 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpress4D: Expressive, Friendly, and Extensible 4D Facial Motion Generation Benchmark
Aug 17, 2025Dynamic facial expression generation from natural language is a crucial task in Computer Graphics, with applications in Animation, Virtual Avatars, and Human-Computer Interaction. However, current generative models suffer from datasets that are either speech-driven or limited to coarse emotion labels, lacking the nuanced, expressive descriptions needed for fine-grained control, and were captured using elaborate and expensive equipment. We hence present a new dataset of facial motion sequences featuring nuanced performances and semantic annotation. The data is easily collected using commodity equipment and LLM-generated natural language instructions, in the popular ARKit blendshape format. This provides riggable motion, rich with expressive performances and labels. We accordingly train two baseline models, and evaluate their performance for future benchmarking. Using our Express4D dataset, the trained models can learn meaningful text-to-expression motion generation and capture the many-to-many mapping of the two modalities. The dataset, code, and video examples are available on our webpage: https://jaron1990.github.io/Express4D/
ImageRAG: Dynamic Image Retrieval for Reference-Guided Image Generation
Feb 13, 2025


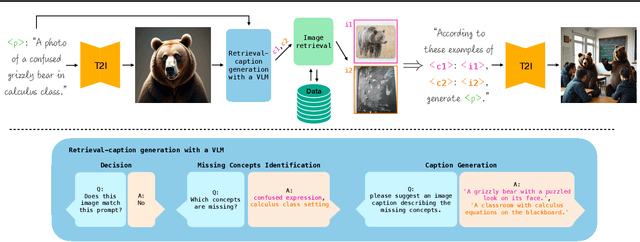
Diffusion models enable high-quality and diverse visual content synthesis. However, they struggle to generate rare or unseen concepts. To address this challenge, we explore the usage of Retrieval-Augmented Generation (RAG) with image generation models. We propose ImageRAG, a method that dynamically retrieves relevant images based on a given text prompt, and uses them as context to guide the generation process. Prior approaches that used retrieved images to improve generation, trained models specifically for retrieval-based generation. In contrast, ImageRAG leverages the capabilities of existing image conditioning models, and does not require RAG-specific training. Our approach is highly adaptable and can be applied across different model types, showing significant improvement in generating rare and fine-grained concepts using different base models. Our project page is available at: https://rotem-shalev.github.io/ImageRAG
V-LASIK: Consistent Glasses-Removal from Videos Using Synthetic Data
Jun 20, 2024Diffusion-based generative models have recently shown remarkable image and video editing capabilities. However, local video editing, particularly removal of small attributes like glasses, remains a challenge. Existing methods either alter the videos excessively, generate unrealistic artifacts, or fail to perform the requested edit consistently throughout the video. In this work, we focus on consistent and identity-preserving removal of glasses in videos, using it as a case study for consistent local attribute removal in videos. Due to the lack of paired data, we adopt a weakly supervised approach and generate synthetic imperfect data, using an adjusted pretrained diffusion model. We show that despite data imperfection, by learning from our generated data and leveraging the prior of pretrained diffusion models, our model is able to perform the desired edit consistently while preserving the original video content. Furthermore, we exemplify the generalization ability of our method to other local video editing tasks by applying it successfully to facial sticker-removal. Our approach demonstrates significant improvement over existing methods, showcasing the potential of leveraging synthetic data and strong video priors for local video editing tasks.
