 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Focus-Aspect-Polarity Model for Predicting Subjective Noun Attributes in Images
Paper and Code
Oct 15, 2018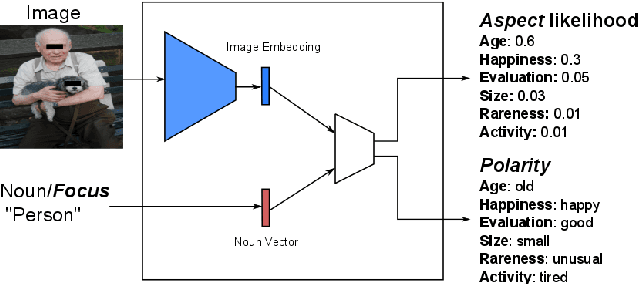

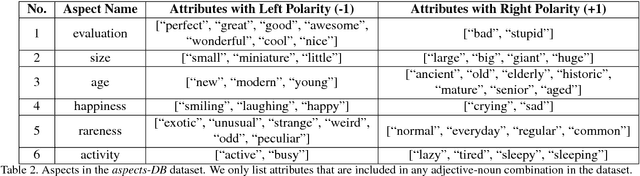
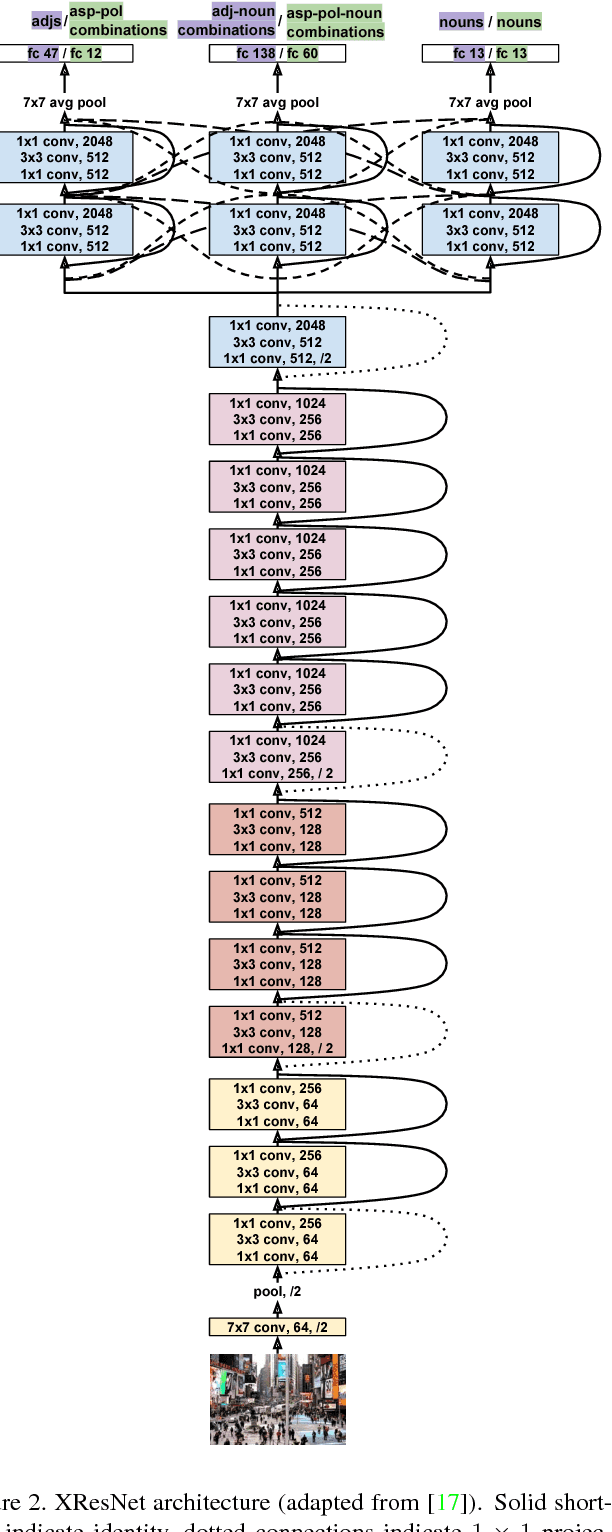
Subjective visual interpretation is a challenging yet important topic in computer vision. Many approaches reduce this problem to the prediction of adjective- or attribute-labels from images. However, most of these do not take attribute semantics into account, or only process the image in a holistic manner. Furthermore, there is a lack of relevant datasets with fine-grained subjective labels. In this paper, we propose the Focus-Aspect-Polarity model to structure the process of capturing subjectivity in image processing, and introduce a novel dataset following this way of modeling. We run experiments on this dataset to compare several deep learning methods and find that incorporating context information based on tensor multiplication in several cases outperforms the default way of information fusion (concatenation).