 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJournalistic Guidelines Aware News Image Captioning
Sep 10, 2021
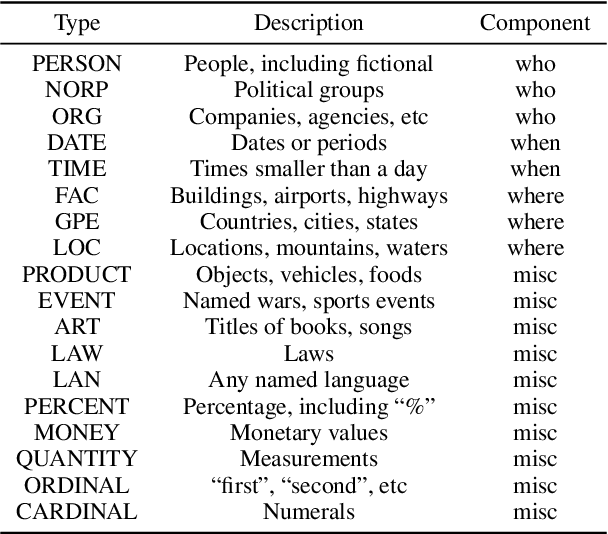

The task of news article image captioning aims to generate descriptive and informative captions for news article images. Unlike conventional image captions that simply describe the content of the image in general terms, news image captions follow journalistic guidelines and rely heavily on named entities to describe the image content, often drawing context from the whole article they are associated with. In this work, we propose a new approach to this task, motivated by caption guidelines that journalists follow. Our approach, Journalistic Guidelines Aware News Image Captioning (JoGANIC), leverages the structure of captions to improve the generation quality and guide our representation design. Experimental results, including detailed ablation studies, on two large-scale publicly available datasets show that JoGANIC substantially outperforms state-of-the-art methods both on caption generation and named entity related metrics.
Weakly Supervised Visual Semantic Parsing
Jan 08, 2020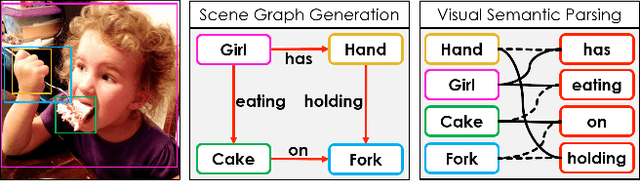
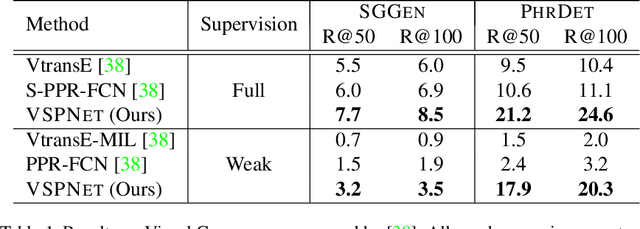
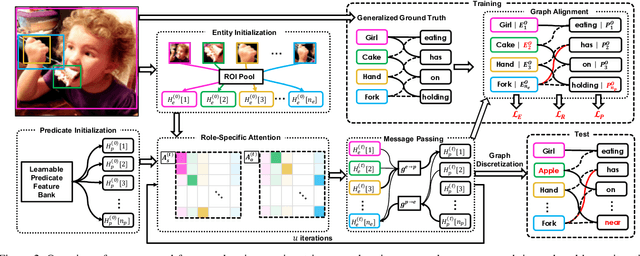
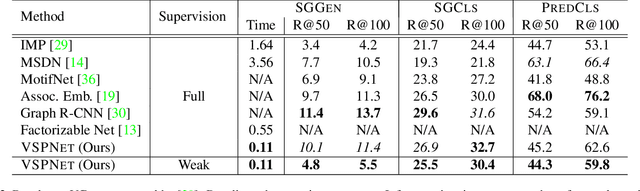
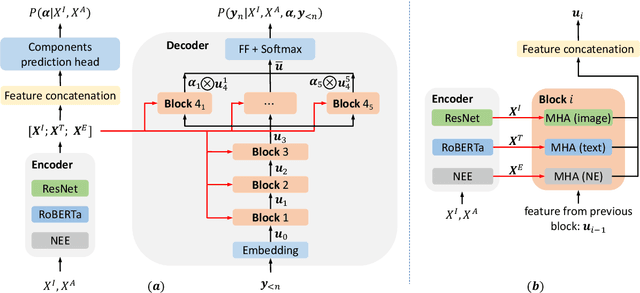
Scene Graph Generation (SGG) aims to extract entities, predicates and their intrinsic structure from images, leading to a deep understanding of visual content, with many potential applications such as visual reasoning and image retrieval. Nevertheless, computer vision is still far from a practical solution for this task. Existing SGG methods require millions of manually annotated bounding boxes for scene graph entities in a large set of images. Moreover, they are computationally inefficient, as they exhaustively process all pairs of object proposals to predict their relationships. In this paper, we address those two limitations by first proposing a generalized formulation of SGG, namely Visual Semantic Parsing, which disentangles entity and predicate prediction, and enables sub-quadratic performance. Then we propose the Visual Semantic Parsing Network, \textsc{VSPNet}, based on a novel three-stage message propagation network, as well as a role-driven attention mechanism to route messages efficiently without a quadratic cost. Finally, we propose the first graph-based weakly supervised learning framework based on a novel graph alignment algorithm, which enables training without bounding box annotations. Through extensive experiments on the Visual Genome dataset, we show \textsc{VSPNet} outperforms weakly supervised baselines significantly and approaches fully supervised performance, while being five times faster.
