 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Forget It! Conditional Sparse Autoencoder Clamping Works for Unlearning
Mar 14, 2025

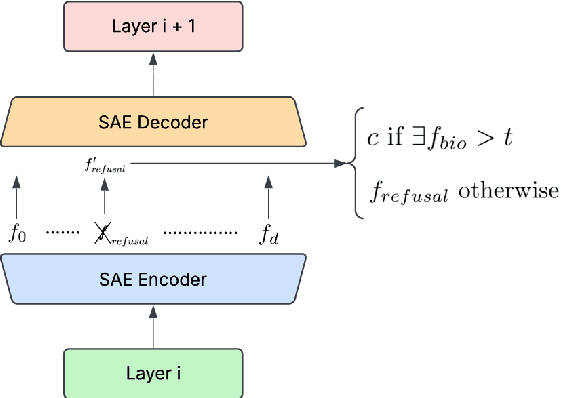

Recent developments in Large Language Model (LLM) capabilities have brought great potential but also posed new risks. For example, LLMs with knowledge of bioweapons, advanced chemistry, or cyberattacks could cause violence if placed in the wrong hands or during malfunctions. Because of their nature as near-black boxes, intuitive interpretation of LLM internals remains an open research question, preventing developers from easily controlling model behavior and capabilities. The use of Sparse Autoencoders (SAEs) has recently emerged as a potential method of unraveling representations of concepts in LLMs internals, and has allowed developers to steer model outputs by directly modifying the hidden activations. In this paper, we use SAEs to identify unwanted concepts from the Weapons of Mass Destruction Proxy (WMDP) dataset within gemma-2-2b internals and use feature steering to reduce the model's ability to answer harmful questions while retaining its performance on harmless queries. Our results bring back optimism to the viability of SAE-based explicit knowledge unlearning techniques.
Can You Trust LLM Judgments? Reliability of LLM-as-a-Judge
Dec 17, 2024



Large Language Models (LLMs) have become increasingly powerful and ubiquitous, but their stochastic nature poses challenges to the reliability of their outputs. While deterministic settings can improve consistency, they do not guarantee reliability, as a single sample from the model's probability distribution can still be misleading. Building upon the concept of LLM-as-a-judge, we introduce a novel framework for rigorously evaluating the reliability of LLM judgments, leveraging McDonald's omega. We evaluate the reliability of LLMs when judging the outputs of other LLMs on standard single-turn and multi-turn benchmarks, simultaneously investigating the impact of temperature on reliability. By analyzing these results, we demonstrate the limitations of fixed randomness and the importance of considering multiple samples, which we show has significant implications for downstream applications. Our findings highlight the need for a nuanced understanding of LLM reliability and the potential risks associated with over-reliance on single-shot evaluations. This work provides a crucial step towards building more trustworthy and reliable LLM-based systems and applications.
Controlling for Unobserved Confounding with Large Language Model Classification of Patient Smoking Status
Nov 05, 2024



Causal understanding is a fundamental goal of evidence-based medicine. When randomization is impossible, causal inference methods allow the estimation of treatment effects from retrospective analysis of observational data. However, such analyses rely on a number of assumptions, often including that of no unobserved confounding. In many practical settings, this assumption is violated when important variables are not explicitly measured in the clinical record. Prior work has proposed to address unobserved confounding with machine learning by imputing unobserved variables and then correcting for the classifier's mismeasurement. When such a classifier can be trained and the necessary assumptions are met, this method can recover an unbiased estimate of a causal effect. However, such work has been limited to synthetic data, simple classifiers, and binary variables. This paper extends this methodology by using a large language model trained on clinical notes to predict patients' smoking status, which would otherwise be an unobserved confounder. We then apply a measurement error correction on the categorical predicted smoking status to estimate the causal effect of transthoracic echocardiography on mortality in the MIMIC dataset.
