 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurfel-based 3D Registration with Equivariant SE(3) Features
Aug 28, 2025Point cloud registration is crucial for ensuring 3D alignment consistency of multiple local point clouds in 3D reconstruction for remote sensing or digital heritage. While various point cloud-based registration methods exist, both non-learning and learning-based, they ignore point orientations and point uncertainties, making the model susceptible to noisy input and aggressive rotations of the input point cloud like orthogonal transformation; thus, it necessitates extensive training point clouds with transformation augmentations. To address these issues, we propose a novel surfel-based pose learning regression approach. Our method can initialize surfels from Lidar point cloud using virtual perspective camera parameters, and learns explicit $\mathbf{SE(3)}$ equivariant features, including both position and rotation through $\mathbf{SE(3)}$ equivariant convolutional kernels to predict relative transformation between source and target scans. The model comprises an equivariant convolutional encoder, a cross-attention mechanism for similarity computation, a fully-connected decoder, and a non-linear Huber loss. Experimental results on indoor and outdoor datasets demonstrate our model superiority and robust performance on real point-cloud scans compared to state-of-the-art methods.
* 5 pages, 4 figures
A Survey of Robotic Navigation and Manipulation with Physics Simulators in the Era of Embodied AI
May 01, 2025Navigation and manipulation are core capabilities in Embodied AI, yet training agents with these capabilities in the real world faces high costs and time complexity. Therefore, sim-to-real transfer has emerged as a key approach, yet the sim-to-real gap persists. This survey examines how physics simulators address this gap by analyzing their properties overlooked in previous surveys. We also analyze their features for navigation and manipulation tasks, along with hardware requirements. Additionally, we offer a resource with benchmark datasets, metrics, simulation platforms, and cutting-edge methods-such as world models and geometric equivariance-to help researchers select suitable tools while accounting for hardware constraints.
Equi-GSPR: Equivariant SE(3) Graph Network Model for Sparse Point Cloud Registration
Oct 08, 2024Point cloud registration is a foundational task for 3D alignment and reconstruction applications. While both traditional and learning-based registration approaches have succeeded, leveraging the intrinsic symmetry of point cloud data, including rotation equivariance, has received insufficient attention. This prohibits the model from learning effectively, resulting in a requirement for more training data and increased model complexity. To address these challenges, we propose a graph neural network model embedded with a local Spherical Euclidean 3D equivariance property through SE(3) message passing based propagation. Our model is composed mainly of a descriptor module, equivariant graph layers, match similarity, and the final regression layers. Such modular design enables us to utilize sparsely sampled input points and initialize the descriptor by self-trained or pre-trained geometric feature descriptors easily. Experiments conducted on the 3DMatch and KITTI datasets exhibit the compelling and robust performance of our model compared to state-of-the-art approaches, while the model complexity remains relatively low at the same time.
FocDepthFormer: Transformer with LSTM for Depth Estimation from Focus
Oct 17, 2023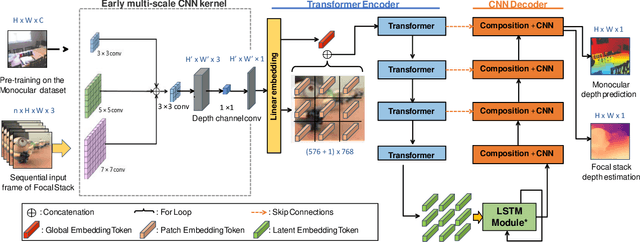


Depth estimation from focal stacks is a fundamental computer vision problem that aims to infer depth from focus/defocus cues in the image stacks. Most existing methods tackle this problem by applying convolutional neural networks (CNNs) with 2D or 3D convolutions over a set of fixed stack images to learn features across images and stacks. Their performance is restricted due to the local properties of the CNNs, and they are constrained to process a fixed number of stacks consistent in train and inference, limiting the generalization to the arbitrary length of stacks. To handle the above limitations, we develop a novel Transformer-based network, FocDepthFormer, composed mainly of a Transformer with an LSTM module and a CNN decoder. The self-attention in Transformer enables learning more informative features via an implicit non-local cross reference. The LSTM module is learned to integrate the representations across the stack with arbitrary images. To directly capture the low-level features of various degrees of focus/defocus, we propose to use multi-scale convolutional kernels in an early-stage encoder. Benefiting from the design with LSTM, our FocDepthFormer can be pre-trained with abundant monocular RGB depth estimation data for visual pattern capturing, alleviating the demand for the hard-to-collect focal stack data. Extensive experiments on various focal stack benchmark datasets show that our model outperforms the state-of-the-art models on multiple metrics.
