 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid State-Space and GRU-based Graph Tokenization Mamba for Hyperspectral Image Classification
Feb 10, 2025



Hyperspectral image (HSI) classification plays a pivotal role in domains such as environmental monitoring, agriculture, and urban planning. However, it faces significant challenges due to the high-dimensional nature of the data and the complex spectral-spatial relationships inherent in HSI. Traditional methods, including conventional machine learning and convolutional neural networks (CNNs), often struggle to effectively capture these intricate spectral-spatial features and global contextual information. Transformer-based models, while powerful in capturing long-range dependencies, often demand substantial computational resources, posing challenges in scenarios where labeled datasets are limited, as is commonly seen in HSI applications. To overcome these challenges, this work proposes GraphMamba, a hybrid model that combines spectral-spatial token generation, graph-based token prioritization, and cross-attention mechanisms. The model introduces a novel hybridization of state-space modeling and Gated Recurrent Units (GRU), capturing both linear and nonlinear spatial-spectral dynamics. GraphMamba enhances the ability to model complex spatial-spectral relationships while maintaining scalability and computational efficiency across diverse HSI datasets. Through comprehensive experiments, we demonstrate that GraphMamba outperforms existing state-of-the-art models, offering a scalable and robust solution for complex HSI classification tasks.
Multi-head Spatial-Spectral Mamba for Hyperspectral Image Classification
Aug 02, 2024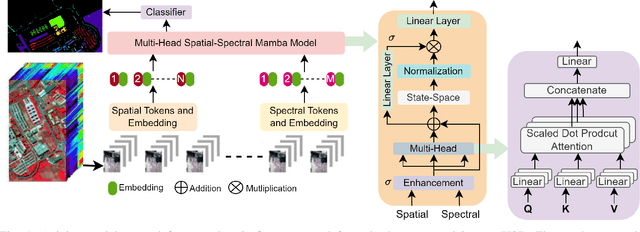


Spatial-Spectral Mamba (SSM) improves computational efficiency and captures long-range dependencies, addressing Transformer limitations. However, traditional Mamba models overlook rich spectral information in HSIs and struggle with high dimensionality and sequential data. To address these issues, we propose the SSM with multi-head self-attention and token enhancement (MHSSMamba). This model integrates spectral and spatial information by enhancing spectral tokens and using multi-head attention to capture complex relationships between spectral bands and spatial locations. It also manages long-range dependencies and the sequential nature of HSI data, preserving contextual information across spectral bands. MHSSMamba achieved remarkable classification accuracies of 97.62\% on Pavia University, 96.92\% on the University of Houston, 96.85\% on Salinas, and 99.49\% on Wuhan-longKou datasets.
Spatial-Spectral Morphological Mamba for Hyperspectral Image Classification
Aug 02, 2024



In recent years, Transformers have garnered significant attention for Hyperspectral Image Classification (HSIC) due to their self-attention mechanism, which provides strong classification performance. However, these models face major challenges in computational efficiency, as their complexity increases quadratically with the sequence length. The Mamba architecture, leveraging a State Space Model, offers a more efficient alternative to Transformers. This paper introduces the Spatial-Spectral Morphological Mamba (MorpMamba) model. In the MorpMamba model, a token generation module first converts the Hyperspectral Image (HSI) patch into spatial-spectral tokens. These tokens are then processed by a morphology block, which computes structural and shape information using depthwise separable convolutional operations. The extracted information is enhanced in a feature enhancement module that adjusts the spatial and spectral tokens based on the center region of the HSI sample, allowing for effective information fusion within each block. Subsequently, the tokens are refined in a multi-head self-attention block to further improve the feature space. Finally, the combined information is fed into the state space block for classification and the creation of the ground truth map. Experiments on widely used Hyperspectral (HS) datasets demonstrate that the MorpMamba model outperforms (parametric efficiency) both CNN and Transformer models.
Pyramid Hierarchical Transformer for Hyperspectral Image Classification
Apr 23, 2024



The traditional Transformer model encounters challenges with variable-length input sequences, particularly in Hyperspectral Image Classification (HSIC), leading to efficiency and scalability concerns. To overcome this, we propose a pyramid-based hierarchical transformer (PyFormer). This innovative approach organizes input data hierarchically into segments, each representing distinct abstraction levels, thereby enhancing processing efficiency for lengthy sequences. At each level, a dedicated transformer module is applied, effectively capturing both local and global context. Spatial and spectral information flow within the hierarchy facilitates communication and abstraction propagation. Integration of outputs from different levels culminates in the final input representation. Experimental results underscore the superiority of the proposed method over traditional approaches. Additionally, the incorporation of disjoint samples augments robustness and reliability, thereby highlighting the potential of our approach in advancing HSIC. The source code is available at https://github.com/mahmad00/PyFormer.