Reliability of Topic Modeling
Oct 30, 2024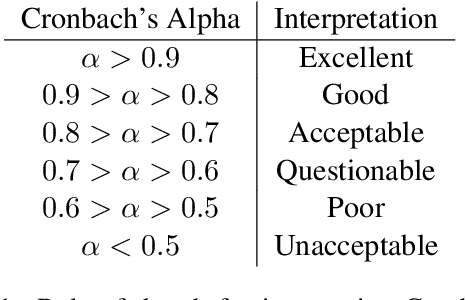
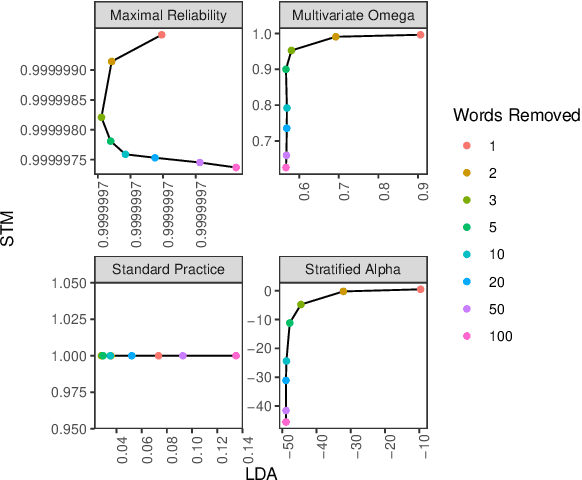
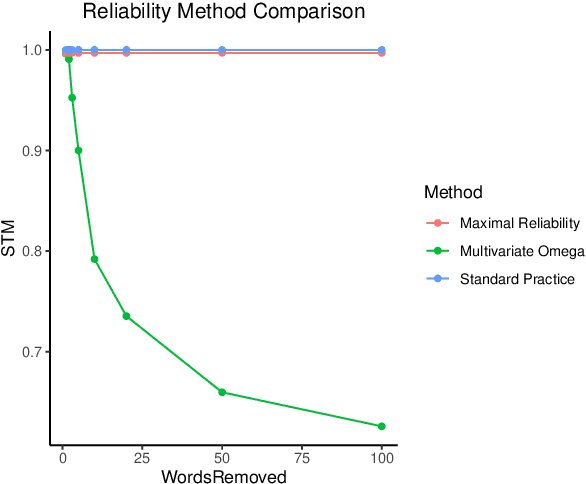
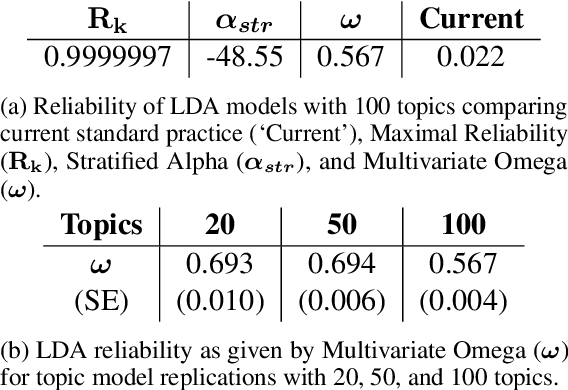
Topic models allow researchers to extract latent factors from text data and use those variables in downstream statistical analyses. However, these methodologies can vary significantly due to initialization differences, randomness in sampling procedures, or noisy data. Reliability of these methods is of particular concern as many researchers treat learned topic models as ground truth for subsequent analyses. In this work, we show that the standard practice for quantifying topic model reliability fails to capture essential aspects of the variation in two widely-used topic models. Drawing from a extensive literature on measurement theory, we provide empirical and theoretical analyses of three other metrics for evaluating the reliability of topic models. On synthetic and real-world data, we show that McDonald's $\omega$ provides the best encapsulation of reliability. This metric provides an essential tool for validation of topic model methodologies that should be a standard component of any topic model-based research.