Bridging Knowledge Graphs to Generate Scene Graphs
Jan 07, 2020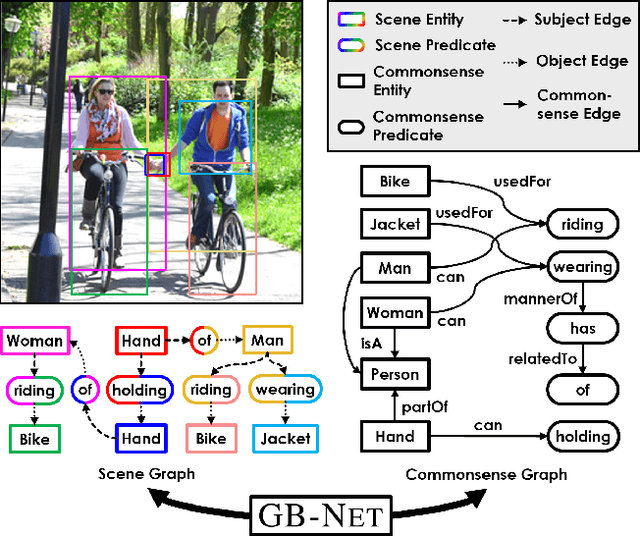
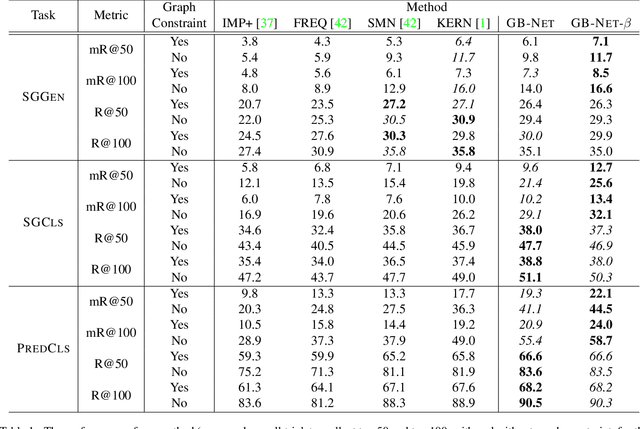

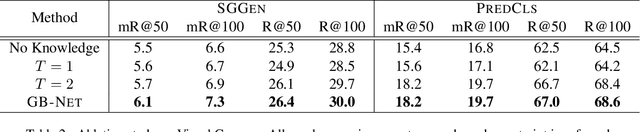
Scene graphs are powerful representations that encode images into their abstract semantic elements, i.e, objects and their interactions, which facilitates visual comprehension and explainable reasoning. On the other hand, commonsense knowledge graphs are rich repositories that encode how the world is structured, and how general concepts interact. In this paper, we present a unified formulation of these two constructs, where a scene graph is seen as an image-conditioned instantiation of a commonsense knowledge graph. Based on this new perspective, we re-formulate scene graph generation as the inference of a bridge between the scene and commonsense graphs, where each entity or predicate instance in the scene graph has to be linked to its corresponding entity or predicate class in the commonsense graph. To this end, we propose a heterogeneous graph inference framework allowing to exploit the rich structure within the scene and commonsense at the same time. Through extensive experiments, we show the proposed method achieves significant improvement over the state of the art.
