 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Reducing Bias in a High Stakes Domain
Aug 29, 2019
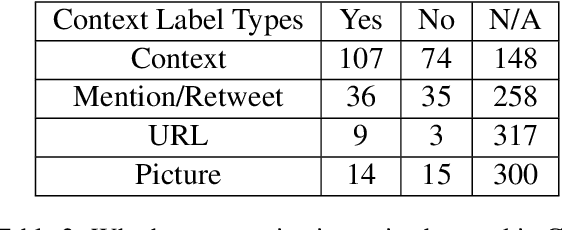
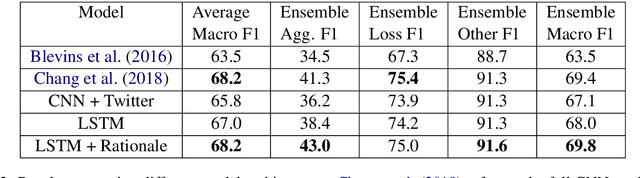
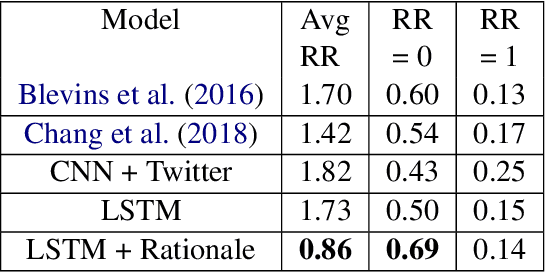
Gang-involved youth in cities such as Chicago sometimes post on social media to express their aggression towards rival gangs and previous research has demonstrated that a deep learning approach can predict aggression and loss in posts. To address the possibility of bias in this sensitive application, we developed an approach to systematically interpret the state of the art model. We found, surprisingly, that it frequently bases its predictions on stop words such as "a" or "on", an approach that could harm social media users who have no aggressive intentions. To tackle this bias, domain experts annotated the rationales, highlighting words that explain why a tweet is labeled as "aggression". These new annotations enable us to quantitatively measure how justified the model predictions are, and build models that drastically reduce bias. Our study shows that in high stake scenarios, accuracy alone cannot guarantee a good system and we need new evaluation methods.