Segment Anything Model is a Good Teacher for Local Feature Learning
Sep 29, 2023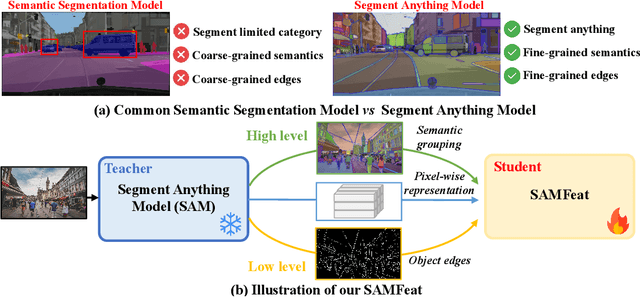
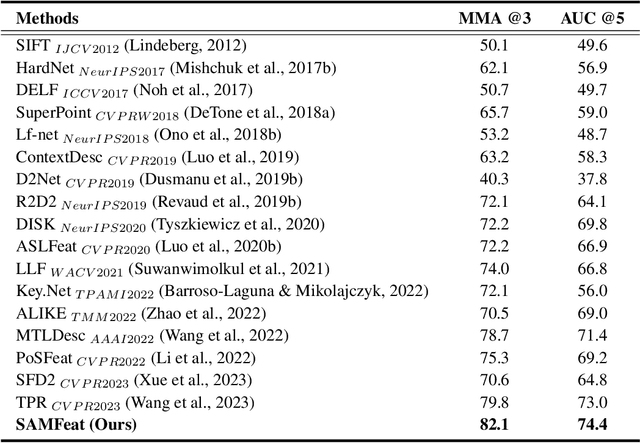
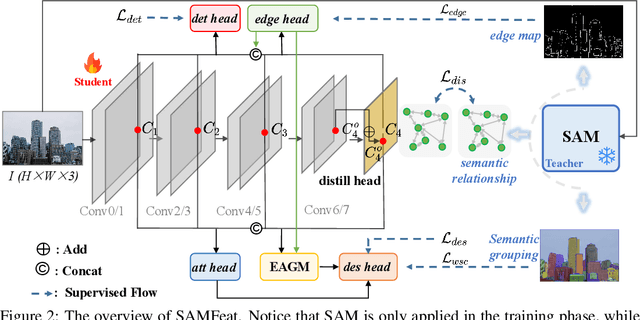
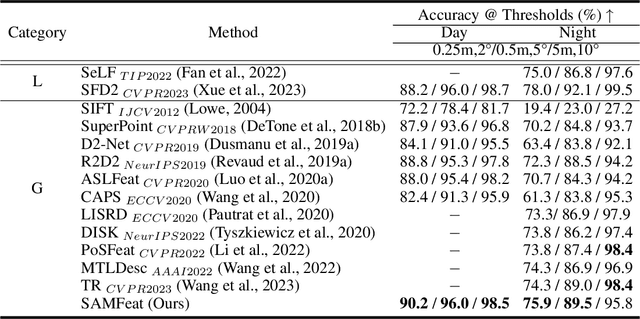
Local feature detection and description play an important role in many computer vision tasks, which are designed to detect and describe keypoints in "any scene" and "any downstream task". Data-driven local feature learning methods need to rely on pixel-level correspondence for training, which is challenging to acquire at scale, thus hindering further improvements in performance. In this paper, we propose SAMFeat to introduce SAM (segment anything model), a fundamental model trained on 11 million images, as a teacher to guide local feature learning and thus inspire higher performance on limited datasets. To do so, first, we construct an auxiliary task of Pixel Semantic Relational Distillation (PSRD), which distillates feature relations with category-agnostic semantic information learned by the SAM encoder into a local feature learning network, to improve local feature description using semantic discrimination. Second, we develop a technique called Weakly Supervised Contrastive Learning Based on Semantic Grouping (WSC), which utilizes semantic groupings derived from SAM as weakly supervised signals, to optimize the metric space of local descriptors. Third, we design an Edge Attention Guidance (EAG) to further improve the accuracy of local feature detection and description by prompting the network to pay more attention to the edge region guided by SAM. SAMFeat's performance on various tasks such as image matching on HPatches, and long-term visual localization on Aachen Day-Night showcases its superiority over previous local features. The release code is available at https://github.com/vignywang/SAMFeat.
Causal Inference in Natural Language Processing: Estimation, Prediction, Interpretation and Beyond
Sep 02, 2021
A fundamental goal of scientific research is to learn about causal relationships. However, despite its critical role in the life and social sciences, causality has not had the same importance in Natural Language Processing (NLP), which has traditionally placed more emphasis on predictive tasks. This distinction is beginning to fade, with an emerging area of interdisciplinary research at the convergence of causal inference and language processing. Still, research on causality in NLP remains scattered across domains without unified definitions, benchmark datasets and clear articulations of the remaining challenges. In this survey, we consolidate research across academic areas and situate it in the broader NLP landscape. We introduce the statistical challenge of estimating causal effects, encompassing settings where text is used as an outcome, treatment, or as a means to address confounding. In addition, we explore potential uses of causal inference to improve the performance, robustness, fairness, and interpretability of NLP models. We thus provide a unified overview of causal inference for the computational linguistics community.
