions in order to be solved. This is for example the case for maze environments where ideally an optimal path is determined. Instead of learning a policy for a single step, we want to learn a policy that can predict n actions in advance. Our proposed method called policy horizon regression (PHR) uses knowledge of the environment sampled by A2C to learn an n dimensional policy vector in a policy distillation setup which yields n sequential actions per observation. We test our method on the MiniGrid and Pong environments and show drastic speedup during inference time by successfully predicting sequences of actions on a single observation.