 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Estimation of Tree Volume and Aboveground Biomass Using Deep Regression with Synthetic Lidar Data
Mar 04, 2026Accurate estimation of forest biomass is crucial for monitoring carbon sequestration and informing climate change mitigation strategies. Existing methods often rely on allometric models, which estimate individual tree biomass by relating it to measurable biophysical parameters, e.g., trunk diameter and height. This indirect approach is limited in accuracy due to measurement uncertainties and the inherently approximate nature of allometric equations, which may not fully account for the variability in tree characteristics and forest conditions. This study proposes a direct approach that leverages synthetic point cloud data to train a deep regression network, which is then applied to real point clouds for plot-level wood volume and aboveground biomass (AGB) estimation. We created synthetic 3D forest plots with ground truth volume, which were then converted into point cloud data using a lidar simulator. These point clouds were subsequently used to train deep regression networks based on PointNet, PointNet++, DGCNN, and PointConv. When applied to synthetic data, the deep regression networks achieved mean absolute percentage error (MAPE) values ranging from 1.69% to 8.11%. The trained networks were then applied to real lidar data to estimate volume and AGB. When compared against field measurements, our direct approach showed discrepancies of 2% to 20%. In contrast, indirect approaches based on individual tree segmentation followed by allometric conversion, as well as FullCAM, exhibited substantially large underestimation, with discrepancies ranging from 27% to 85%. Our results highlight the potential of integrating synthetic data with deep learning for efficient and scalable forest carbon estimation at plot level.
Relative Energy Learning for LiDAR Out-of-Distribution Detection
Nov 11, 2025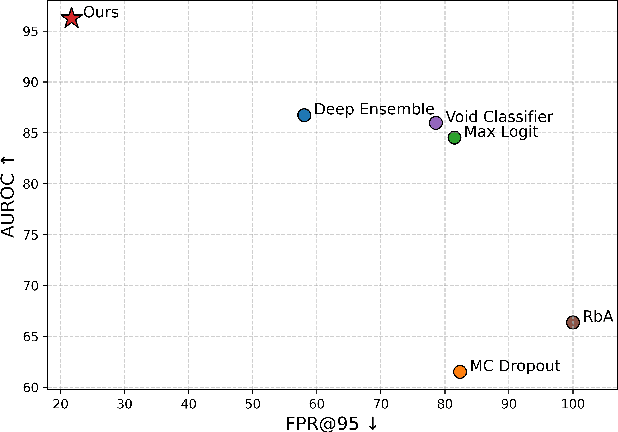
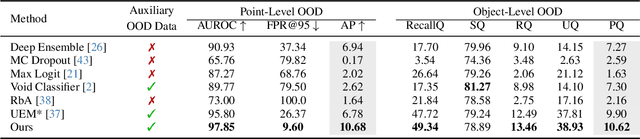
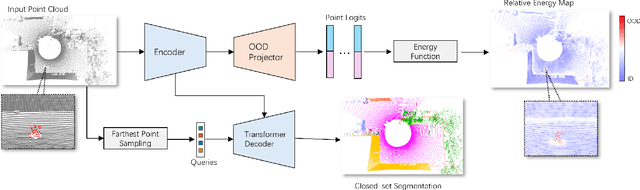

Out-of-distribution (OOD) detection is a critical requirement for reliable autonomous driving, where safety depends on recognizing road obstacles and unexpected objects beyond the training distribution. Despite extensive research on OOD detection in 2D images, direct transfer to 3D LiDAR point clouds has been proven ineffective. Current LiDAR OOD methods struggle to distinguish rare anomalies from common classes, leading to high false-positive rates and overconfident errors in safety-critical settings. We propose Relative Energy Learning (REL), a simple yet effective framework for OOD detection in LiDAR point clouds. REL leverages the energy gap between positive (in-distribution) and negative logits as a relative scoring function, mitigating calibration issues in raw energy values and improving robustness across various scenes. To address the absence of OOD samples during training, we propose a lightweight data synthesis strategy called Point Raise, which perturbs existing point clouds to generate auxiliary anomalies without altering the inlier semantics. Evaluated on SemanticKITTI and the Spotting the Unexpected (STU) benchmark, REL consistently outperforms existing methods by a large margin. Our results highlight that modeling relative energy, combined with simple synthetic outliers, provides a principled and scalable solution for reliable OOD detection in open-world autonomous driving.