Hierarchical Sampling based Particle Filter for Visual-inertial Gimbal in the Wild
Jun 22, 2022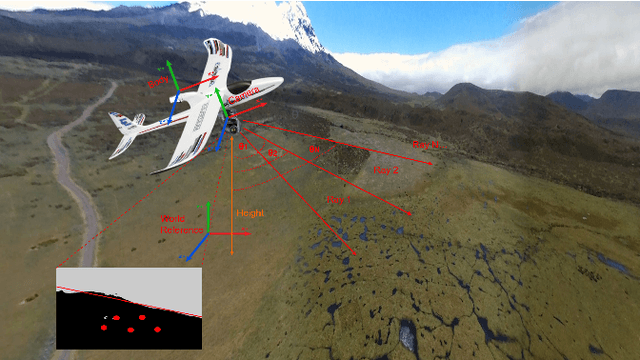
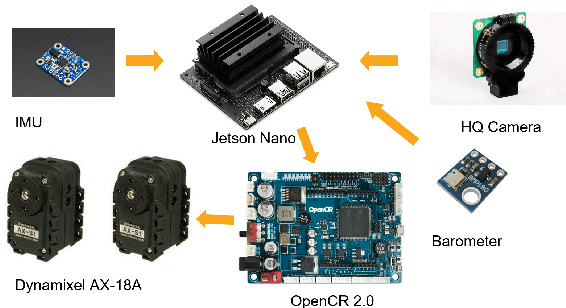
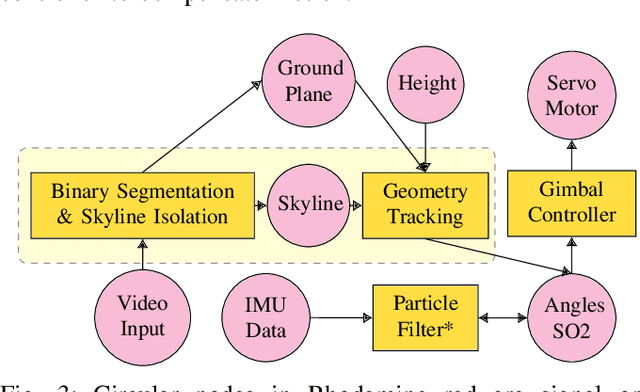

The gimbal platform has been widely used in photogrammetry and robot perceptual module to stabilize the camera pose, thereby improving the captured video quality. Usually a gimbal is mainly composed of sensors and actuator parts. The orientation measurements from sensor can be inputted directly to actuator to steer camera towards proper pose. But the off-the-shelf custom product is either quite expensive, or depending on highly precise IMU and Brushless DC motor with hall sensor to estimate angles, which is prone to suffer from accumulative drift over long-term operation. In this paper, a CV based new tracking and fusion algorithm dedicated for gimbal system on drones operating in nature is proposed, main contributions are listed as below: a) a light-weight Resnet -18 backbone based network model was trained from scratch, and deployed onto Jetson Nano platform to segment the image into binary parts (ground and sky). b) geometric primitives tracking of the skyline and ground plane in 3D as cues, along with orientation estimation from IMU can provide multiple guesses for orientation. c) spherical surface based adaptive particle sampling can fuse orientation from aforementioned sensor sources efficiently. The final prototyping algorithm is tested on the real-time embedded system, and with both simulation on ground and real functional tests in the air.
