 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Vehicle Routing via AI-Initialized Genetic Algorithms
Apr 08, 2025Vehicle Routing Problems (VRP) are an extension of the Traveling Salesperson Problem and are a fundamental NP-hard challenge in combinatorial optimization. Solving VRP in real-time at large scale has become critical in numerous applications, from growing markets like last-mile delivery to emerging use-cases like interactive logistics planning. Such applications involve solving similar problem instances repeatedly, yet current state-of-the-art solvers treat each instance on its own without leveraging previous examples. We introduce a novel optimization framework that uses a reinforcement learning agent - trained on prior instances - to quickly generate initial solutions, which are then further optimized by genetic algorithms. Our framework, Evolutionary Algorithm with Reinforcement Learning Initialization (EARLI), consistently outperforms current state-of-the-art solvers across various time scales. For example, EARLI handles vehicle routing with 500 locations within 1s, 10x faster than current solvers for the same solution quality, enabling applications like real-time and interactive routing. EARLI can generalize to new data, as demonstrated on real e-commerce delivery data of a previously unseen city. Our hybrid framework presents a new way to combine reinforcement learning and genetic algorithms, paving the road for closer interdisciplinary collaboration between AI and optimization communities towards real-time optimization in diverse domains.
Optimization or Architecture: How to Hack Kalman Filtering
Oct 01, 2023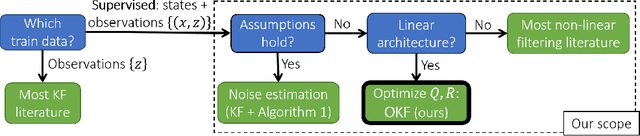



In non-linear filtering, it is traditional to compare non-linear architectures such as neural networks to the standard linear Kalman Filter (KF). We observe that this mixes the evaluation of two separate components: the non-linear architecture, and the parameters optimization method. In particular, the non-linear model is often optimized, whereas the reference KF model is not. We argue that both should be optimized similarly, and to that end present the Optimized KF (OKF). We demonstrate that the KF may become competitive to neural models - if optimized using OKF. This implies that experimental conclusions of certain previous studies were derived from a flawed process. The advantage of OKF over the standard KF is further studied theoretically and empirically, in a variety of problems. Conveniently, OKF can replace the KF in real-world systems by merely updating the parameters.
Individualized Dosing Dynamics via Neural Eigen Decomposition
Jun 24, 2023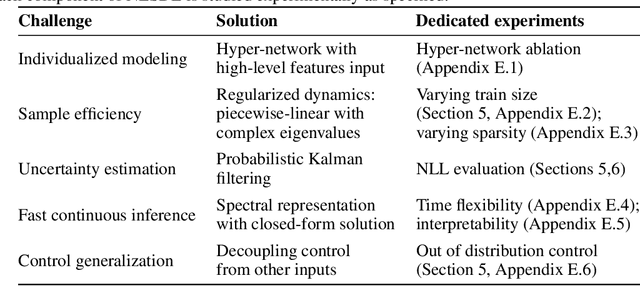



Dosing models often use differential equations to model biological dynamics. Neural differential equations in particular can learn to predict the derivative of a process, which permits predictions at irregular points of time. However, this temporal flexibility often comes with a high sensitivity to noise, whereas medical problems often present high noise and limited data. Moreover, medical dosing models must generalize reliably over individual patients and changing treatment policies. To address these challenges, we introduce the Neural Eigen Stochastic Differential Equation algorithm (NESDE). NESDE provides individualized modeling (using a hypernetwork over patient-level parameters); generalization to new treatment policies (using decoupled control); tunable expressiveness according to the noise level (using piecewise linearity); and fast, continuous, closed-form prediction (using spectral representation). We demonstrate the robustness of NESDE in both synthetic and real medical problems, and use the learned dynamics to publish simulated medical gym environments.
Train Hard, Fight Easy: Robust Meta Reinforcement Learning
Jan 26, 2023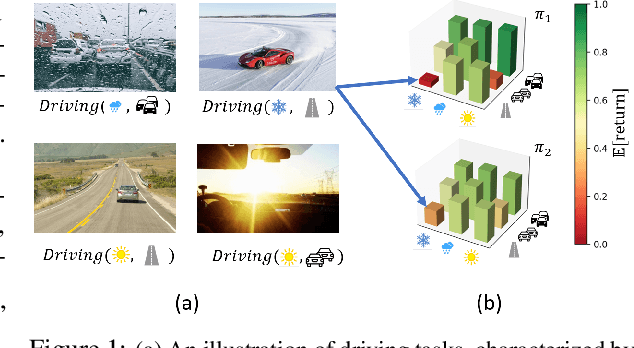



