 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogNEO: A GPT-Neo Reinforcement Learning Framework for Accurate Real-Time Log Anomaly Detection
Jun 06, 2026Detecting anomalies in large-scale system logs is critical for the reliability and security of modern computing infrastructure. We present LogNEO, a log anomaly detector built on EleutherAI's GPT-Neo (1.3B parameters) and fine-tuned with a novel partial-credit, exponentially decaying position-aware reward scheme combined with cross-entropy regularisation via Proximal Policy Optimisation (PPO). The position-aware reward explicitly models prediction difficulty: early positions receive higher rewards for correct predictions, while later positions incur stronger penalties for errors. LogNEO attains F1-scores of 0.927, 0.913, and 0.984 on the HDFS, BGL, and Thunderbird benchmarks, improving recall by up to 6 percentage points over the prior state-of-the-art LogGPT while maintaining comparable precision. A production microservice deployment over Apache Kafka, Redis, and TensorRT-accelerated inference demonstrates 45 ms end-to-end latency at 15,000 events per second.
Cosine-Normalized Attention for Hyperspectral Image Classification
Apr 02, 2026Transformer-based methods have improved hyperspectral image classification (HSIC) by modeling long-range spatial-spectral dependencies; however, their attention mechanisms typically rely on dot-product similarity, which mixes feature magnitude and orientation and may be suboptimal for hyperspectral data. This work revisits attention scoring from a geometric perspective and introduces a cosine-normalized attention formulation that aligns similarity computation with the angular structure of hyperspectral signatures. By projecting query and key embeddings onto a unit hypersphere and applying a squared cosine similarity, the proposed method emphasizes angular relationships while reducing sensitivity to magnitude variations. The formulation is integrated into a spatial-spectral Transformer and evaluated under extremely limited supervision. Experiments on three benchmark datasets demonstrate that the proposed approach consistently achieves higher performance, outperforming several recent Transformer- and Mamba-based models despite using a lightweight backbone. In addition, a controlled analysis of multiple attention score functions shows that cosine-based scoring provides a reliable inductive bias for hyperspectral representation learning.
Dynamic Memory-enhanced Transformer for Hyperspectral Image Classification
Apr 17, 2025Hyperspectral image (HSI) classification remains a challenging task due to the intricate spatial-spectral correlations. Existing transformer models excel in capturing long-range dependencies but often suffer from information redundancy and attention inefficiencies, limiting their ability to model fine-grained relationships crucial for HSI classification. To overcome these limitations, this work proposes MemFormer, a lightweight and memory-enhanced transformer. MemFormer introduces a memory-enhanced multi-head attention mechanism that iteratively refines a dynamic memory module, enhancing feature extraction while reducing redundancy across layers. Additionally, a dynamic memory enrichment strategy progressively captures complex spatial and spectral dependencies, leading to more expressive feature representations. To further improve structural consistency, we incorporate a spatial-spectral positional encoding (SSPE) tailored for HSI data, ensuring continuity without the computational burden of convolution-based approaches. Extensive experiments on benchmark datasets demonstrate that MemFormer achieves superior classification accuracy, outperforming state-of-the-art methods.
EnergyFormer: Energy Attention with Fourier Embedding for Hyperspectral Image Classification
Mar 11, 2025Hyperspectral imaging (HSI) provides rich spectral-spatial information across hundreds of contiguous bands, enabling precise material discrimination in applications such as environmental monitoring, agriculture, and urban analysis. However, the high dimensionality and spectral variability of HSI data pose significant challenges for feature extraction and classification. This paper presents EnergyFormer, a transformer-based framework designed to address these challenges through three key innovations: (1) Multi-Head Energy Attention (MHEA), which optimizes an energy function to selectively enhance critical spectral-spatial features, improving feature discrimination; (2) Fourier Position Embedding (FoPE), which adaptively encodes spectral and spatial dependencies to reinforce long-range interactions; and (3) Enhanced Convolutional Block Attention Module (ECBAM), which selectively amplifies informative wavelength bands and spatial structures, enhancing representation learning. Extensive experiments on the WHU-Hi-HanChuan, Salinas, and Pavia University datasets demonstrate that EnergyFormer achieves exceptional overall accuracies of 99.28\%, 98.63\%, and 98.72\%, respectively, outperforming state-of-the-art CNN, transformer, and Mamba-based models. The source code will be made available at https://github.com/mahmad000.
Hybrid State-Space and GRU-based Graph Tokenization Mamba for Hyperspectral Image Classification
Feb 10, 2025



