 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocDepthFormer: Transformer with LSTM for Depth Estimation from Focus
Oct 17, 2023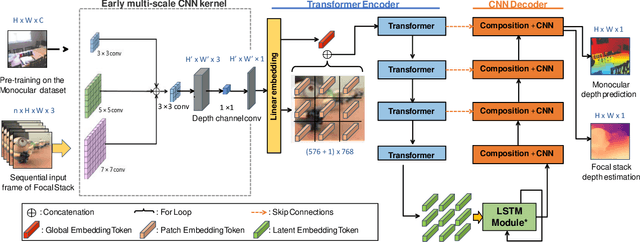

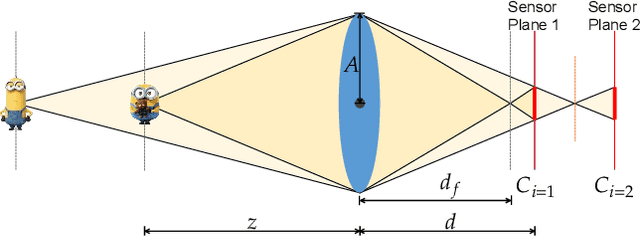

Depth estimation from focal stacks is a fundamental computer vision problem that aims to infer depth from focus/defocus cues in the image stacks. Most existing methods tackle this problem by applying convolutional neural networks (CNNs) with 2D or 3D convolutions over a set of fixed stack images to learn features across images and stacks. Their performance is restricted due to the local properties of the CNNs, and they are constrained to process a fixed number of stacks consistent in train and inference, limiting the generalization to the arbitrary length of stacks. To handle the above limitations, we develop a novel Transformer-based network, FocDepthFormer, composed mainly of a Transformer with an LSTM module and a CNN decoder. The self-attention in Transformer enables learning more informative features via an implicit non-local cross reference. The LSTM module is learned to integrate the representations across the stack with arbitrary images. To directly capture the low-level features of various degrees of focus/defocus, we propose to use multi-scale convolutional kernels in an early-stage encoder. Benefiting from the design with LSTM, our FocDepthFormer can be pre-trained with abundant monocular RGB depth estimation data for visual pattern capturing, alleviating the demand for the hard-to-collect focal stack data. Extensive experiments on various focal stack benchmark datasets show that our model outperforms the state-of-the-art models on multiple metrics.