 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliability of Topic Modeling
Paper and Code
Oct 30, 2024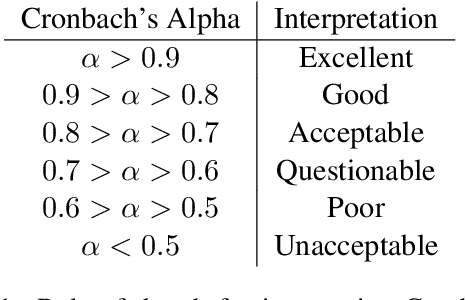
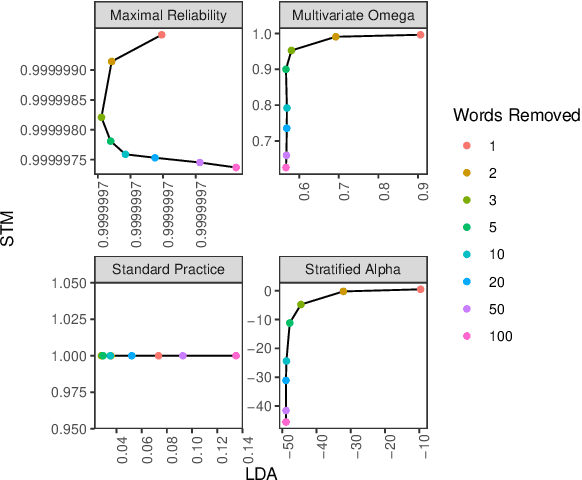
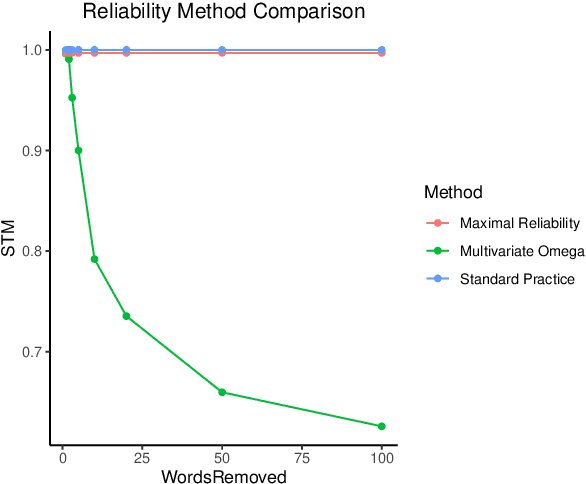
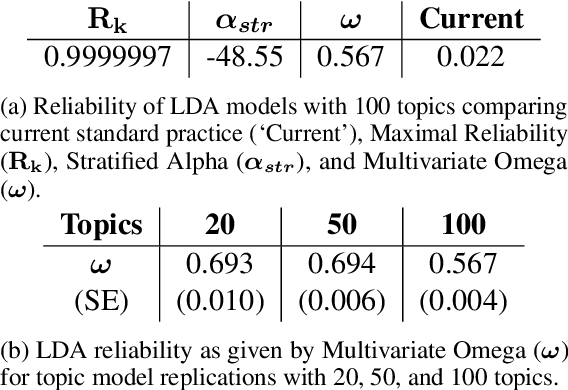
Topic models allow researchers to extract latent factors from text data and use those variables in downstream statistical analyses. However, these methodologies can vary significantly due to initialization differences, randomness in sampling procedures, or noisy data. Reliability of these methods is of particular concern as many researchers treat learned topic models as ground truth for subsequent analyses. In this work, we show that the standard practice for quantifying topic model reliability fails to capture essential aspects of the variation in two widely-used topic models. Drawing from a extensive literature on measurement theory, we provide empirical and theoretical analyses of three other metrics for evaluating the reliability of topic models. On synthetic and real-world data, we show that McDonald's $\omega$ provides the best encapsulation of reliability. This metric provides an essential tool for validation of topic model methodologies that should be a standard component of any topic model-based research.