 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion Strategies for Learning User Embeddings with Neural Networks
Jan 08, 2019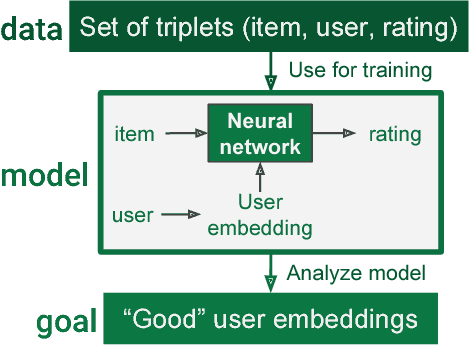
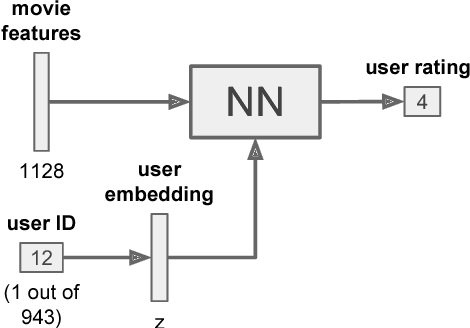
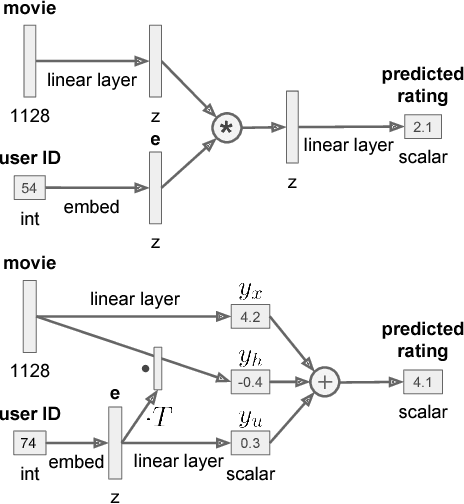
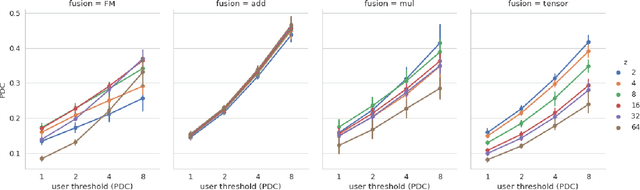
Growing amounts of online user data motivate the need for automated processing techniques. In case of user ratings, one interesting option is to use neural networks for learning to predict ratings given an item and a user. While training for prediction, such an approach at the same time learns to map each user to a vector, a so-called user embedding. Such embeddings can for example be valuable for estimating user similarity. However, there are various ways how item and user information can be combined in neural networks, and it is unclear how the way of combining affects the resulting embeddings. In this paper, we run an experiment on movie ratings data, where we analyze the effect on embedding quality caused by several fusion strategies in neural networks. For evaluating embedding quality, we propose a novel measure, Pair-Distance Correlation, which quantifies the condition that similar users should have similar embedding vectors. We find that the fusion strategy affects results in terms of both prediction performance and embedding quality. Surprisingly, we find that prediction performance not necessarily reflects embedding quality. This suggests that if embeddings are of interest, the common tendency to select models based on their prediction ability should be reconsidered.
An Overview of Computational Approaches for Analyzing Interpretation
Nov 09, 2018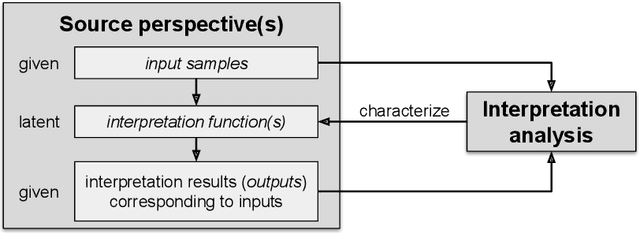
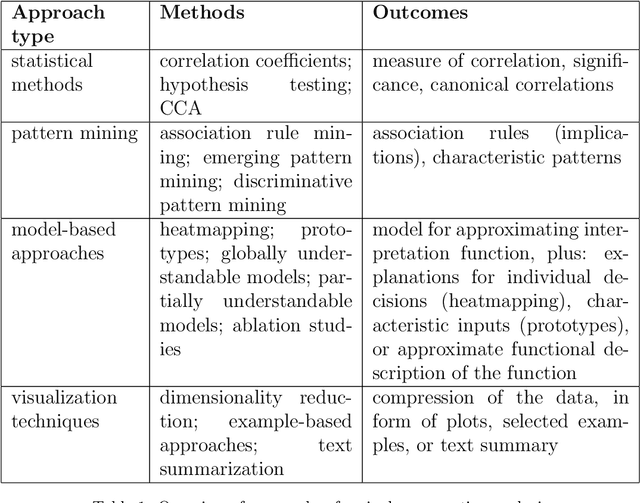
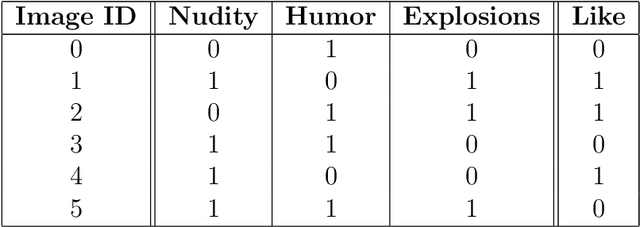