Surfel-based 3D Registration with Equivariant SE(3) Features
Aug 28, 2025Point cloud registration is crucial for ensuring 3D alignment consistency of multiple local point clouds in 3D reconstruction for remote sensing or digital heritage. While various point cloud-based registration methods exist, both non-learning and learning-based, they ignore point orientations and point uncertainties, making the model susceptible to noisy input and aggressive rotations of the input point cloud like orthogonal transformation; thus, it necessitates extensive training point clouds with transformation augmentations. To address these issues, we propose a novel surfel-based pose learning regression approach. Our method can initialize surfels from Lidar point cloud using virtual perspective camera parameters, and learns explicit $\mathbf{SE(3)}$ equivariant features, including both position and rotation through $\mathbf{SE(3)}$ equivariant convolutional kernels to predict relative transformation between source and target scans. The model comprises an equivariant convolutional encoder, a cross-attention mechanism for similarity computation, a fully-connected decoder, and a non-linear Huber loss. Experimental results on indoor and outdoor datasets demonstrate our model superiority and robust performance on real point-cloud scans compared to state-of-the-art methods.
* 5 pages, 4 figures
From Open Vocabulary to Open World: Teaching Vision Language Models to Detect Novel Objects
Dec 01, 2024
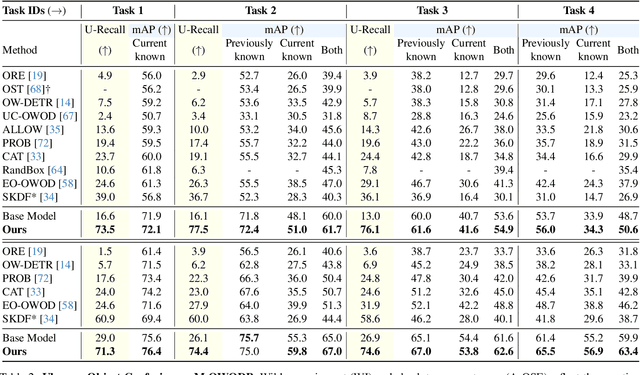
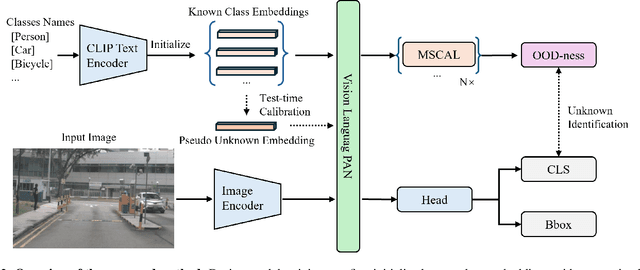

Traditional object detection methods operate under the closed-set assumption, where models can only detect a fixed number of objects predefined in the training set. Recent works on open vocabulary object detection (OVD) enable the detection of objects defined by an unbounded vocabulary, which reduces the cost of training models for specific tasks. However, OVD heavily relies on accurate prompts provided by an ''oracle'', which limits their use in critical applications such as driving scene perception. OVD models tend to misclassify near-out-of-distribution (NOOD) objects that have similar semantics to known classes, and ignore far-out-of-distribution (FOOD) objects. To address theses limitations, we propose a framework that enables OVD models to operate in open world settings, by identifying and incrementally learning novel objects. To detect FOOD objects, we propose Open World Embedding Learning (OWEL) and introduce the concept of Pseudo Unknown Embedding which infers the location of unknown classes in a continuous semantic space based on the information of known classes. We also propose Multi-Scale Contrastive Anchor Learning (MSCAL), which enables the identification of misclassified unknown objects by promoting the intra-class consistency of object embeddings at different scales. The proposed method achieves state-of-the-art performance in common open world object detection and autonomous driving benchmarks.