Hyperspectral image (HSI) classification plays a pivotal role in domains such as environmental monitoring, agriculture, and urban planning. However, it faces significant challenges due to the high-dimensional nature of the data and the complex spectral-spatial relationships inherent in HSI. Traditional methods, including conventional machine learning and convolutional neural networks (CNNs), often struggle to effectively capture these intricate spectral-spatial features and global contextual information. Transformer-based models, while powerful in capturing long-range dependencies, often demand substantial computational resources, posing challenges in scenarios where labeled datasets are limited, as is commonly seen in HSI applications. To overcome these challenges, this work proposes GraphMamba, a hybrid model that combines spectral-spatial token generation, graph-based token prioritization, and cross-attention mechanisms. The model introduces a novel hybridization of state-space modeling and Gated Recurrent Units (GRU), capturing both linear and nonlinear spatial-spectral dynamics. GraphMamba enhances the ability to model complex spatial-spectral relationships while maintaining scalability and computational efficiency across diverse HSI datasets. Through comprehensive experiments, we demonstrate that GraphMamba outperforms existing state-of-the-art models, offering a scalable and robust solution for complex HSI classification tasks.
DiffFormer: a Differential Spatial-Spectral Transformer for Hyperspectral Image Classification
Dec 23, 2024



Hyperspectral image classification (HSIC) has gained significant attention because of its potential in analyzing high-dimensional data with rich spectral and spatial information. In this work, we propose the Differential Spatial-Spectral Transformer (DiffFormer), a novel framework designed to address the inherent challenges of HSIC, such as spectral redundancy and spatial discontinuity. The DiffFormer leverages a Differential Multi-Head Self-Attention (DMHSA) mechanism, which enhances local feature discrimination by introducing differential attention to accentuate subtle variations across neighboring spectral-spatial patches. The architecture integrates Spectral-Spatial Tokenization through three-dimensional (3D) convolution-based patch embeddings, positional encoding, and a stack of transformer layers equipped with the SWiGLU activation function for efficient feature extraction (SwiGLU is a variant of the Gated Linear Unit (GLU) activation function). A token-based classification head further ensures robust representation learning, enabling precise labeling of hyperspectral pixels. Extensive experiments on benchmark hyperspectral datasets demonstrate the superiority of DiffFormer in terms of classification accuracy, computational efficiency, and generalizability, compared to existing state-of-the-art (SOTA) methods. In addition, this work provides a detailed analysis of computational complexity, showcasing the scalability of the model for large-scale remote sensing applications. The source code will be made available at \url{https://github.com/mahmad000/DiffFormer} after the first round of revision.
Spectral-Spatial Transformer with Active Transfer Learning for Hyperspectral Image Classification
Nov 27, 2024



The classification of hyperspectral images (HSI) is a challenging task due to the high spectral dimensionality and limited labeled data typically available for training. In this study, we propose a novel multi-stage active transfer learning (ATL) framework that integrates a Spatial-Spectral Transformer (SST) with an active learning process for efficient HSI classification. Our approach leverages a pre-trained (initially trained) SST model, fine-tuned iteratively on newly acquired labeled samples using an uncertainty-diversity (Spatial-Spectral Neighborhood Diversity) querying mechanism. This mechanism identifies the most informative and diverse samples, thereby optimizing the transfer learning process to reduce both labeling costs and model uncertainty. We further introduce a dynamic freezing strategy, selectively freezing layers of the SST model to minimize computational overhead while maintaining adaptability to spectral variations in new data. One of the key innovations in our work is the self-calibration of spectral and spatial attention weights, achieved through uncertainty-guided active learning. This not only enhances the model's robustness in handling dynamic and disjoint spectral profiles but also improves generalization across multiple HSI datasets. Additionally, we present a diversity-promoting sampling strategy that ensures the selected samples span distinct spectral regions, preventing overfitting to particular spectral classes. Experiments on benchmark HSI datasets demonstrate that the SST-ATL framework significantly outperforms existing CNN and SST-based methods, offering superior accuracy, efficiency, and computational performance. The source code can be accessed at \url{https://github.com/mahmad000/ATL-SST}.
A Comprehensive Survey for Hyperspectral Image Classification: The Evolution from Conventional to Transformers
May 09, 2024



Hyperspectral Image Classification (HSC) is a challenging task due to the high dimensionality and complex nature of Hyperspectral (HS) data. Traditional Machine Learning approaches while effective, face challenges in real-world data due to varying optimal feature sets, subjectivity in human-driven design, biases, and limitations. Traditional approaches encounter the curse of dimensionality, struggle with feature selection and extraction, lack spatial information consideration, exhibit limited robustness to noise, face scalability issues, and may not adapt well to complex data distributions. In recent years, Deep Learning (DL) techniques have emerged as powerful tools for addressing these challenges. This survey provides a comprehensive overview of the current trends and future prospects in HSC, focusing on the advancements from DL models to the emerging use of Transformers. We review the key concepts, methodologies, and state-of-the-art approaches in DL for HSC. We explore the potential of Transformer-based models in HSC, outlining their benefits and challenges. We also delve into emerging trends in HSC, as well as thorough discussions on Explainable AI and Interoperability concepts along with Diffusion Models (image denoising, feature extraction, and image fusion). Lastly, we address several open challenges and research questions pertinent to HSC. Comprehensive experimental results have been undertaken using three HS datasets to verify the efficacy of various conventional DL models and Transformers. Finally, we outline future research directions and potential applications that can further enhance the accuracy and efficiency of HSC. The Source code is available at \href{https://github.com/mahmad00/Conventional-to-Transformer-for-Hyperspectral-Image-Classification-Survey-2024}{github.com/mahmad00}.
Quranic Audio Dataset: Crowdsourced and Labeled Recitation from Non-Arabic Speakers
May 04, 2024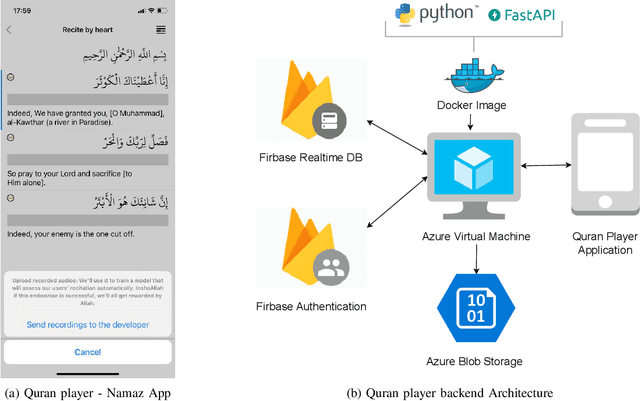

