 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Distribution Prior for LiDAR Out-of-Distribution Detection
Apr 10, 2026LiDAR-based perception is critical for autonomous driving due to its robustness to poor lighting and visibility conditions. Yet, current models operate under the closed-set assumption and often fail to recognize unexpected out-of-distribution (OOD) objects in the open world. Existing OOD scoring functions exhibit limited performance because they ignore the pronounced class imbalance inherent in LiDAR OOD detection and assume a uniform class distribution. To address this limitation, we propose the Neural Distribution Prior (NDP), a framework that models the distributional structure of network predictions and adaptively reweights OOD scores based on alignment with a learned distribution prior. NDP dynamically captures the logit distribution patterns of training data and corrects class-dependent confidence bias through an attention-based module. We further introduce a Perlin noise-based OOD synthesis strategy that generates diverse auxiliary OOD samples from input scans, enabling robust OOD training without external datasets. Extensive experiments on the SemanticKITTI and STU benchmarks demonstrate that NDP substantially improves OOD detection performance, achieving a point-level AP of 61.31\% on the STU test set, which is more than 10$\times$ higher than the previous best result. Our framework is compatible with various existing OOD scoring formulations, providing an effective solution for open-world LiDAR perception.
Relative Energy Learning for LiDAR Out-of-Distribution Detection
Nov 11, 2025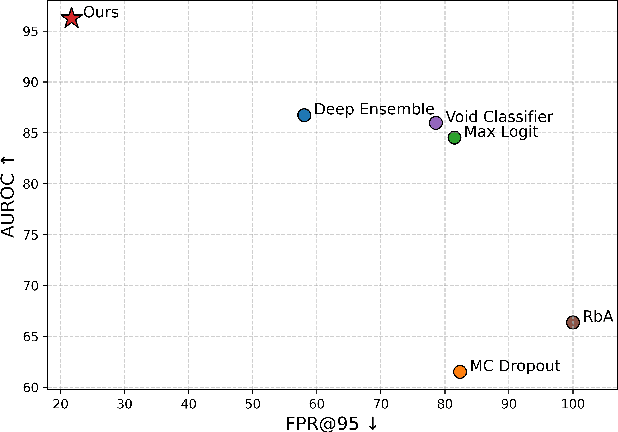
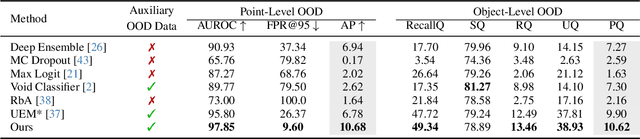
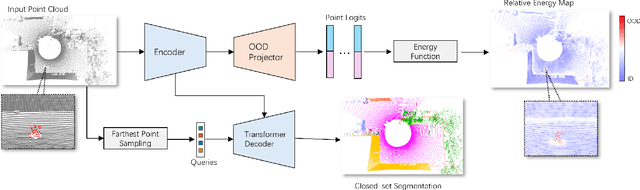

Out-of-distribution (OOD) detection is a critical requirement for reliable autonomous driving, where safety depends on recognizing road obstacles and unexpected objects beyond the training distribution. Despite extensive research on OOD detection in 2D images, direct transfer to 3D LiDAR point clouds has been proven ineffective. Current LiDAR OOD methods struggle to distinguish rare anomalies from common classes, leading to high false-positive rates and overconfident errors in safety-critical settings. We propose Relative Energy Learning (REL), a simple yet effective framework for OOD detection in LiDAR point clouds. REL leverages the energy gap between positive (in-distribution) and negative logits as a relative scoring function, mitigating calibration issues in raw energy values and improving robustness across various scenes. To address the absence of OOD samples during training, we propose a lightweight data synthesis strategy called Point Raise, which perturbs existing point clouds to generate auxiliary anomalies without altering the inlier semantics. Evaluated on SemanticKITTI and the Spotting the Unexpected (STU) benchmark, REL consistently outperforms existing methods by a large margin. Our results highlight that modeling relative energy, combined with simple synthetic outliers, provides a principled and scalable solution for reliable OOD detection in open-world autonomous driving.
From Open Vocabulary to Open World: Teaching Vision Language Models to Detect Novel Objects
Dec 01, 2024
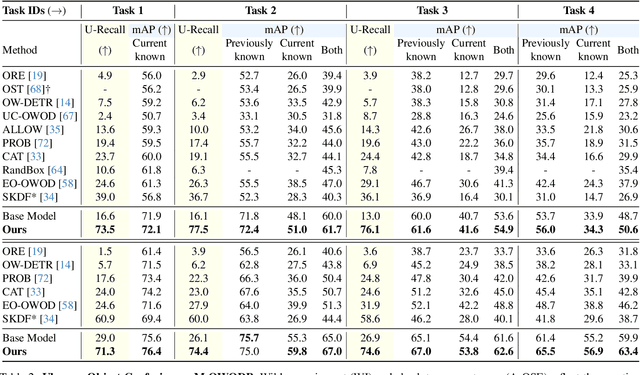
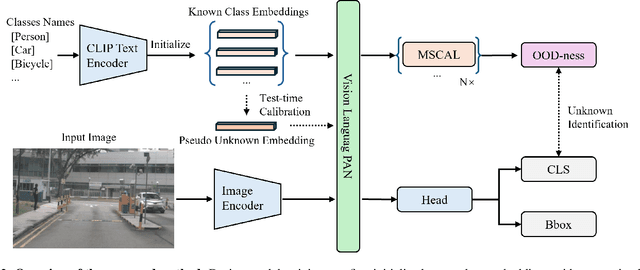

