 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASIVE: Open-Ended Affective State Identification in English and Spanish
Jul 16, 2024In the field of emotion analysis, much NLP research focuses on identifying a limited number of discrete emotion categories, often applied across languages. These basic sets, however, are rarely designed with textual data in mind, and culture, language, and dialect can influence how particular emotions are interpreted. In this work, we broaden our scope to a practically unbounded set of \textit{affective states}, which includes any terms that humans use to describe their experiences of feeling. We collect and publish MASIVE, a dataset of Reddit posts in English and Spanish containing over 1,000 unique affective states each. We then define the new problem of \textit{affective state identification} for language generation models framed as a masked span prediction task. On this task, we find that smaller finetuned multilingual models outperform much larger LLMs, even on region-specific Spanish affective states. Additionally, we show that pretraining on MASIVE improves model performance on existing emotion benchmarks. Finally, through machine translation experiments, we find that native speaker-written data is vital to good performance on this task.
Evaluating the Effectiveness of Data Augmentation for Emotion Classification in Low-Resource Settings
Jun 07, 2024



Data augmentation has the potential to improve the performance of machine learning models by increasing the amount of training data available. In this study, we evaluated the effectiveness of different data augmentation techniques for a multi-label emotion classification task using a low-resource dataset. Our results showed that Back Translation outperformed autoencoder-based approaches and that generating multiple examples per training instance led to further performance improvement. In addition, we found that Back Translation generated the most diverse set of unigrams and trigrams. These findings demonstrate the utility of Back Translation in enhancing the performance of emotion classification models in resource-limited situations.
Evaluation of African American Language Bias in Natural Language Generation
May 23, 2023



We evaluate how well LLMs understand African American Language (AAL) in comparison to their performance on White Mainstream English (WME), the encouraged "standard" form of English taught in American classrooms. We measure LLM performance using automatic metrics and human judgments for two tasks: a counterpart generation task, where a model generates AAL (or WME) given WME (or AAL), and a masked span prediction (MSP) task, where models predict a phrase that was removed from their input. Our contributions include: (1) evaluation of six pre-trained, large language models on the two language generation tasks; (2) a novel dataset of AAL text from multiple contexts (social media, hip-hop lyrics, focus groups, and linguistic interviews) with human-annotated counterparts in WME; and (3) documentation of model performance gaps that suggest bias and identification of trends in lack of understanding of AAL features.
Multi-Task Learning and Adapted Knowledge Models for Emotion-Cause Extraction
Jun 17, 2021



Detecting what emotions are expressed in text is a well-studied problem in natural language processing. However, research on finer grained emotion analysis such as what causes an emotion is still in its infancy. We present solutions that tackle both emotion recognition and emotion cause detection in a joint fashion. Considering that common-sense knowledge plays an important role in understanding implicitly expressed emotions and the reasons for those emotions, we propose novel methods that combine common-sense knowledge via adapted knowledge models with multi-task learning to perform joint emotion classification and emotion cause tagging. We show performance improvement on both tasks when including common-sense reasoning and a multitask framework. We provide a thorough analysis to gain insights into model performance.
Segmenting Subtitles for Correcting ASR Segmentation Errors
Apr 16, 2021
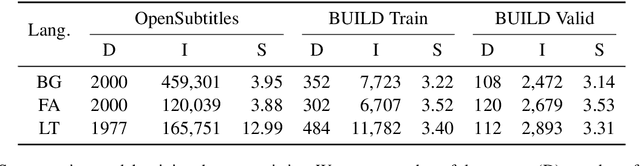

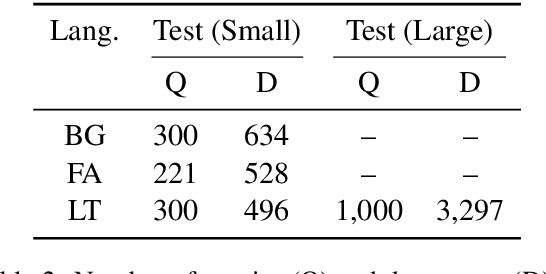
Typical ASR systems segment the input audio into utterances using purely acoustic information, which may not resemble the sentence-like units that are expected by conventional machine translation (MT) systems for Spoken Language Translation. In this work, we propose a model for correcting the acoustic segmentation of ASR models for low-resource languages to improve performance on downstream tasks. We propose the use of subtitles as a proxy dataset for correcting ASR acoustic segmentation, creating synthetic acoustic utterances by modeling common error modes. We train a neural tagging model for correcting ASR acoustic segmentation and show that it improves downstream performance on MT and audio-document cross-language information retrieval (CLIR).
Subtitles to Segmentation: Improving Low-Resource Speech-to-Text Translation Pipelines
Oct 19, 2020

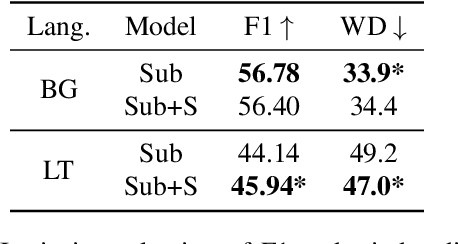

In this work, we focus on improving ASR output segmentation in the context of low-resource language speech-to-text translation. ASR output segmentation is crucial, as ASR systems segment the input audio using purely acoustic information and are not guaranteed to output sentence-like segments. Since most MT systems expect sentences as input, feeding in longer unsegmented passages can lead to sub-optimal performance. We explore the feasibility of using datasets of subtitles from TV shows and movies to train better ASR segmentation models. We further incorporate part-of-speech (POS) tag and dependency label information (derived from the unsegmented ASR outputs) into our segmentation model. We show that this noisy syntactic information can improve model accuracy. We evaluate our models intrinsically on segmentation quality and extrinsically on downstream MT performance, as well as downstream tasks including cross-lingual information retrieval (CLIR) tasks and human relevance assessments. Our model shows improved performance on downstream tasks for Lithuanian and Bulgarian.
Dreaddit: A Reddit Dataset for Stress Analysis in Social Media
Oct 31, 2019



Stress is a nigh-universal human experience, particularly in the online world. While stress can be a motivator, too much stress is associated with many negative health outcomes, making its identification useful across a range of domains. However, existing computational research typically only studies stress in domains such as speech, or in short genres such as Twitter. We present Dreaddit, a new text corpus of lengthy multi-domain social media data for the identification of stress. Our dataset consists of 190K posts from five different categories of Reddit communities; we additionally label 3.5K total segments taken from 3K posts using Amazon Mechanical Turk. We present preliminary supervised learning methods for identifying stress, both neural and traditional, and analyze the complexity and diversity of the data and characteristics of each category.