 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeated-Up Softmax Embedding
Paper and Code
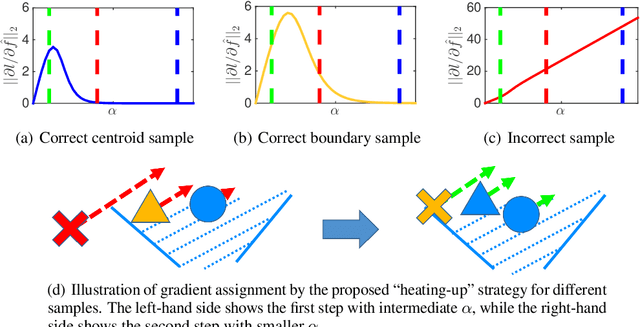
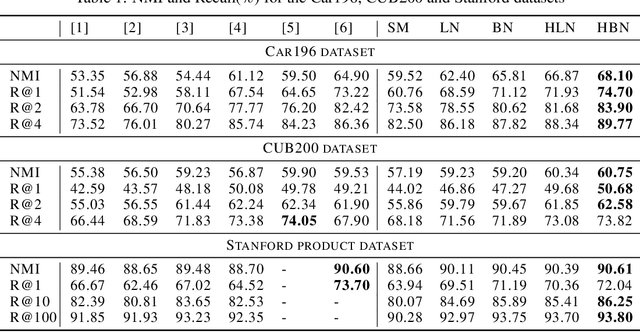
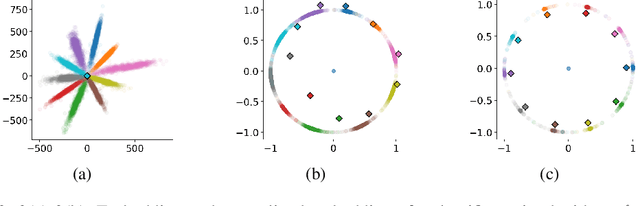
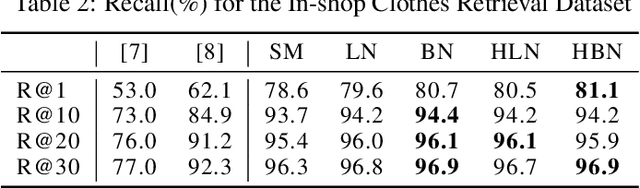
Metric learning aims at learning a distance which is consistent with the semantic meaning of the samples. The problem is generally solved by learning an embedding for each sample such that the embeddings of samples of the same category are compact while the embeddings of samples of different categories are spread-out in the feature space. We study the features extracted from the second last layer of a deep neural network based classifier trained with the cross entropy loss on top of the softmax layer. We show that training classifiers with different temperature values of softmax function leads to features with different levels of compactness. Leveraging these insights, we propose a "heating-up" strategy to train a classifier with increasing temperatures, leading the corresponding embeddings to achieve state-of-the-art performance on a variety of metric learning benchmarks.