 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRISCLIP: Referring Image Segmentation Framework using CLIP
Paper and Code
Jun 14, 2023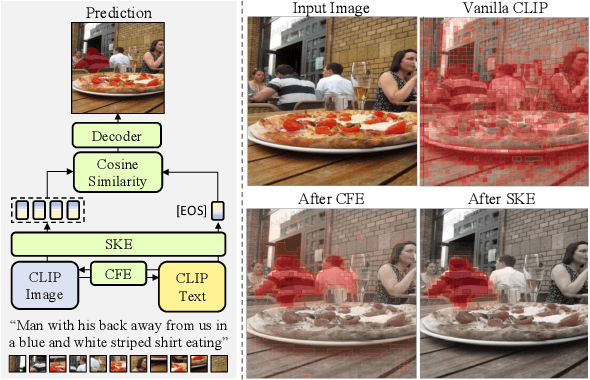



Recent advances in computer vision and natural language processing have naturally led to active research in multi-modal tasks, including Referring Image Segmentation (RIS). Recent approaches have advanced the frontier of RIS by impressive margins, but they require an additional pretraining stage on external visual grounding datasets to achieve the state-of-the-art performances. We attempt to break free from this requirement by effectively adapting Contrastive Language-Image Pretraining (CLIP) to RIS. We propose a novel framework that residually adapts frozen CLIP features to RIS with Fusion Adapters and Backbone Adapters. Freezing CLIP preserves the backbone's rich, general image-text alignment knowledge, whilst Fusion Adapters introduce multi-modal communication and Backbone Adapters inject new knowledge useful in solving RIS. Our method reaches a new state of the art on three major RIS benchmarks. We attain such performance without additional pretraining and thereby absolve the necessity of extra training and data preparation. Source code and model weights will be available upon publication.