The Proximal ID Algorithm
Aug 15, 2021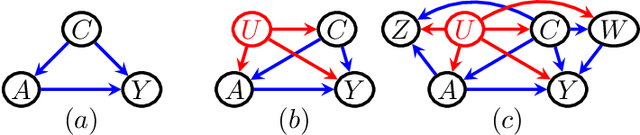
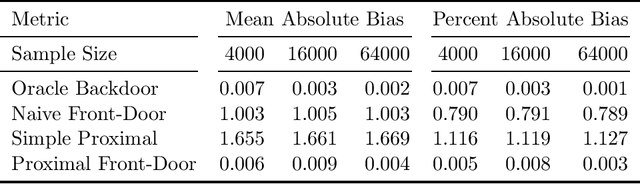


Unobserved confounding is a fundamental obstacle to establishing valid causal conclusions from observational data. Two complementary types of approaches have been developed to address this obstacle. An extensive line of work is based on taking advantage of fortuitous external aids (such as the presence of an instrumental variable or other proxy), along with additional assumptions to ensure identification. A recent line of work of proximal causal inference (Miao et al., 2018a) has aimed to provide a novel approach to using proxies to deal with unobserved confounding without relying on stringent parametric assumptions. On the other hand, a complete characterization of identifiability of a large class of causal parameters in arbitrary causal models with hidden variables has been developed using the language of graphical models, resulting in the ID algorithm and related extensions (Tian and Pearl, 2002; Shpitser and Pearl, 2006a,b). Celebrated special cases of this approach, such as the front-door model, are able to obtain non-parametric identification in seemingly counter-intuitive situations when a treatment and an outcome share an arbitrarily complicated unobserved common cause. In this paper we aim to develop a synthesis of the proximal and graphical approaches to identification in causal inference to yield the most general identification algorithm in multi- variate systems currently known - the proximal ID algorithm. In addition to being able to obtain non-parametric identification in all cases where the ID algorithm succeeds, our approach allows us to systematically exploit proxies to adjust for the presence of unobserved confounders that would have otherwise prevented identification. In addition, we outline a class of estimation strategies for causal parameters identified by our method in an important special case. We illustration our approach by simulation studies.
Faithful and Plausible Explanations of Medical Code Predictions
Apr 16, 2021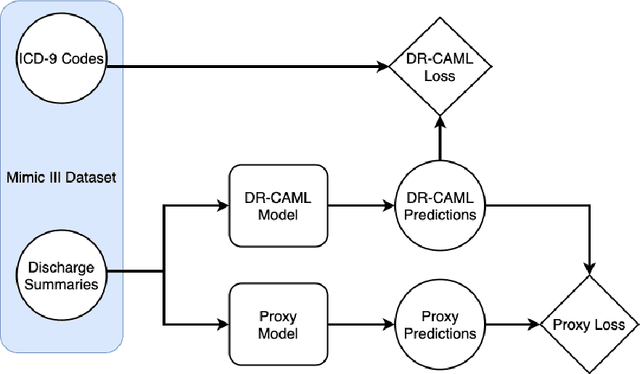

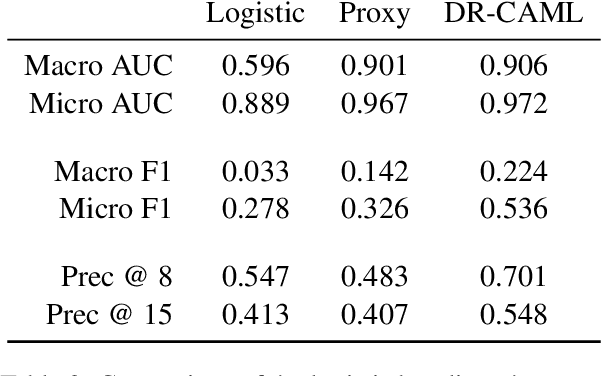
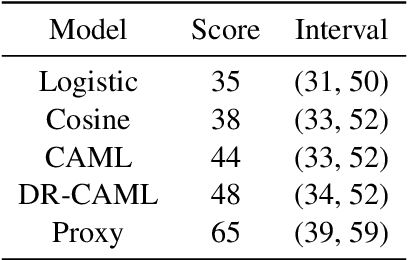
Machine learning models that offer excellent predictive performance often lack the interpretability necessary to support integrated human machine decision-making. In clinical medicine and other high-risk settings, domain experts may be unwilling to trust model predictions without explanations. Work in explainable AI must balance competing objectives along two different axes: 1) Explanations must balance faithfulness to the model's decision-making with their plausibility to a domain expert. 2) Domain experts desire local explanations of individual predictions and global explanations of behavior in aggregate. We propose to train a proxy model that mimics the behavior of the trained model and provides fine-grained control over these trade-offs. We evaluate our approach on the task of assigning ICD codes to clinical notes to demonstrate that explanations from the proxy model are faithful and replicate the trained model behavior.
