 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Motion Diffusion
Feb 12, 2023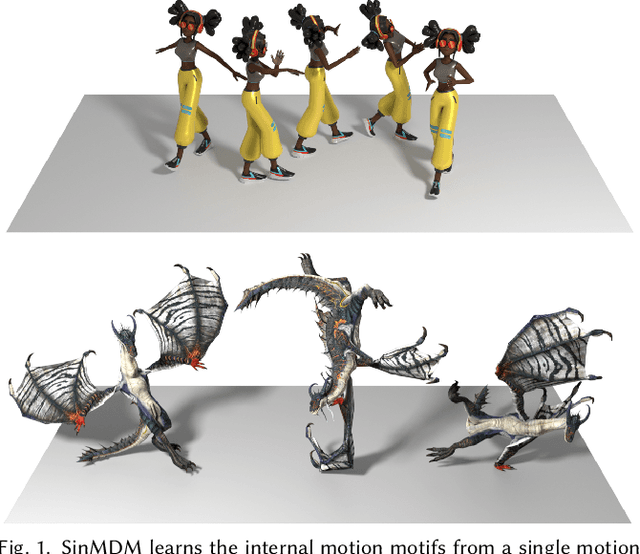
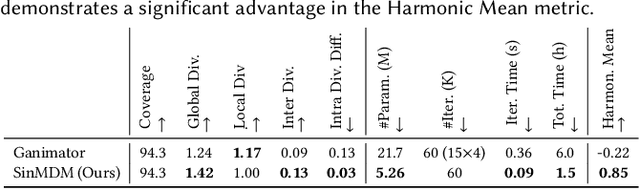
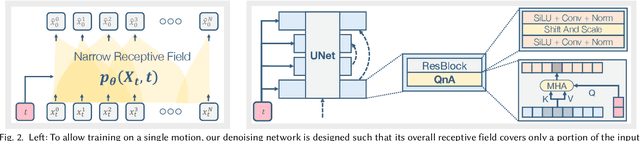
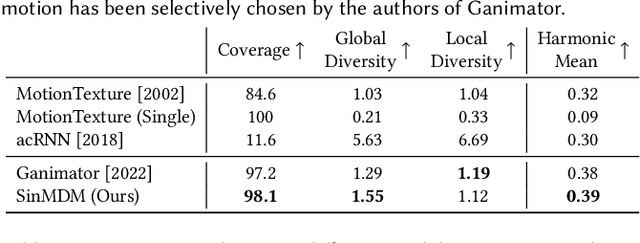
Synthesizing realistic animations of humans, animals, and even imaginary creatures, has long been a goal for artists and computer graphics professionals. Compared to the imaging domain, which is rich with large available datasets, the number of data instances for the motion domain is limited, particularly for the animation of animals and exotic creatures (e.g., dragons), which have unique skeletons and motion patterns. In this work, we present a Single Motion Diffusion Model, dubbed SinMDM, a model designed to learn the internal motifs of a single motion sequence with arbitrary topology and synthesize motions of arbitrary length that are faithful to them. We harness the power of diffusion models and present a denoising network designed specifically for the task of learning from a single input motion. Our transformer-based architecture avoids overfitting by using local attention layers that narrow the receptive field, and encourages motion diversity by using relative positional embedding. SinMDM can be applied in a variety of contexts, including spatial and temporal in-betweening, motion expansion, style transfer, and crowd animation. Our results show that SinMDM outperforms existing methods both in quality and time-space efficiency. Moreover, while current approaches require additional training for different applications, our work facilitates these applications at inference time. Our code and trained models are available at https://sinmdm.github.io/SinMDM-page.
MoDi: Unconditional Motion Synthesis from Diverse Data
Jun 16, 2022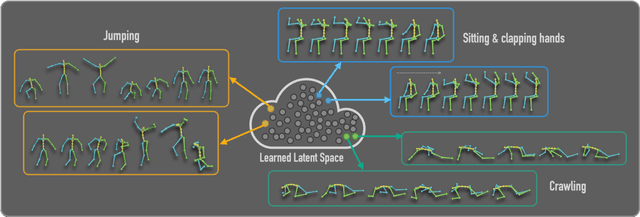
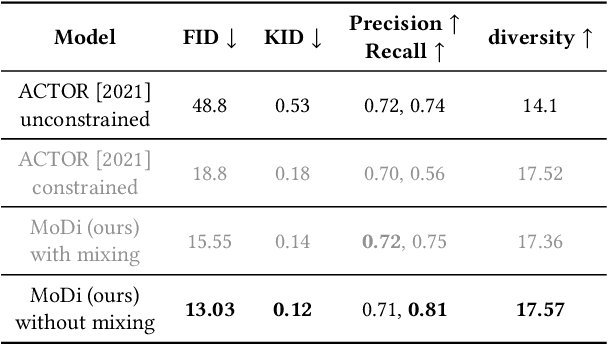
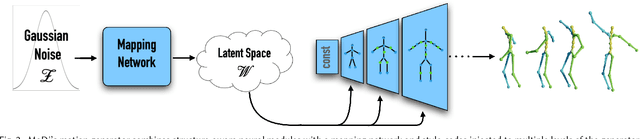
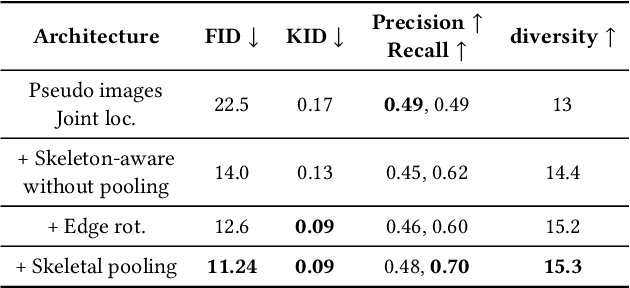
The emergence of neural networks has revolutionized the field of motion synthesis. Yet, learning to unconditionally synthesize motions from a given distribution remains a challenging task, especially when the motions are highly diverse. We present MoDi, an unconditional generative model that synthesizes diverse motions. Our model is trained in a completely unsupervised setting from a diverse, unstructured and unlabeled motion dataset and yields a well-behaved, highly semantic latent space. The design of our model follows the prolific architecture of StyleGAN and adapts two of its key technical components into the motion domain: a set of style-codes injected into each level of the generator hierarchy and a mapping function that learns and forms a disentangled latent space. We show that despite the lack of any structure in the dataset, the latent space can be semantically clustered, and facilitates semantic editing and motion interpolation. In addition, we propose a technique to invert unseen motions into the latent space, and demonstrate latent-based motion editing operations that otherwise cannot be achieved by naive manipulation of explicit motion representations. Our qualitative and quantitative experiments show that our framework achieves state-of-the-art synthesis quality that can follow the distribution of highly diverse motion datasets. Code and trained models will be released at https://sigal-raab.github.io/MoDi.