 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Knowledge Transfer Methods for Misaligned Urban Building Labels
Nov 07, 2023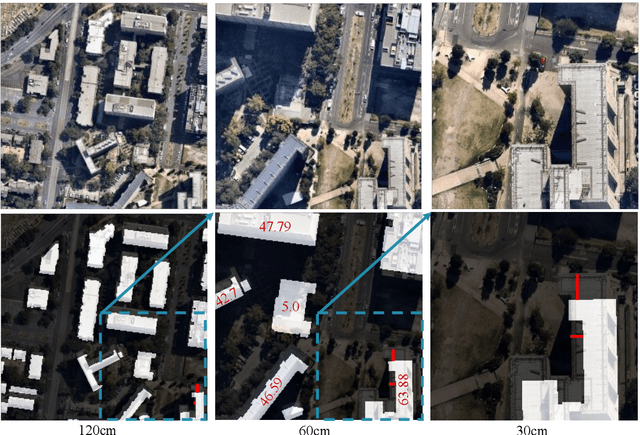
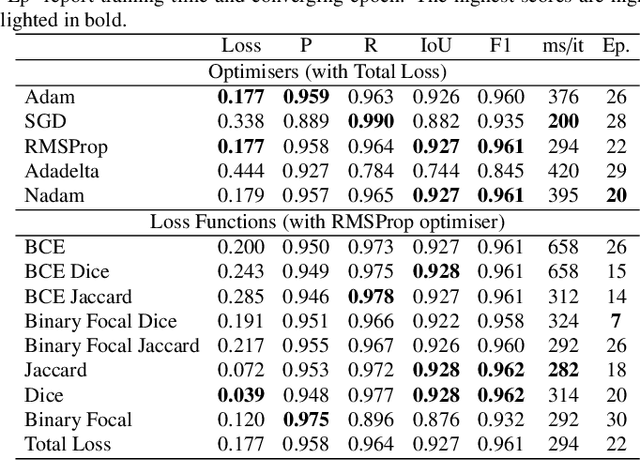
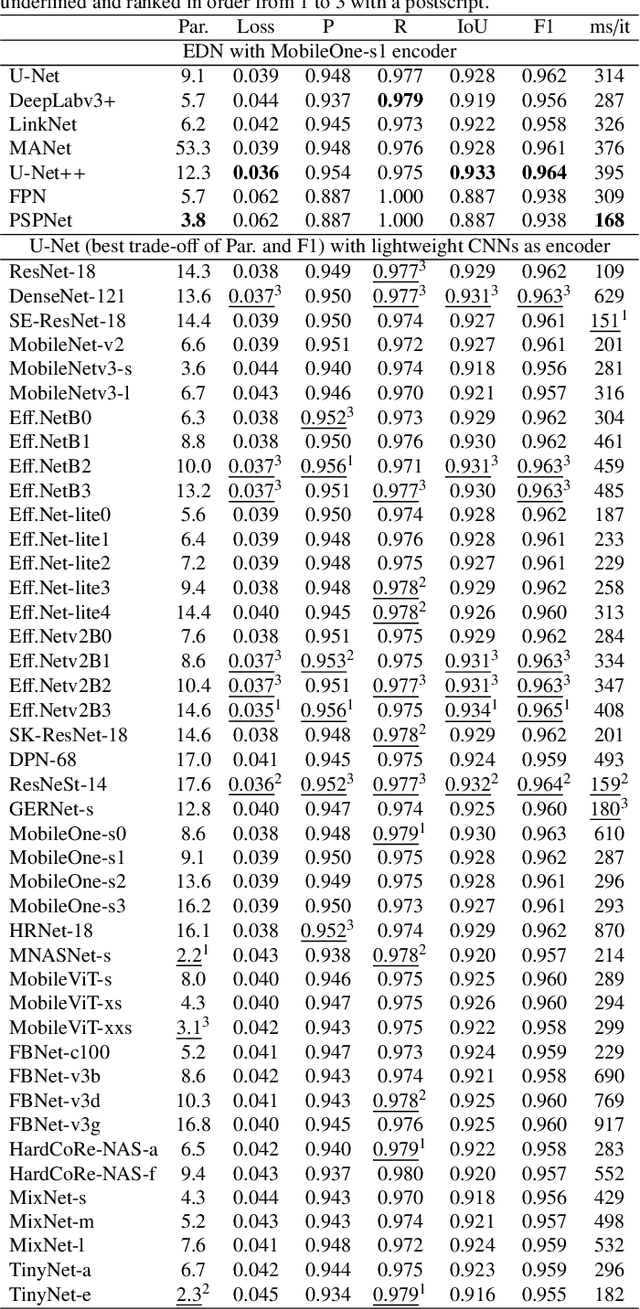
Misalignment in Earth observation (EO) images and building labels impact the training of accurate convolutional neural networks (CNNs) for semantic segmentation of building footprints. Recently, three Teacher-Student knowledge transfer methods have been introduced to address this issue: supervised domain adaptation (SDA), knowledge distillation (KD), and deep mutual learning (DML). However, these methods are merely studied for different urban buildings (low-rise, mid-rise, high-rise, and skyscrapers), where misalignment increases with building height and spatial resolution. In this study, we present a workflow for the systematic comparative study of the three methods. The workflow first identifies the best (with the highest evaluation scores) hyperparameters, lightweight CNNs for the Student (among 43 CNNs from Computer Vision), and encoder-decoder networks (EDNs) for both Teachers and Students. Secondly, three building footprint datasets are developed to train and evaluate the identified Teachers and Students in the three transfer methods. The results show that U-Net with VGG19 (U-VGG19) is the best Teacher, and U-EfficientNetv2B3 and U-EfficientNet-lite0 are among the best Students. With these Teacher-Student pairs, SDA could yield upto 0.943, 0.868, 0.912, and 0.697 F1 scores in the low-rise, mid-rise, high-rise, and skyscrapers respectively. KD and DML provide model compression of upto 82%, despite marginal loss in performance. This new comparison concludes that SDA is the most effective method to address the misalignment problem, while KD and DML can efficiently compress network size without significant loss in performance. The 158 experiments and datasets developed in this study will be valuable to minimise the misaligned labels.