Generating Synthetic Text Data to Evaluate Causal Inference Methods
Feb 10, 2021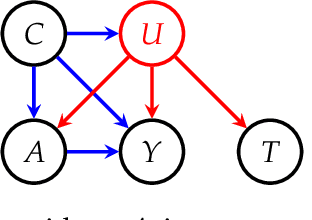



Drawing causal conclusions from observational data requires making assumptions about the true data-generating process. Causal inference research typically considers low-dimensional data, such as categorical or numerical fields in structured medical records. High-dimensional and unstructured data such as natural language complicates the evaluation of causal inference methods; such evaluations rely on synthetic datasets with known causal effects. Models for natural language generation have been widely studied and perform well empirically. However, existing methods not immediately applicable to producing synthetic datasets for causal evaluations, as they do not allow for quantifying a causal effect on the text itself. In this work, we develop a framework for adapting existing generation models to produce synthetic text datasets with known causal effects. We use this framework to perform an empirical comparison of four recently-proposed methods for estimating causal effects from text data. We release our code and synthetic datasets.
Demographic Representation and Collective Storytelling in the Me Too Twitter Hashtag Activism Movement
Oct 13, 2020
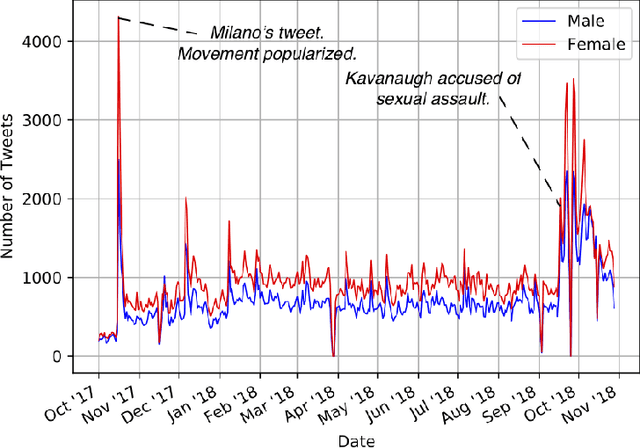


The #MeToo movement on Twitter has drawn attention to the pervasive nature of sexual harassment and violence. While #MeToo has been praised for providing support for self-disclosures of harassment or violence and shifting societal response, it has also been criticized for exemplifying how women of color have been discounted for their historical contributions to and excluded from feminist movements. Through an analysis of over 600,000 tweets from over 256,000 unique users, we examine online #MeToo conversations across gender and racial/ethnic identities and the topics that each demographic emphasized. We found that tweets authored by white women were overrepresented in the movement compared to other demographics, aligning with criticism of unequal representation. We found that intersected identities contributed differing narratives to frame the movement, co-opted the movement to raise visibility in parallel ongoing movements, employed the same hashtags both critically and supportively, and revived and created new hashtags in response to pivotal moments. Notably, tweets authored by black women often expressed emotional support and were critical about differential treatment in the justice system and by police. In comparison, tweets authored by white women and men often highlighted sexual harassment and violence by public figures and weaved in more general political discussions. We discuss the implications of work for digital activism research and design including suggestions to raise visibility by those who were under-represented in this hashtag activism movement. Content warning: this article discusses issues of sexual harassment and violence.