 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFill-Up: Balancing Long-Tailed Data with Generative Models
Paper and Code
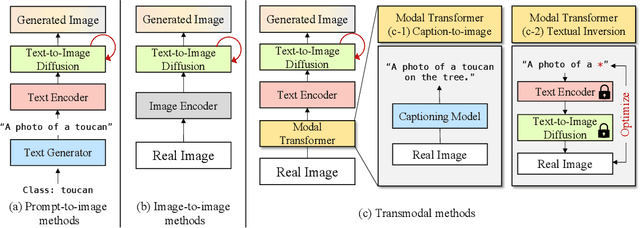

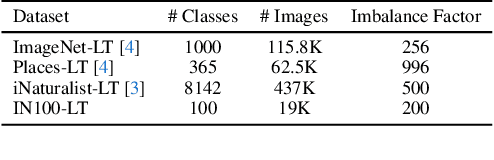
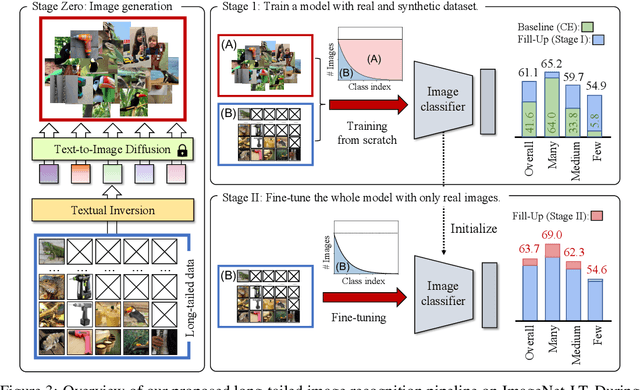
Modern text-to-image synthesis models have achieved an exceptional level of photorealism, generating high-quality images from arbitrary text descriptions. In light of the impressive synthesis ability, several studies have exhibited promising results in exploiting generated data for image recognition. However, directly supplementing data-hungry situations in the real-world (e.g. few-shot or long-tailed scenarios) with existing approaches result in marginal performance gains, as they suffer to thoroughly reflect the distribution of the real data. Through extensive experiments, this paper proposes a new image synthesis pipeline for long-tailed situations using Textual Inversion. The study demonstrates that generated images from textual-inverted text tokens effectively aligns with the real domain, significantly enhancing the recognition ability of a standard ResNet50 backbone. We also show that real-world data imbalance scenarios can be successfully mitigated by filling up the imbalanced data with synthetic images. In conjunction with techniques in the area of long-tailed recognition, our method achieves state-of-the-art results on standard long-tailed benchmarks when trained from scratch.