 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDark-EvGS: Event Camera as an Eye for Radiance Field in the Dark
Jul 16, 2025



In low-light environments, conventional cameras often struggle to capture clear multi-view images of objects due to dynamic range limitations and motion blur caused by long exposure. Event cameras, with their high-dynamic range and high-speed properties, have the potential to mitigate these issues. Additionally, 3D Gaussian Splatting (GS) enables radiance field reconstruction, facilitating bright frame synthesis from multiple viewpoints in low-light conditions. However, naively using an event-assisted 3D GS approach still faced challenges because, in low light, events are noisy, frames lack quality, and the color tone may be inconsistent. To address these issues, we propose Dark-EvGS, the first event-assisted 3D GS framework that enables the reconstruction of bright frames from arbitrary viewpoints along the camera trajectory. Triplet-level supervision is proposed to gain holistic knowledge, granular details, and sharp scene rendering. The color tone matching block is proposed to guarantee the color consistency of the rendered frames. Furthermore, we introduce the first real-captured dataset for the event-guided bright frame synthesis task via 3D GS-based radiance field reconstruction. Experiments demonstrate that our method achieves better results than existing methods, conquering radiance field reconstruction under challenging low-light conditions. The code and sample data are included in the supplementary material.
SweepEvGS: Event-Based 3D Gaussian Splatting for Macro and Micro Radiance Field Rendering from a Single Sweep
Dec 16, 2024



Recent advancements in 3D Gaussian Splatting (3D-GS) have demonstrated the potential of using 3D Gaussian primitives for high-speed, high-fidelity, and cost-efficient novel view synthesis from continuously calibrated input views. However, conventional methods require high-frame-rate dense and high-quality sharp images, which are time-consuming and inefficient to capture, especially in dynamic environments. Event cameras, with their high temporal resolution and ability to capture asynchronous brightness changes, offer a promising alternative for more reliable scene reconstruction without motion blur. In this paper, we propose SweepEvGS, a novel hardware-integrated method that leverages event cameras for robust and accurate novel view synthesis across various imaging settings from a single sweep. SweepEvGS utilizes the initial static frame with dense event streams captured during a single camera sweep to effectively reconstruct detailed scene views. We also introduce different real-world hardware imaging systems for real-world data collection and evaluation for future research. We validate the robustness and efficiency of SweepEvGS through experiments in three different imaging settings: synthetic objects, real-world macro-level, and real-world micro-level view synthesis. Our results demonstrate that SweepEvGS surpasses existing methods in visual rendering quality, rendering speed, and computational efficiency, highlighting its potential for dynamic practical applications.
Ev-GS: Event-based Gaussian splatting for Efficient and Accurate Radiance Field Rendering
Jul 16, 2024