Equi-GSPR: Equivariant SE(3) Graph Network Model for Sparse Point Cloud Registration
Oct 08, 2024Point cloud registration is a foundational task for 3D alignment and reconstruction applications. While both traditional and learning-based registration approaches have succeeded, leveraging the intrinsic symmetry of point cloud data, including rotation equivariance, has received insufficient attention. This prohibits the model from learning effectively, resulting in a requirement for more training data and increased model complexity. To address these challenges, we propose a graph neural network model embedded with a local Spherical Euclidean 3D equivariance property through SE(3) message passing based propagation. Our model is composed mainly of a descriptor module, equivariant graph layers, match similarity, and the final regression layers. Such modular design enables us to utilize sparsely sampled input points and initialize the descriptor by self-trained or pre-trained geometric feature descriptors easily. Experiments conducted on the 3DMatch and KITTI datasets exhibit the compelling and robust performance of our model compared to state-of-the-art approaches, while the model complexity remains relatively low at the same time.
LMSeg: A deep graph message-passing network for efficient and accurate semantic segmentation of large-scale 3D landscape meshes
Jul 05, 2024



Semantic segmentation of large-scale 3D landscape meshes is pivotal for various geospatial applications, including spatial analysis, automatic mapping and localization of target objects, and urban planning and development. This requires an efficient and accurate 3D perception system to understand and analyze real-world environments. However, traditional mesh segmentation methods face challenges in accurately segmenting small objects and maintaining computational efficiency due to the complexity and large size of 3D landscape mesh datasets. This paper presents an end-to-end deep graph message-passing network, LMSeg, designed to efficiently and accurately perform semantic segmentation on large-scale 3D landscape meshes. The proposed approach takes the barycentric dual graph of meshes as inputs and applies deep message-passing neural networks to hierarchically capture the geometric and spatial features from the barycentric graph structures and learn intricate semantic information from textured meshes. The hierarchical and local pooling of the barycentric graph, along with the effective geometry aggregation modules of LMSeg, enable fast inference and accurate segmentation of small-sized and irregular mesh objects in various complex landscapes. Extensive experiments on two benchmark datasets (natural and urban landscapes) demonstrate that LMSeg significantly outperforms existing learning-based segmentation methods in terms of object segmentation accuracy and computational efficiency. Furthermore, our method exhibits strong generalization capabilities across diverse landscapes and demonstrates robust resilience against varying mesh densities and landscape topologies.
Learning Geometric Invariant Features for Classification of Vector Polygons with Graph Message-passing Neural Network
Jul 05, 2024



Geometric shape classification of vector polygons remains a non-trivial learning task in spatial analysis. Previous studies mainly focus on devising deep learning approaches for representation learning of rasterized vector polygons, whereas the study of discrete representations of polygons and subsequent deep learning approaches have not been fully investigated. In this study, we investigate a graph representation of vector polygons and propose a novel graph message-passing neural network (PolyMP) to learn the geometric-invariant features for shape classification of polygons. Through extensive experiments, we show that the graph representation of polygons combined with a permutation-invariant graph message-passing neural network achieves highly robust performances on benchmark datasets (i.e., synthetic glyph and real-world building footprint datasets) as compared to baseline methods. We demonstrate that the proposed graph-based PolyMP network enables the learning of expressive geometric features invariant to geometric transformations of polygons (i.e., translation, rotation, scaling and shearing) and is robust to trivial vertex removals of polygons. We further show the strong generalizability of PolyMP, which enables generalizing the learned geometric features from the synthetic glyph polygons to the real-world building footprints.