Traditional object detection methods operate under the closed-set assumption, where models can only detect a fixed number of objects predefined in the training set. Recent works on open vocabulary object detection (OVD) enable the detection of objects defined by an unbounded vocabulary, which reduces the cost of training models for specific tasks. However, OVD heavily relies on accurate prompts provided by an ''oracle'', which limits their use in critical applications such as driving scene perception. OVD models tend to misclassify near-out-of-distribution (NOOD) objects that have similar semantics to known classes, and ignore far-out-of-distribution (FOOD) objects. To address theses limitations, we propose a framework that enables OVD models to operate in open world settings, by identifying and incrementally learning novel objects. To detect FOOD objects, we propose Open World Embedding Learning (OWEL) and introduce the concept of Pseudo Unknown Embedding which infers the location of unknown classes in a continuous semantic space based on the information of known classes. We also propose Multi-Scale Contrastive Anchor Learning (MSCAL), which enables the identification of misclassified unknown objects by promoting the intra-class consistency of object embeddings at different scales. The proposed method achieves state-of-the-art performance in common open world object detection and autonomous driving benchmarks.
Improved Reinforcement Learning with Curriculum
Mar 29, 2019
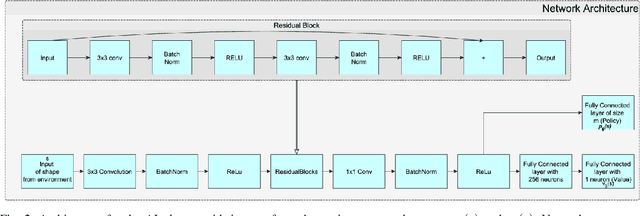

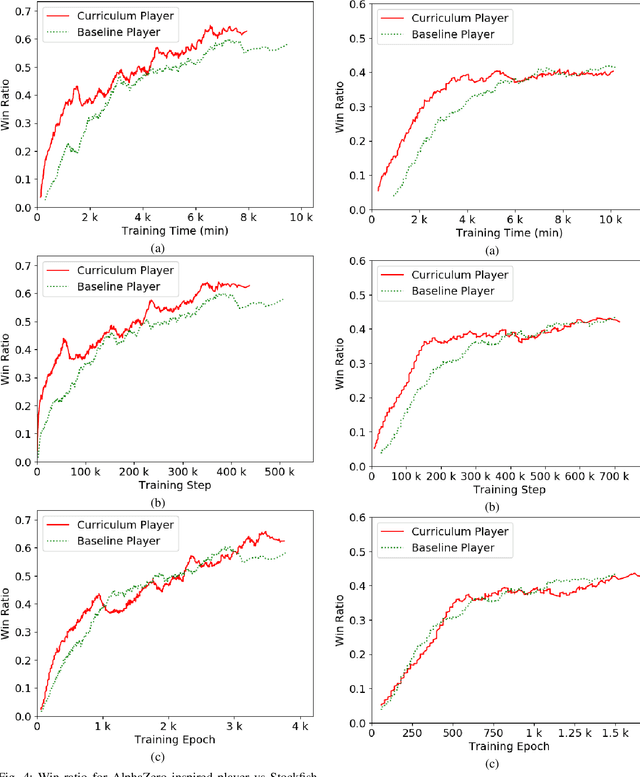
Humans tend to learn complex abstract concepts faster if examples are presented in a structured manner. For instance, when learning how to play a board game, usually one of the first concepts learned is how the game ends, i.e. the actions that lead to a terminal state (win, lose or draw). The advantage of learning end-games first is that once the actions which lead to a terminal state are understood, it becomes possible to incrementally learn the consequences of actions that are further away from a terminal state - we call this an end-game-first curriculum. Currently the state-of-the-art machine learning player for general board games, AlphaZero by Google DeepMind, does not employ a structured training curriculum; instead learning from the entire game at all times. By employing an end-game-first training curriculum to train an AlphaZero inspired player, we empirically show that the rate of learning of an artificial player can be improved during the early stages of training when compared to a player not using a training curriculum.