Flow-Distilled IP Two-Stream Networks for Compressed Video Action Recognition
Dec 12, 2019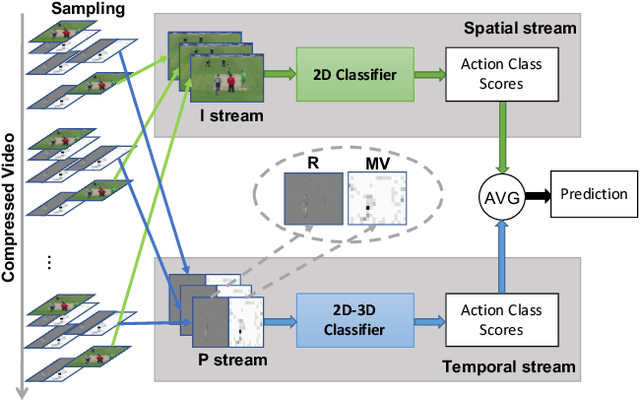
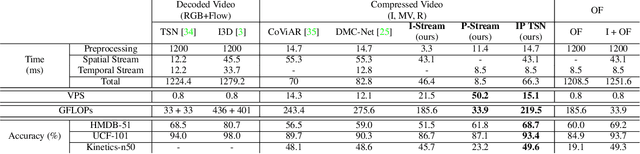
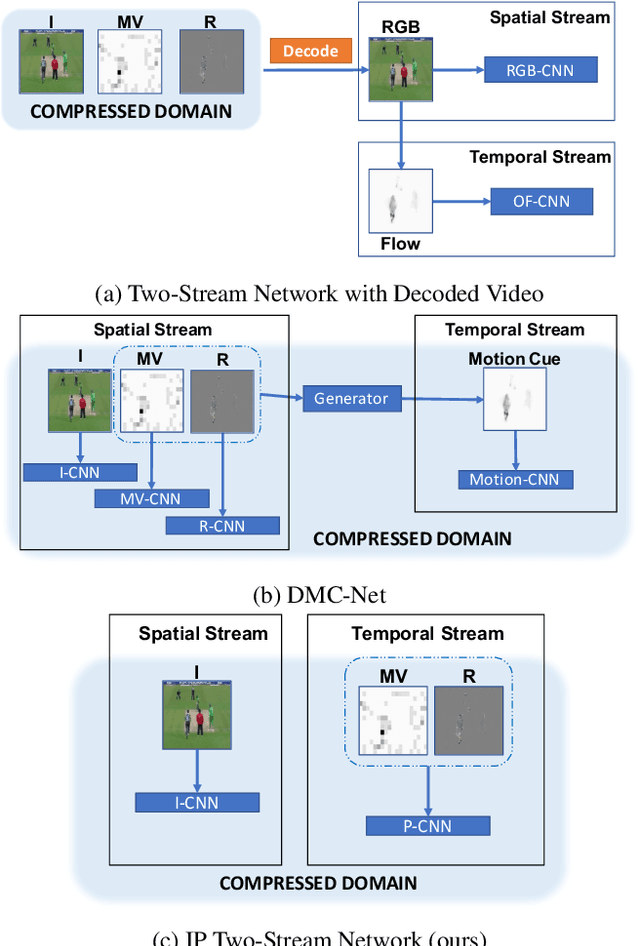
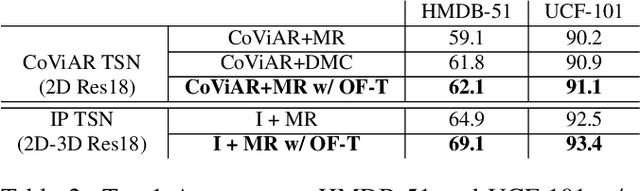
Two-stream networks have achieved great success in video recognition. A two-stream network combines a spatial stream of RGB frames and a temporal stream of Optical Flow to make predictions. However, the temporal redundancy of RGB frames as well as the high-cost of optical flow computation creates challenges for both the performance and efficiency. Recent works instead use modern compressed video modalities as an alternative to the RGB spatial stream and improve the inference speed by orders of magnitudes. Previous works create one stream for each modality which are combined with an additional temporal stream through late fusion. This is redundant since some modalities like motion vectors already contain temporal information. Based on this observation, we propose a compressed domain two-stream network IP TSN for compressed video recognition, where the two streams are represented by the two types of frames (I and P frames) in compressed videos, without needing a separate temporal stream. With this goal, we propose to fully exploit the motion information of P-stream through generalized distillation from optical flow, which largely improves the efficiency and accuracy. Our P-stream runs 60 times faster than using optical flow while achieving higher accuracy. Our full IP TSN, evaluated over public action recognition benchmarks (UCF101, HMDB51 and a subset of Kinetics), outperforms other compressed domain methods by large margins while improving the total inference speed by 20%.