A novel dual skip connection mechanism in U-Nets for building footprint extraction
Mar 16, 2023



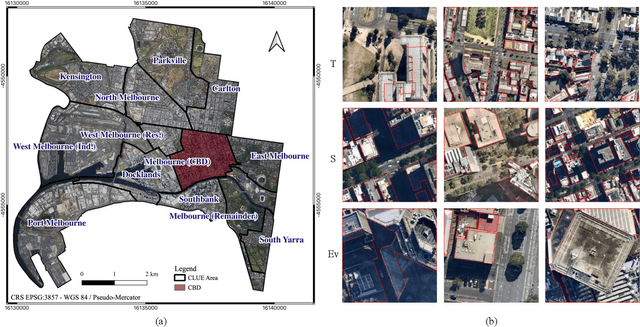
The importance of building footprints and their inventory has been recognised as an enabler for multiple societal problems. Extracting urban building footprint is complex and requires semantic segmentation of very high-resolution (VHR) earth observation (EO) images. U-Net is a common deep learning architecture for such segmentation. It has seen several re-incarnation including U-Net++ and U-Net3+ with a focus on multi-scale feature aggregation with re-designed skip connections. However, the exploitation of multi-scale information is still evolving. In this paper, we propose a dual skip connection mechanism (DSCM) for U-Net and a dual full-scale skip connection mechanism (DFSCM) for U-Net3+. The DSCM in U-Net doubles the features in the encoder and passes them to the decoder for precise localisation. Similarly, the DFSCM incorporates increased low-level context information with high-level semantics from feature maps in different scales. The DSCM is further tested in ResUnet and different scales of U-Net. The proposed mechanisms, therefore, produce several novel networks that are evaluated in a benchmark WHU building dataset and a multi-resolution dataset that we develop for the City of Melbourne. The results on the benchmark dataset demonstrate 17.7% and 18.4% gain in F1 score and Intersection over Union (IoU) compared to the state-of-the-art vanilla U-Net3+. In the same experimental setup, DSCM on U-Net and ResUnet provides a gain in five accuracy measures against the original networks. The codes will be available in a GitHub link after peer review.