Unsupervised Monocular Depth Prediction for Indoor Continuous Video Streams
Nov 20, 2019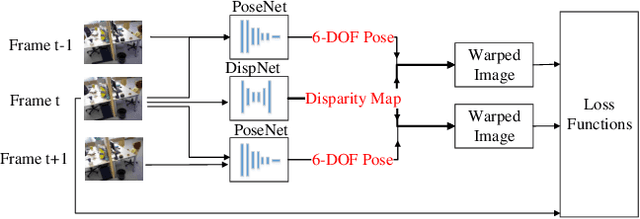

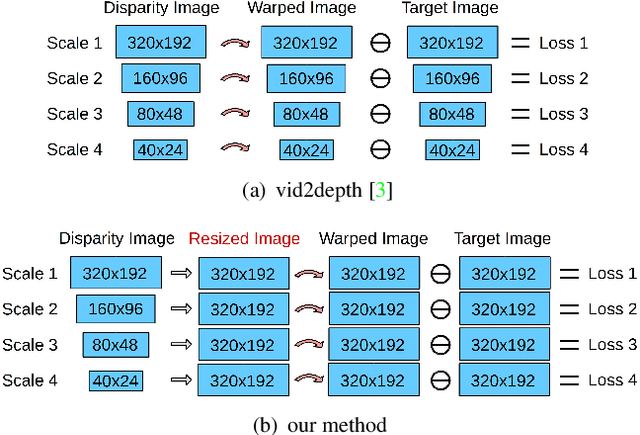

This paper studies unsupervised monocular depth prediction problem. Most of existing unsupervised depth prediction algorithms are developed for outdoor scenarios, while the depth prediction work in the indoor environment is still very scarce to our knowledge. Therefore, this work focuses on narrowing the gap by firstly evaluating existing approaches in the indoor environments and then improving the state-of-the-art design of architecture. Unlike typical outdoor training dataset, such as KITTI with motion constraints, data for indoor environment contains more arbitrary camera movement and short baseline between two consecutive images, which deteriorates the network training for the pose estimation. To address this issue, we propose two methods: Firstly, we propose a novel reconstruction loss function to constraint pose estimation, resulting in accuracy improvement of the predicted disparity map; secondly, we use an ensemble learning with a flipping strategy along with a median filter, directly taking operation on the output disparity map. We evaluate our approaches on the TUM RGB-D and self-collected datasets. The results have shown that both approaches outperform the previous state-of-the-art unsupervised learning approaches.
Robust Data Association for Object-level Semantic SLAM
Sep 30, 2019
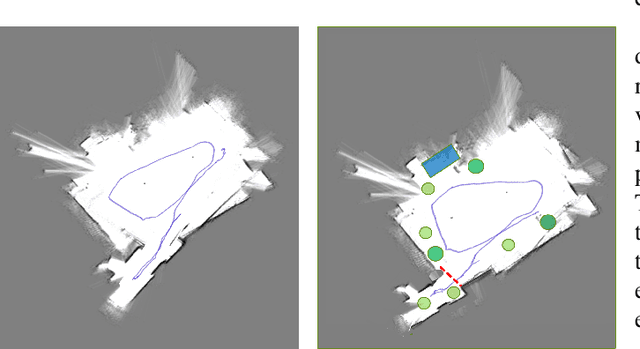
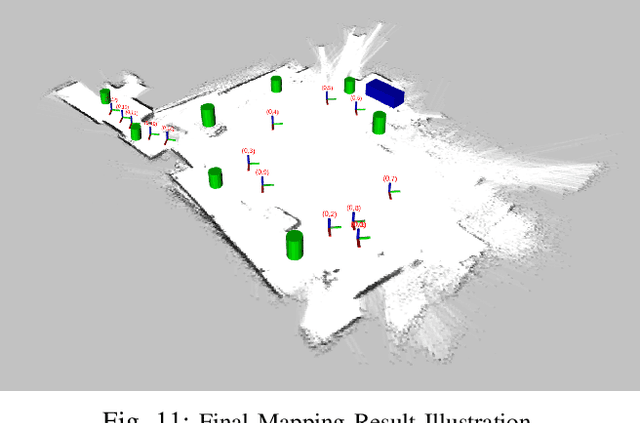
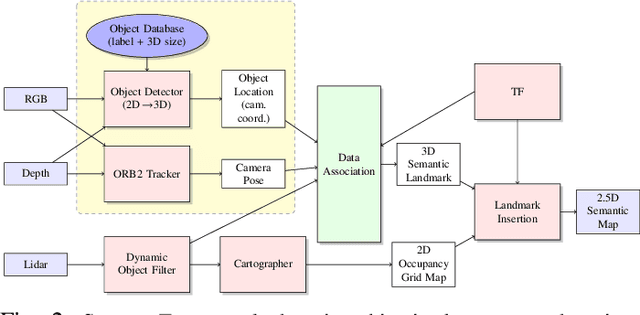
Simultaneous mapping and localization (SLAM) in an real indoor environment is still a challenging task. Traditional SLAM approaches rely heavily on low-level geometric constraints like corners or lines, which may lead to tracking failure in textureless surroundings or cluttered world with dynamic objects. In this paper, a compact semantic SLAM framework is proposed, with utilization of both geometric and object-level semantic constraints jointly, a more consistent mapping result, and more accurate pose estimation can be obtained. Two main contributions are presented int the paper, a) a robust and efficient SLAM data association and optimization framework is proposed, it models both discrete semantic labeling and continuous pose. b) a compact map representation, combining 2D Lidar map with object detection is presented. Experiments on public indoor datasets, TUM-RGBD, ICL-NUIM, and our own collected datasets prove the improving of SLAM robustness and accuracy compared to other popular SLAM systems, meanwhile a map maintenance efficiency can be achieved.