Detecting and Simulating Artifacts in GAN Fake Images
Jul 15, 2019


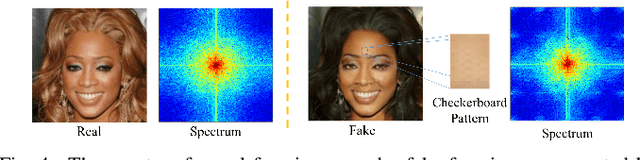
To detect GAN generated images, conventional supervised machine learning algorithms require collection of a number of real and fake images from the targeted GAN model. However, the specific model used by the attacker is often unavailable. To address this, we propose a GAN simulator, AutoGAN, which can simulate the artifacts produced by the common pipeline shared by several popular GAN models. Additionally, we identify a unique artifact caused by the up-sampling component included in the common GAN pipeline. We show theoretically such artifacts are manifested as replications of spectra in the frequency domain and thus propose a classifier model based on the spectrum input, rather than the pixel input. By using the simulated images to train a spectrum based classifier, even without seeing the fake images produced by the targeted GAN model during training, our approach achieves state-of-the-art performances on detecting fake images generated by popular GAN models such as CycleGAN.
Unsupervised Rank-Preserving Hashing for Large-Scale Image Retrieval
Mar 04, 2019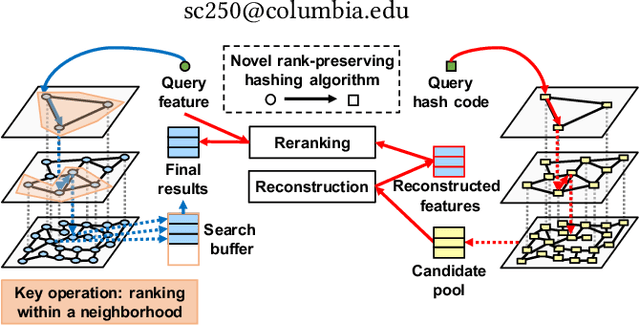
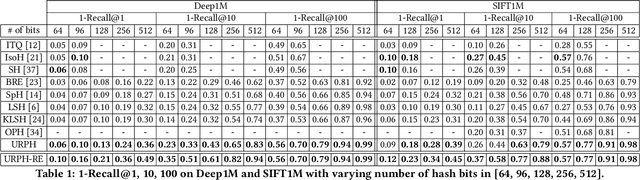
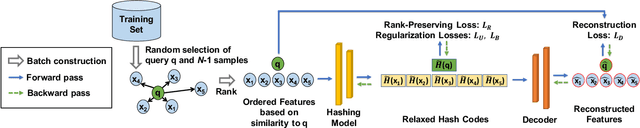
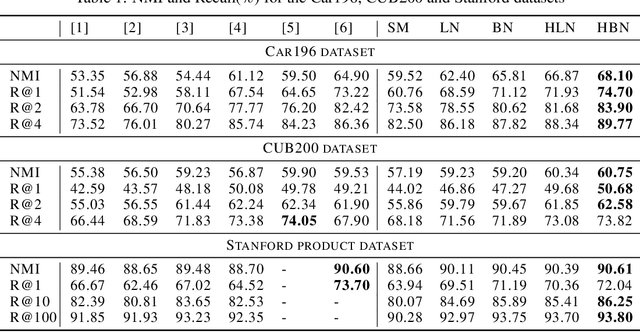
We propose an unsupervised hashing method which aims to produce binary codes that preserve the ranking induced by a real-valued representation. Such compact hash codes enable the complete elimination of real-valued feature storage and allow for significant reduction of the computation complexity and storage cost of large-scale image retrieval applications. Specifically, we learn a neural network-based model, which transforms the input representation into a binary representation. We formalize the training objective of the network in an intuitive and effective way, considering each training sample as a query and aiming to obtain the same retrieval results using the produced hash codes as those obtained with the original features. This training formulation directly optimizes the hashing model for the target usage of the hash codes it produces. We further explore the addition of a decoder trained to obtain an approximated reconstruction of the original features. At test time, we retrieved the most promising database samples with an efficient graph-based search procedure using only our hash codes and perform re-ranking using the reconstructed features, thus without needing to access the original features at all. Experiments conducted on multiple publicly available large-scale datasets show that our method consistently outperforms all compared state-of-the-art unsupervised hashing methods and that the reconstruction procedure can effectively boost the search accuracy with a minimal constant additional cost.
