 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocument-Level Supervision for Multi-Aspect Sentiment Analysis Without Fine-grained Labels
Oct 10, 2023Aspect-based sentiment analysis (ABSA) is a widely studied topic, most often trained through supervision from human annotations of opinionated texts. These fine-grained annotations include identifying aspects towards which a user expresses their sentiment, and their associated polarities (aspect-based sentiments). Such fine-grained annotations can be expensive and often infeasible to obtain in real-world settings. There is, however, an abundance of scenarios where user-generated text contains an overall sentiment, such as a rating of 1-5 in user reviews or user-generated feedback, which may be leveraged for this task. In this paper, we propose a VAE-based topic modeling approach that performs ABSA using document-level supervision and without requiring fine-grained labels for either aspects or sentiments. Our approach allows for the detection of multiple aspects in a document, thereby allowing for the possibility of reasoning about how sentiment expressed through multiple aspects comes together to form an observable overall document-level sentiment. We demonstrate results on two benchmark datasets from two different domains, significantly outperforming a state-of-the-art baseline.
Multi-Task Learning and Adapted Knowledge Models for Emotion-Cause Extraction
Jun 17, 2021



Detecting what emotions are expressed in text is a well-studied problem in natural language processing. However, research on finer grained emotion analysis such as what causes an emotion is still in its infancy. We present solutions that tackle both emotion recognition and emotion cause detection in a joint fashion. Considering that common-sense knowledge plays an important role in understanding implicitly expressed emotions and the reasons for those emotions, we propose novel methods that combine common-sense knowledge via adapted knowledge models with multi-task learning to perform joint emotion classification and emotion cause tagging. We show performance improvement on both tasks when including common-sense reasoning and a multitask framework. We provide a thorough analysis to gain insights into model performance.
To BERT or Not to BERT: Comparing Task-specific and Task-agnostic Semi-Supervised Approaches for Sequence Tagging
Oct 27, 2020



Leveraging large amounts of unlabeled data using Transformer-like architectures, like BERT, has gained popularity in recent times owing to their effectiveness in learning general representations that can then be further fine-tuned for downstream tasks to much success. However, training these models can be costly both from an economic and environmental standpoint. In this work, we investigate how to effectively use unlabeled data: by exploring the task-specific semi-supervised approach, Cross-View Training (CVT) and comparing it with task-agnostic BERT in multiple settings that include domain and task relevant English data. CVT uses a much lighter model architecture and we show that it achieves similar performance to BERT on a set of sequence tagging tasks, with lesser financial and environmental impact.
Neural Word Decomposition Models for Abusive Language Detection
Oct 02, 2019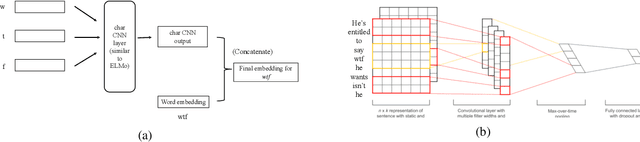
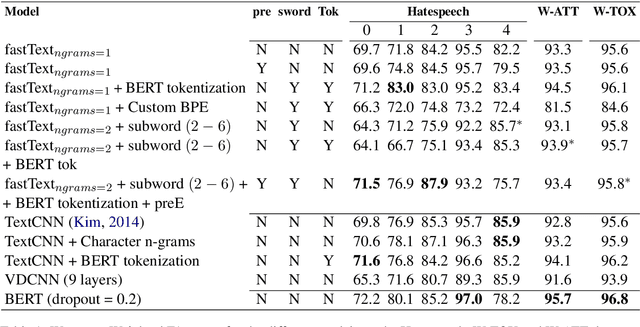
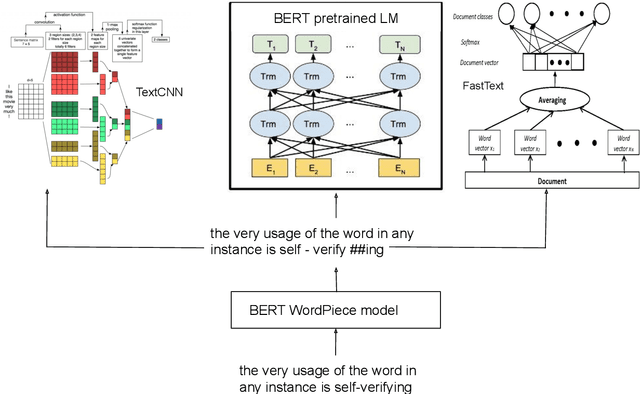
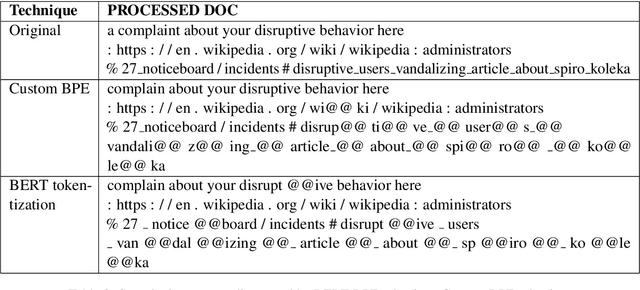
User generated text on social media often suffers from a lot of undesired characteristics including hatespeech, abusive language, insults etc. that are targeted to attack or abuse a specific group of people. Often such text is written differently compared to traditional text such as news involving either explicit mention of abusive words, obfuscated words and typological errors or implicit abuse i.e., indicating or targeting negative stereotypes. Thus, processing this text poses several robustness challenges when we apply natural language processing techniques developed for traditional text. For example, using word or token based models to process such text can treat two spelling variants of a word as two different words. Following recent work, we analyze how character, subword and byte pair encoding (BPE) models can be aid some of the challenges posed by user generated text. In our work, we analyze the effectiveness of each of the above techniques, compare and contrast various word decomposition techniques when used in combination with others. We experiment with finetuning large pretrained language models, and demonstrate their robustness to domain shift by studying Wikipedia attack, toxicity and Twitter hatespeech datasets
* Accepted at ALW Workshop at ACL2019, Florence; BERT has a WordPiece model and it enhances performance of word based models in noisy settings