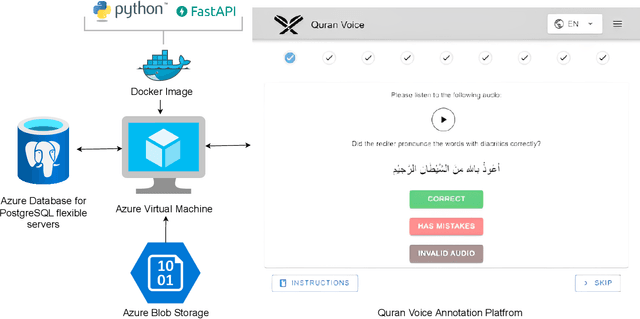
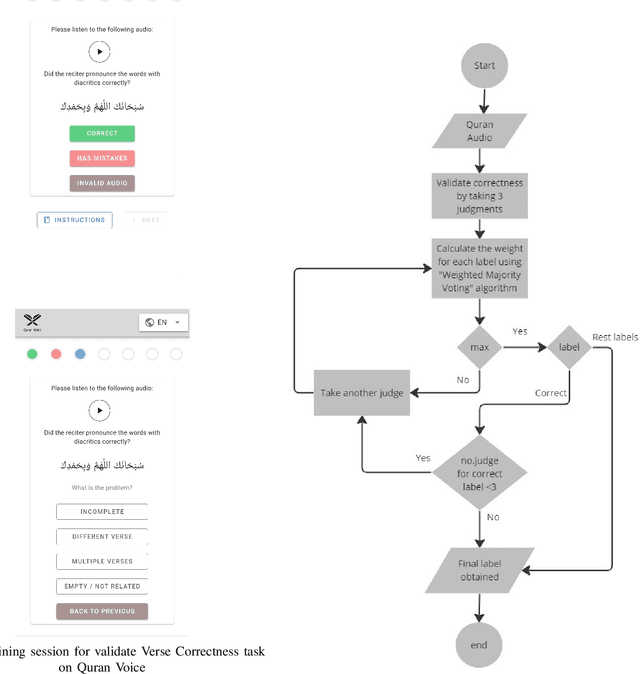
This paper addresses the challenge of learning to recite the Quran for non-Arabic speakers. We explore the possibility of crowdsourcing a carefully annotated Quranic dataset, on top of which AI models can be built to simplify the learning process. In particular, we use the volunteer-based crowdsourcing genre and implement a crowdsourcing API to gather audio assets. We integrated the API into an existing mobile application called NamazApp to collect audio recitations. We developed a crowdsourcing platform called Quran Voice for annotating the gathered audio assets. As a result, we have collected around 7000 Quranic recitations from a pool of 1287 participants across more than 11 non-Arabic countries, and we have annotated 1166 recitations from the dataset in six categories. We have achieved a crowd accuracy of 0.77, an inter-rater agreement of 0.63 between the annotators, and 0.89 between the labels assigned by the algorithm and the expert judgments.
Transformers Fusion across Disjoint Samples for Hyperspectral Image Classification
May 02, 2024



3D Swin Transformer (3D-ST) known for its hierarchical attention and window-based processing, excels in capturing intricate spatial relationships within images. Spatial-spectral Transformer (SST), meanwhile, specializes in modeling long-range dependencies through self-attention mechanisms. Therefore, this paper introduces a novel method: an attentional fusion of these two transformers to significantly enhance the classification performance of Hyperspectral Images (HSIs). What sets this approach apart is its emphasis on the integration of attentional mechanisms from both architectures. This integration not only refines the modeling of spatial and spectral information but also contributes to achieving more precise and accurate classification results. The experimentation and evaluation of benchmark HSI datasets underscore the importance of employing disjoint training, validation, and test samples. The results demonstrate the effectiveness of the fusion approach, showcasing its superiority over traditional methods and individual transformers. Incorporating disjoint samples enhances the robustness and reliability of the proposed methodology, emphasizing its potential for advancing hyperspectral image classification.