Multi-level Multimodal Common Semantic Space for Image-Phrase Grounding
Nov 28, 2018


We address the problem of phrase grounding by learning a multi-level common semantic space shared by the textual and visual modalities. This common space is instantiated at multiple layers of a Deep Convolutional Neural Network by exploiting its feature maps, as well as contextualized word-level and sentence-level embeddings extracted from a character-based language model. Following a dedicated non-linear mapping for visual features at each level, word, and sentence embeddings, we obtain a common space in which comparisons between the target text and the visual content at any semantic level can be performed simply with cosine similarity. We guide the model by a multi-level multimodal attention mechanism which outputs attended visual features at different semantic levels. The best level is chosen to be compared with text content for maximizing the pertinence scores of image-sentence pairs of the ground truth. Experiments conducted on three publicly available benchmarks show significant performance gains (20%-60% relative) over the state-of-the-art in phrase localization and set a new performance record on those datasets. We also provide a detailed ablation study to show the contribution of each element of our approach.
Heated-Up Softmax Embedding
Sep 11, 2018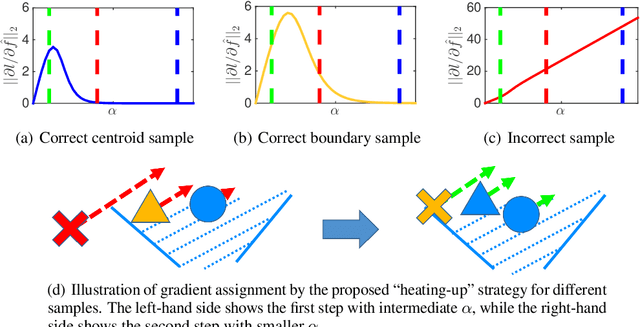
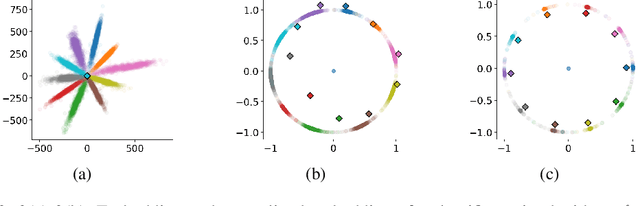
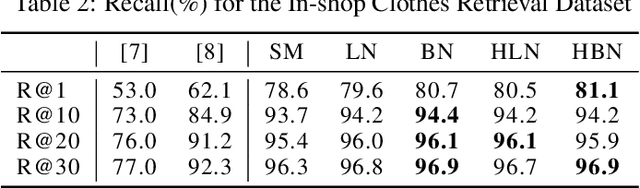
Metric learning aims at learning a distance which is consistent with the semantic meaning of the samples. The problem is generally solved by learning an embedding for each sample such that the embeddings of samples of the same category are compact while the embeddings of samples of different categories are spread-out in the feature space. We study the features extracted from the second last layer of a deep neural network based classifier trained with the cross entropy loss on top of the softmax layer. We show that training classifiers with different temperature values of softmax function leads to features with different levels of compactness. Leveraging these insights, we propose a "heating-up" strategy to train a classifier with increasing temperatures, leading the corresponding embeddings to achieve state-of-the-art performance on a variety of metric learning benchmarks.