It is said that beauty is in the eye of the beholder. But how exactly can we characterize such discrepancies in interpretation? For example, are there any specific features of an image that makes person A regard an image as beautiful while person B finds the same image displeasing? Such questions ultimately aim at explaining our individual ways of interpretation, an intention that has been of fundamental importance to the social sciences from the beginning. More recently, advances in computer science brought up two related questions: First, can computational tools be adopted for analyzing ways of interpretation? Second, what if the "beholder" is a computer model, i.e., how can we explain a computer model's point of view? Numerous efforts have been made regarding both of these points, while many existing approaches focus on particular aspects and are still rather separate. With this paper, in order to connect these approaches we introduce a theoretical framework for analyzing interpretation, which is applicable to interpretation of both human beings and computer models. We give an overview of relevant computational approaches from various fields, and discuss the most common and promising application areas. The focus of this paper lies on interpretation of text and image data, while many of the presented approaches are applicable to other types of data as well.
The Focus-Aspect-Polarity Model for Predicting Subjective Noun Attributes in Images
Oct 15, 2018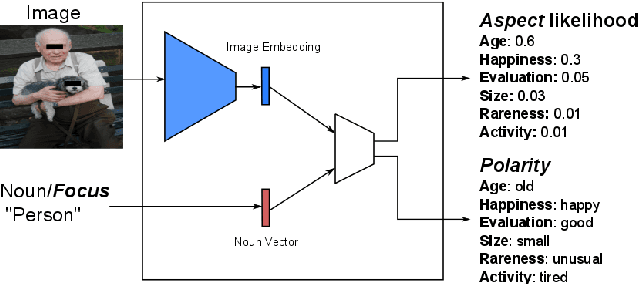

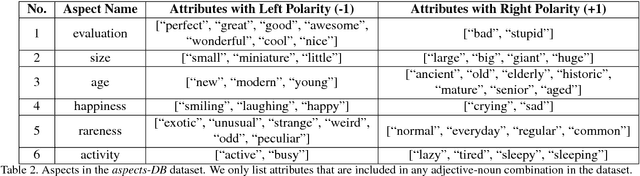
Subjective visual interpretation is a challenging yet important topic in computer vision. Many approaches reduce this problem to the prediction of adjective- or attribute-labels from images. However, most of these do not take attribute semantics into account, or only process the image in a holistic manner. Furthermore, there is a lack of relevant datasets with fine-grained subjective labels. In this paper, we propose the Focus-Aspect-Polarity model to structure the process of capturing subjectivity in image processing, and introduce a novel dataset following this way of modeling. We run experiments on this dataset to compare several deep learning methods and find that incorporating context information based on tensor multiplication in several cases outperforms the default way of information fusion (concatenation).
Multimodal Social Media Analysis for Gang Violence Prevention
Jul 23, 2018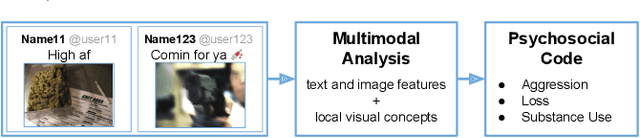
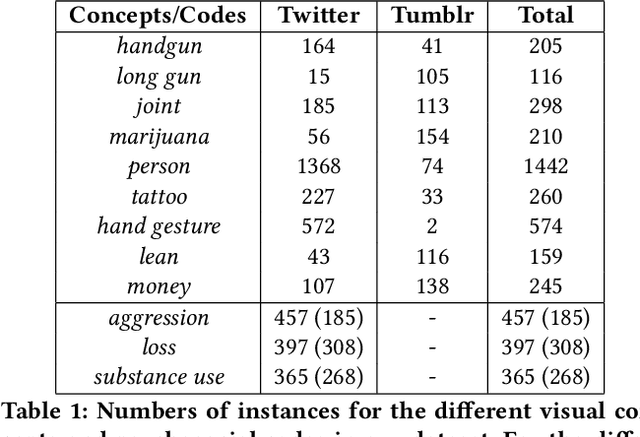

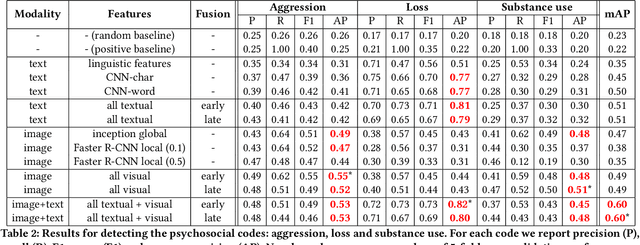
Gang violence is a severe issue in major cities across the U.S. and recent studies [Patton et al. 2017] have found evidence of social media communications that can be linked to such violence in communities with high rates of exposure to gang activity. In this paper we partnered computer scientists with social work researchers, who have domain expertise in gang violence, to analyze how public tweets with images posted by youth who mention gang associations on Twitter can be leveraged to automatically detect psychosocial factors and conditions that could potentially assist social workers and violence outreach workers in prevention and early intervention programs. To this end, we developed a rigorous methodology for collecting and annotating tweets. We gathered 1,851 tweets and accompanying annotations related to visual concepts and the psychosocial codes: aggression, loss, and substance use. These codes are relevant to social work interventions, as they represent possible pathways to violence on social media. We compare various methods for classifying tweets into these three classes, using only the text of the tweet, only the image of the tweet, or both modalities as input to the classifier. In particular, we analyze the usefulness of mid-level visual concepts and the role of different modalities for this tweet classification task. Our experiments show that individually, text information dominates classification performance of the loss class, while image information dominates the aggression and substance use classes. Our multimodal approach provides a very promising improvement (18% relative in mean average precision) over the best single modality approach. Finally, we also illustrate the complexity of understanding social media data and elaborate on open challenges.