Monkey See, Monkey Do: Harnessing Self-attention in Motion Diffusion for Zero-shot Motion Transfer
Jun 10, 2024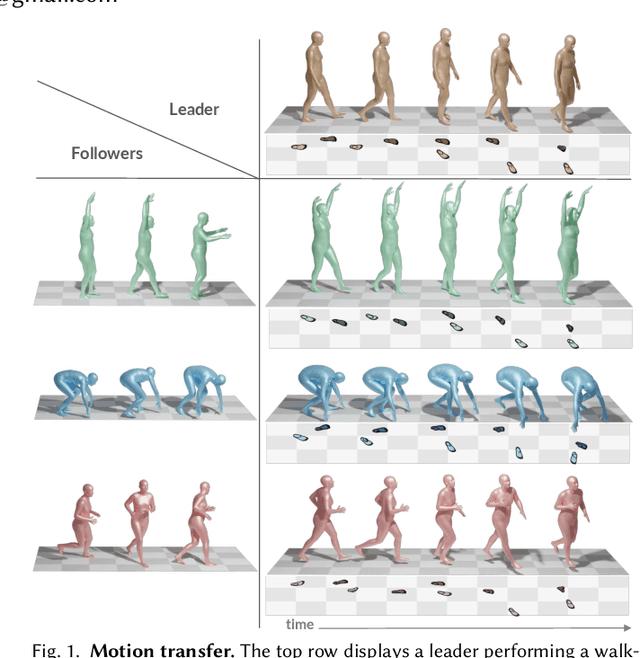
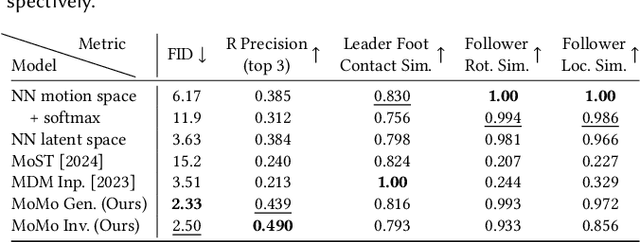
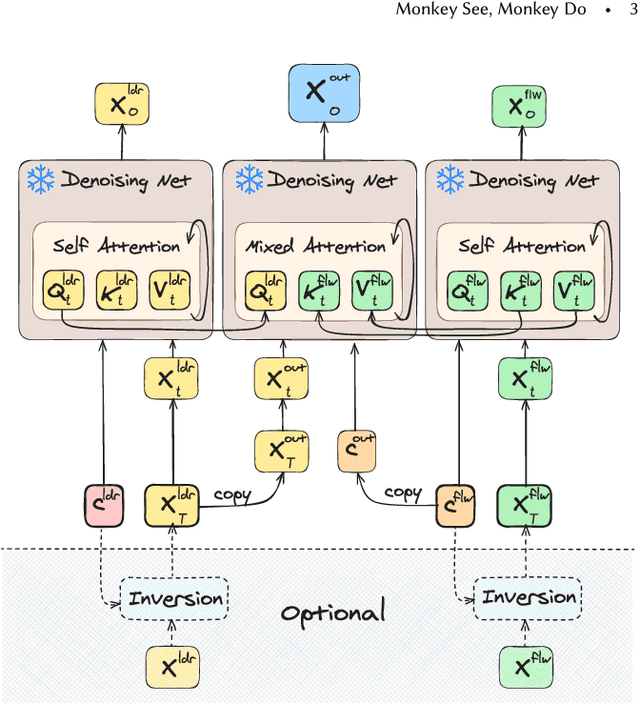
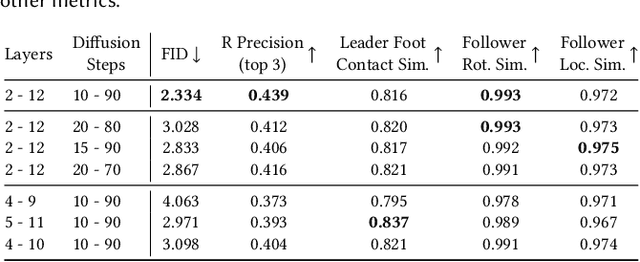
Given the remarkable results of motion synthesis with diffusion models, a natural question arises: how can we effectively leverage these models for motion editing? Existing diffusion-based motion editing methods overlook the profound potential of the prior embedded within the weights of pre-trained models, which enables manipulating the latent feature space; hence, they primarily center on handling the motion space. In this work, we explore the attention mechanism of pre-trained motion diffusion models. We uncover the roles and interactions of attention elements in capturing and representing intricate human motion patterns, and carefully integrate these elements to transfer a leader motion to a follower one while maintaining the nuanced characteristics of the follower, resulting in zero-shot motion transfer. Editing features associated with selected motions allows us to confront a challenge observed in prior motion diffusion approaches, which use general directives (e.g., text, music) for editing, ultimately failing to convey subtle nuances effectively. Our work is inspired by how a monkey closely imitates what it sees while maintaining its unique motion patterns; hence we call it Monkey See, Monkey Do, and dub it MoMo. Employing our technique enables accomplishing tasks such as synthesizing out-of-distribution motions, style transfer, and spatial editing. Furthermore, diffusion inversion is seldom employed for motions; as a result, editing efforts focus on generated motions, limiting the editability of real ones. MoMo harnesses motion inversion, extending its application to both real and generated motions. Experimental results show the advantage of our approach over the current art. In particular, unlike methods tailored for specific applications through training, our approach is applied at inference time, requiring no training. Our webpage is at https://monkeyseedocg.github.io.
Ham2Pose: Animating Sign Language Notation into Pose Sequences
Nov 24, 2022



Translating spoken languages into Sign languages is necessary for open communication between the hearing and hearing-impaired communities. To achieve this goal, we propose the first method for animating a text written in HamNoSys, a lexical Sign language notation, into signed pose sequences. As HamNoSys is universal, our proposed method offers a generic solution invariant to the target Sign language. Our method gradually generates pose predictions using transformer encoders that create meaningful representations of the text and poses while considering their spatial and temporal information. We use weak supervision for the training process and show that our method succeeds in learning from partial and inaccurate data. Additionally, we offer a new distance measurement for pose sequences, normalized Dynamic Time Warping (nDTW), based on DTW over normalized keypoints trajectories, and validate its correctness using AUTSL, a large-scale Sign language dataset. We show that it measures the distance between pose sequences more accurately than existing measurements and use it to assess the quality of our generated pose sequences. Code for the data pre-processing, the model, and the distance measurement is publicly released for future research.