 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Scanning Strategies with Vision Mamba in Semantic Segmentation of Remote Sensing Imagery: An Experimental Study
Paper and Code
May 14, 2024
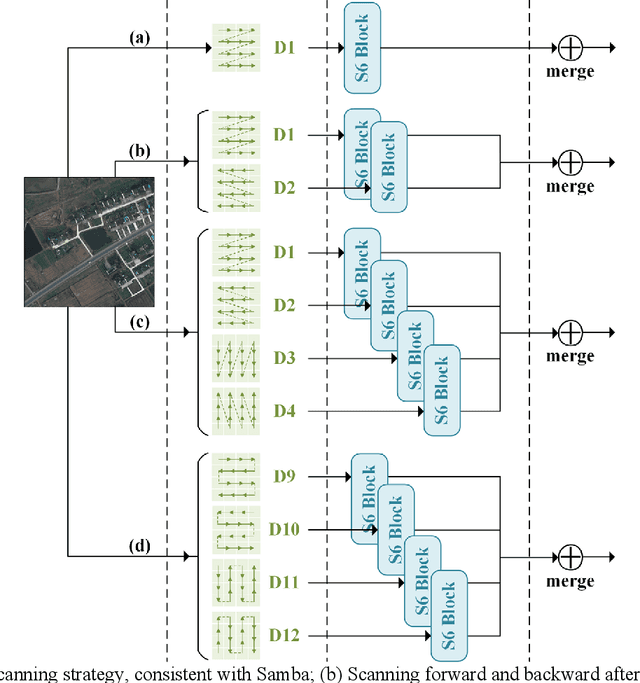
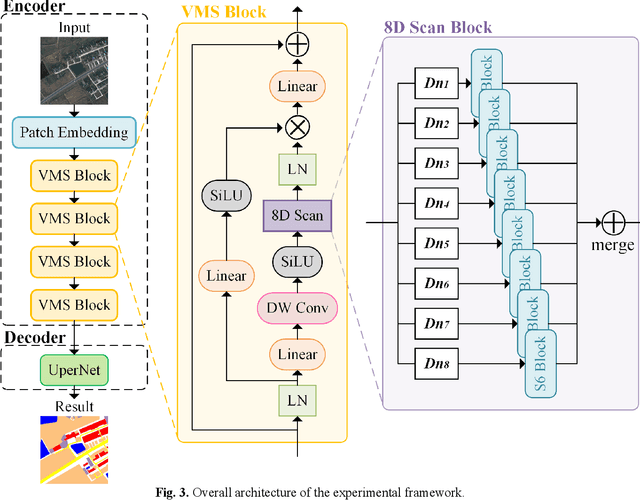
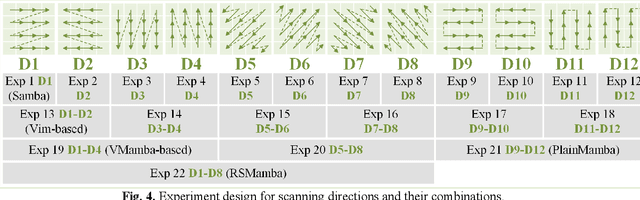
Deep learning methods, especially Convolutional Neural Networks (CNN) and Vision Transformer (ViT), are frequently employed to perform semantic segmentation of high-resolution remotely sensed images. However, CNNs are constrained by their restricted receptive fields, while ViTs face challenges due to their quadratic complexity. Recently, the Mamba model, featuring linear complexity and a global receptive field, has gained extensive attention for vision tasks. In such tasks, images need to be serialized to form sequences compatible with the Mamba model. Numerous research efforts have explored scanning strategies to serialize images, aiming to enhance the Mamba model's understanding of images. However, the effectiveness of these scanning strategies remains uncertain. In this research, we conduct a comprehensive experimental investigation on the impact of mainstream scanning directions and their combinations on semantic segmentation of remotely sensed images. Through extensive experiments on the LoveDA, ISPRS Potsdam, and ISPRS Vaihingen datasets, we demonstrate that no single scanning strategy outperforms others, regardless of their complexity or the number of scanning directions involved. A simple, single scanning direction is deemed sufficient for semantic segmentation of high-resolution remotely sensed images. Relevant directions for future research are also recommended.