Computational neuromorphic imaging (CNI) with event cameras offers advantages such as minimal motion blur and enhanced dynamic range, compared to conventional frame-based methods. Existing event-based radiance field rendering methods are built on neural radiance field, which is computationally heavy and slow in reconstruction speed. Motivated by the two aspects, we introduce Ev-GS, the first CNI-informed scheme to infer 3D Gaussian splatting from a monocular event camera, enabling efficient novel view synthesis. Leveraging 3D Gaussians with pure event-based supervision, Ev-GS overcomes challenges such as the detection of fast-moving objects and insufficient lighting. Experimental results show that Ev-GS outperforms the method that takes frame-based signals as input by rendering realistic views with reduced blurring and improved visual quality. Moreover, it demonstrates competitive reconstruction quality and reduced computing occupancy compared to existing methods, which paves the way to a highly efficient CNI approach for signal processing.
Segment Anything Model is a Good Teacher for Local Feature Learning
Sep 29, 2023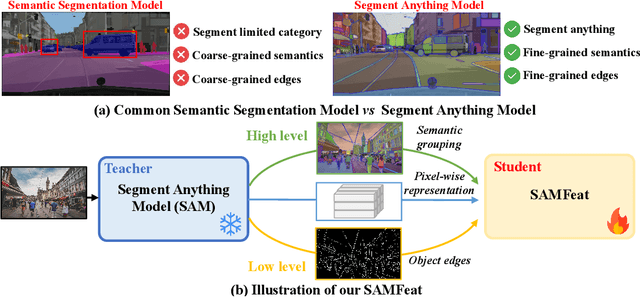
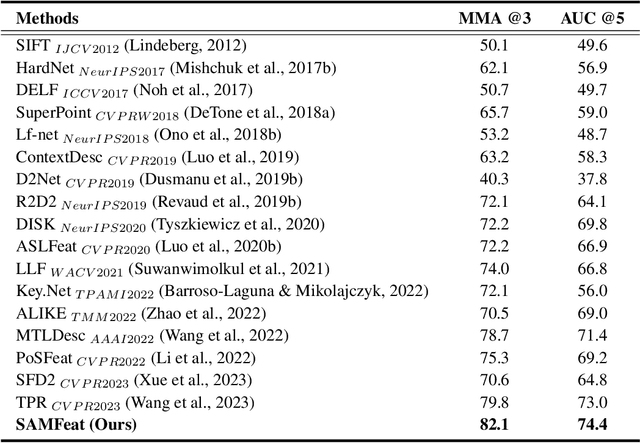
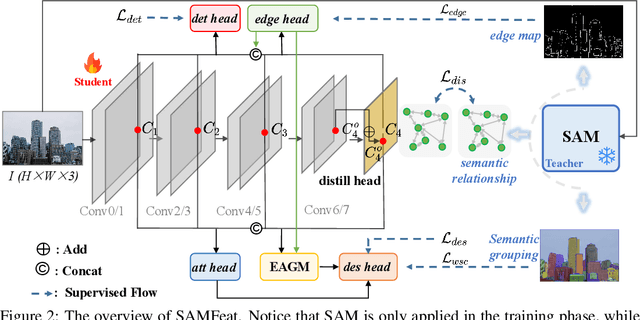
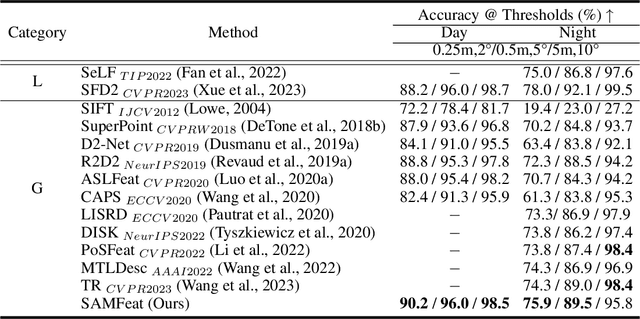
Local feature detection and description play an important role in many computer vision tasks, which are designed to detect and describe keypoints in "any scene" and "any downstream task". Data-driven local feature learning methods need to rely on pixel-level correspondence for training, which is challenging to acquire at scale, thus hindering further improvements in performance. In this paper, we propose SAMFeat to introduce SAM (segment anything model), a fundamental model trained on 11 million images, as a teacher to guide local feature learning and thus inspire higher performance on limited datasets. To do so, first, we construct an auxiliary task of Pixel Semantic Relational Distillation (PSRD), which distillates feature relations with category-agnostic semantic information learned by the SAM encoder into a local feature learning network, to improve local feature description using semantic discrimination. Second, we develop a technique called Weakly Supervised Contrastive Learning Based on Semantic Grouping (WSC), which utilizes semantic groupings derived from SAM as weakly supervised signals, to optimize the metric space of local descriptors. Third, we design an Edge Attention Guidance (EAG) to further improve the accuracy of local feature detection and description by prompting the network to pay more attention to the edge region guided by SAM. SAMFeat's performance on various tasks such as image matching on HPatches, and long-term visual localization on Aachen Day-Night showcases its superiority over previous local features. The release code is available at https://github.com/vignywang/SAMFeat.
An Encoder-Decoder Based Audio Captioning System With Transfer and Reinforcement Learning
Aug 05, 2021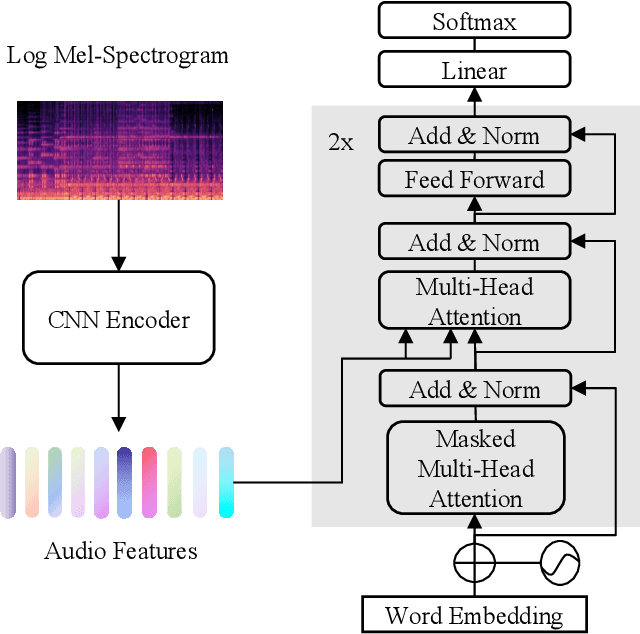
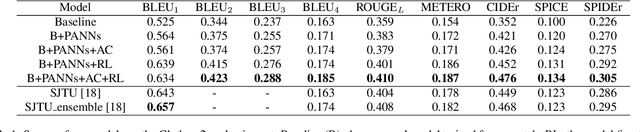


Automated audio captioning aims to use natural language to describe the content of audio data. This paper presents an audio captioning system with an encoder-decoder architecture, where the decoder predicts words based on audio features extracted by the encoder. To improve the proposed system, transfer learning from either an upstream audio-related task or a large in-domain dataset is introduced to mitigate the problem induced by data scarcity. Besides, evaluation metrics are incorporated into the optimization of the model with reinforcement learning, which helps address the problem of ``exposure bias'' induced by ``teacher forcing'' training strategy and the mismatch between the evaluation metrics and the loss function. The resulting system was ranked 3rd in DCASE 2021 Task 6. Ablation studies are carried out to investigate how much each element in the proposed system can contribute to final performance. The results show that the proposed techniques significantly improve the scores of the evaluation metrics, however, reinforcement learning may impact adversely on the quality of the generated captions.