Multimodal Social Media Analysis for Gang Violence Prevention
Jul 23, 2018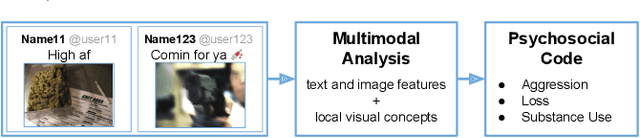
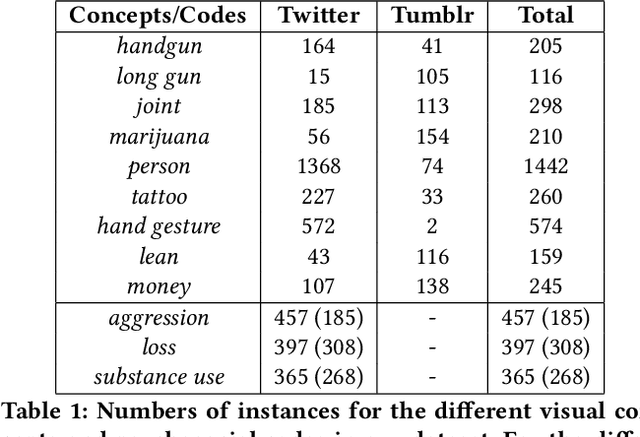

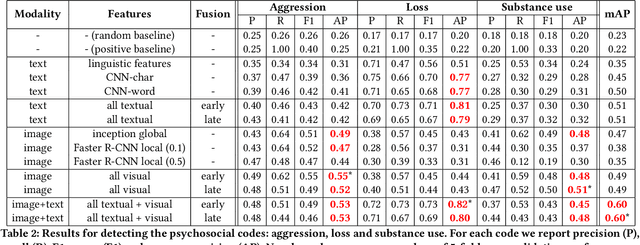
Gang violence is a severe issue in major cities across the U.S. and recent studies [Patton et al. 2017] have found evidence of social media communications that can be linked to such violence in communities with high rates of exposure to gang activity. In this paper we partnered computer scientists with social work researchers, who have domain expertise in gang violence, to analyze how public tweets with images posted by youth who mention gang associations on Twitter can be leveraged to automatically detect psychosocial factors and conditions that could potentially assist social workers and violence outreach workers in prevention and early intervention programs. To this end, we developed a rigorous methodology for collecting and annotating tweets. We gathered 1,851 tweets and accompanying annotations related to visual concepts and the psychosocial codes: aggression, loss, and substance use. These codes are relevant to social work interventions, as they represent possible pathways to violence on social media. We compare various methods for classifying tweets into these three classes, using only the text of the tweet, only the image of the tweet, or both modalities as input to the classifier. In particular, we analyze the usefulness of mid-level visual concepts and the role of different modalities for this tweet classification task. Our experiments show that individually, text information dominates classification performance of the loss class, while image information dominates the aggression and substance use classes. Our multimodal approach provides a very promising improvement (18% relative in mean average precision) over the best single modality approach. Finally, we also illustrate the complexity of understanding social media data and elaborate on open challenges.
Multi Channel-Kernel Canonical Correlation Analysis for Cross-View Person Re-Identification
Mar 21, 2017


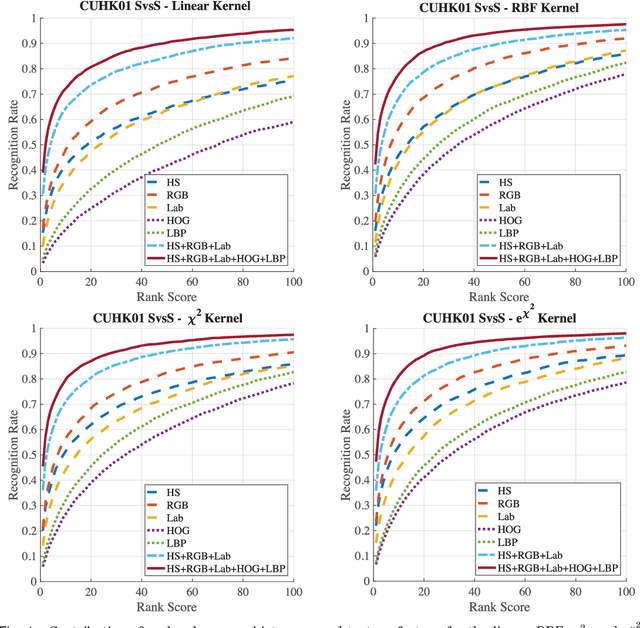
In this paper we introduce a method to overcome one of the main challenges of person re-identification in multi-camera networks, namely cross-view appearance changes. The proposed solution addresses the extreme variability of person appearance in different camera views by exploiting multiple feature representations. For each feature, Kernel Canonical Correlation Analysis (KCCA) with different kernels is exploited to learn several projection spaces in which the appearance correlation between samples of the same person observed from different cameras is maximized. An iterative logistic regression is finally used to select and weigh the contributions of each feature projections and perform the matching between the two views. Experimental evaluation shows that the proposed solution obtains comparable performance on VIPeR and PRID 450s datasets and improves on PRID and CUHK01 datasets with respect to the state of the art.
* The latest/updated version of the manuscript with more experiments can be found at https://doi.org/10.1145/3038916. Please cite the paper using https://doi.org/10.1145/3038916