 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Visual Semantic Parsing
Paper and Code
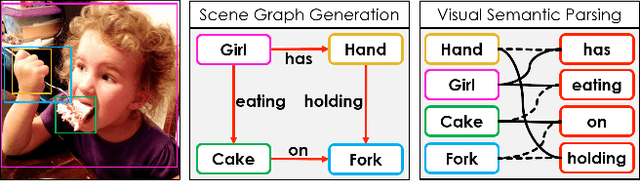
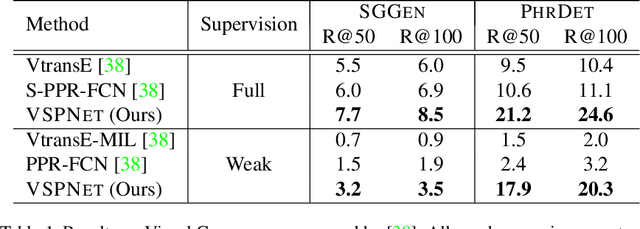
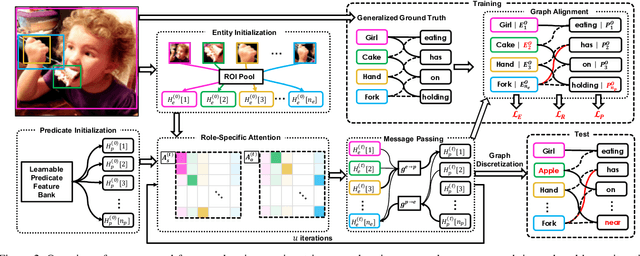
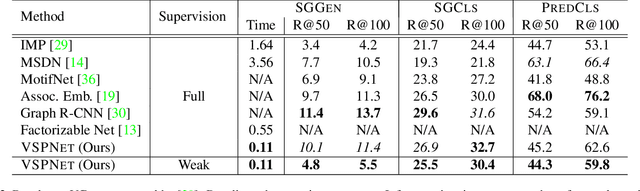
Scene Graph Generation (SGG) aims to extract entities, predicates and their intrinsic structure from images, leading to a deep understanding of visual content, with many potential applications such as visual reasoning and image retrieval. Nevertheless, computer vision is still far from a practical solution for this task. Existing SGG methods require millions of manually annotated bounding boxes for scene graph entities in a large set of images. Moreover, they are computationally inefficient, as they exhaustively process all pairs of object proposals to predict their relationships. In this paper, we address those two limitations by first proposing a generalized formulation of SGG, namely Visual Semantic Parsing, which disentangles entity and predicate prediction, and enables sub-quadratic performance. Then we propose the Visual Semantic Parsing Network, \textsc{VSPNet}, based on a novel three-stage message propagation network, as well as a role-driven attention mechanism to route messages efficiently without a quadratic cost. Finally, we propose the first graph-based weakly supervised learning framework based on a novel graph alignment algorithm, which enables training without bounding box annotations. Through extensive experiments on the Visual Genome dataset, we show \textsc{VSPNet} outperforms weakly supervised baselines significantly and approaches fully supervised performance, while being five times faster.