3D Reconstruction & Assessment Framework based on affordable 2D Lidar
Sep 10, 2018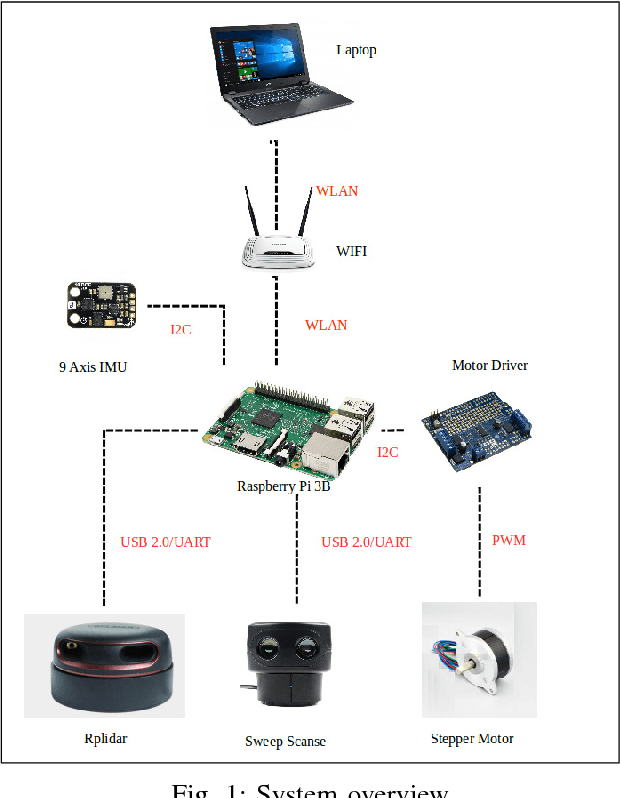
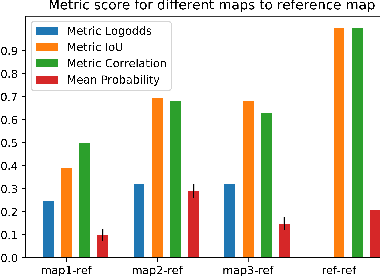
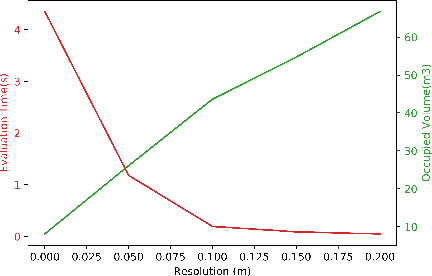
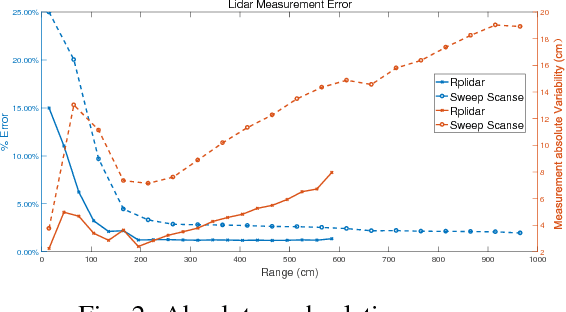
Lidar is extensively used in the industry and mass-market. Due to its measurement accuracy and insensitivity to illumination compared to cameras, It is applied onto a broad range of applications, like geodetic engineering, self driving cars or virtual reality. But the 3D Lidar with multi-beam is very expensive, and the massive measurements data can not be fully leveraged on some constrained platforms. The purpose of this paper is to explore the possibility of using cheap 2D Lidar off-the-shelf, to preform complex 3D Reconstruction, moreover, the generated 3D map quality is evaluated by our proposed metrics at the end. The 3D map is constructed in two ways, one way in which the scan is performed at known positions with an external rotary axis at another plane. The other way, in which the 2D Lidar for mapping and another 2D Lidar for localization are placed on a trolley, the trolley is pushed on the ground arbitrarily. The generated maps by different approaches are converted to octomaps uniformly before the evaluation. The similarity and difference between two maps will be evaluated by the proposed metrics thoroughly. The whole mapping system is composed of several modular components. A 3D bracket was made for assembling of the Lidar with a long range, the driver and the motor together. A cover platform made for the IMU and 2D Lidar with a shorter range but high accuracy. The software is stacked up in different ROS packages.
* 7 pages, 9 Postscript figures. Accepted by 2018 IEEE International Conference on Advanced Intelligent Mechatronics