Centimeter-level Positioning by Instantaneous Lidar-aided GNSS Ambiguity Resolution
Apr 26, 2022



High-precision vehicle positioning is key to the implementation of modern driving systems in urban environments. Global Navigation Satellite System (GNSS) carrier phase measurements can provide millimeter- to centimeter-level positioning, provided that the integer ambiguities are correctly resolved. Abundant code measurements are often used to facilitate integer ambiguity resolution (IAR), however, they suffer from signal blockage and multipath in urban canyons. In this contribution, a lidar-aided instantaneous ambiguity resolution method is proposed. Lidar measurements, in the form of 3D keypoints, are generated by a learning-based point cloud registration method using a pre-built HD map and integrated with GNSS observations in a mixed measurement model to produce precise float solutions, which in turn increase the ambiguity success rate. Closed-form expressions of the ambiguity variance matrix and the associated Ambiguity Dilution of Precision (ADOP) are developed to provide a priori evaluation of such lidar-aided ambiguity resolution performance. Both analytical and experimental results show that the proposed method enables successful instantaneous IAR with limited GNSS satellites and frequencies, leading to centimeter-level vehicle positioning.
Fast and Reliable WiFi Fingerprint Collection for Indoor Localization
Aug 01, 2020



Fingerprinting is a popular indoor localization technique since it can utilize existing infrastructures (e.g., access points). However, its site survey process is a labor-intensive and time-consuming task, which limits the application of such systems in practice. In this paper, motivated by the availability of advanced sensing capabilities in smartphones, we propose a fast and reliable fingerprint collection method to reduce the time and labor required for site survey. The proposed method uses a landmark graph-based method to automatically associate the collected fingerprints, which does not require active user participation. We will show that besides fast fingerprint data collection, the proposed method results in accurate location estimate compared to the state-of-the-art methods. Experimental results show that the proposed method is an order of magnitude faster than the manual fingerprint collection method, and using the radio map generated by our method achieves a much better accuracy compared to the existing methods.
Detecting Unsigned Physical Road Incidents from Driver-View Images
Apr 24, 2020
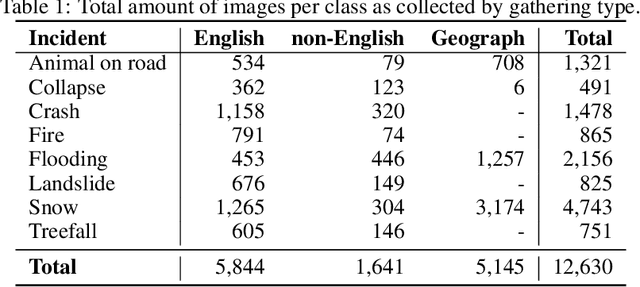
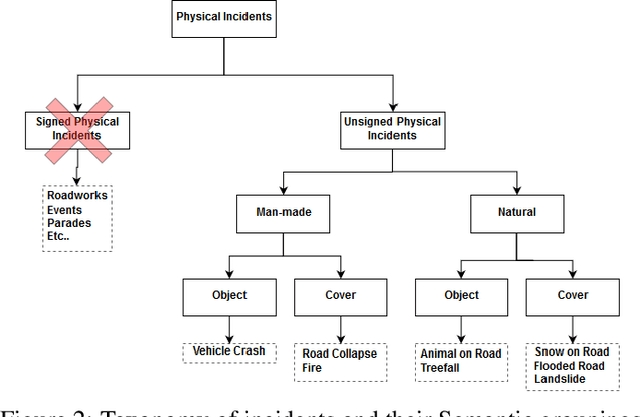
Safety on roads is of uttermost importance, especially in the context of autonomous vehicles. A critical need is to detect and communicate disruptive incidents early and effectively. In this paper we propose a system based on an off-the-shelf deep neural network architecture that is able to detect and recognize types of unsigned (non-placarded, such as traffic signs), physical (visible in images) road incidents. We develop a taxonomy for unsigned physical incidents to provide a means of organizing and grouping related incidents. After selecting eight target types of incidents, we collect a dataset of twelve thousand images gathered from publicly-available web sources. We subsequently fine-tune a convolutional neural network to recognize the eight types of road incidents. The proposed model is able to recognize incidents with a high level of accuracy (higher than 90%). We further show that while our system generalizes well across spatial context by training a classifier on geostratified data in the United Kingdom (with an accuracy of over 90%), the translation to visually less similar environments requires spatially distributed data collection. Note: this is a pre-print version of work accepted in IEEE Transactions on Intelligent Vehicles (T-IV;in press). The paper is currently in production, and the DOI link will be added soon.