A major challenge of reinforcement learning (RL) in real-world applications is the variation between environments, tasks or clients. Meta-RL (MRL) addresses this issue by learning a meta-policy that adapts to new tasks. Standard MRL methods optimize the average return over tasks, but often suffer from poor results in tasks of high risk or difficulty. This limits system reliability whenever test tasks are not known in advance. In this work, we propose a robust MRL objective with a controlled robustness level. Optimization of analogous robust objectives in RL often leads to both biased gradients and data inefficiency. We prove that the former disappears in MRL, and address the latter via the novel Robust Meta RL algorithm (RoML). RoML is a meta-algorithm that generates a robust version of any given MRL algorithm, by identifying and over-sampling harder tasks throughout training. We demonstrate that RoML learns substantially different meta-policies and achieves robust returns on several navigation and continuous control benchmarks.
Dynamic Planning in Open-Ended Dialogue using Reinforcement Learning
Jul 25, 2022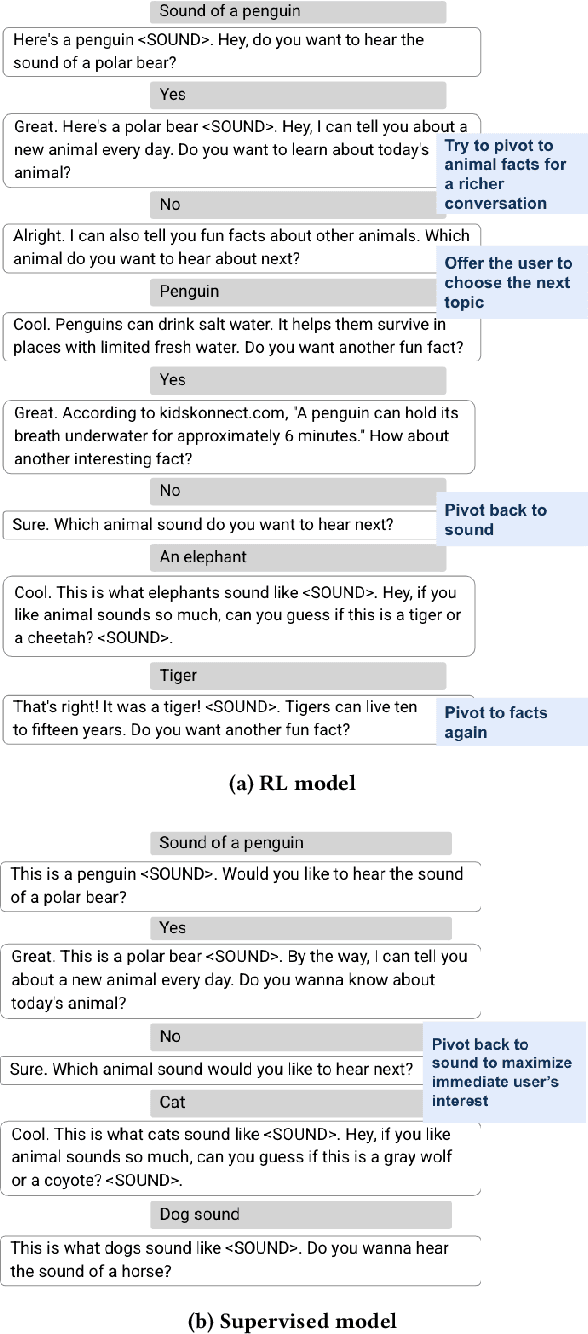
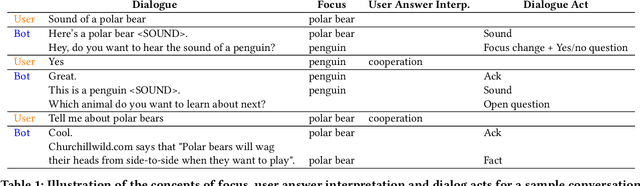

Despite recent advances in natural language understanding and generation, and decades of research on the development of conversational bots, building automated agents that can carry on rich open-ended conversations with humans "in the wild" remains a formidable challenge. In this work we develop a real-time, open-ended dialogue system that uses reinforcement learning (RL) to power a bot's conversational skill at scale. Our work pairs the succinct embedding of the conversation state generated using SOTA (supervised) language models with RL techniques that are particularly suited to a dynamic action space that changes as the conversation progresses. Trained using crowd-sourced data, our novel system is able to substantially exceeds the (strong) baseline supervised model with respect to several metrics of interest in a live experiment with real users of the Google Assistant.
Efficient Risk-Averse Reinforcement Learning
May 10, 2022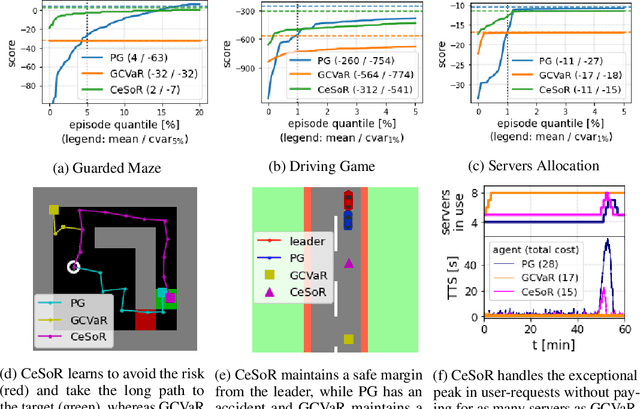


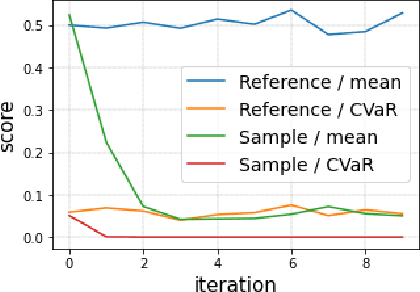
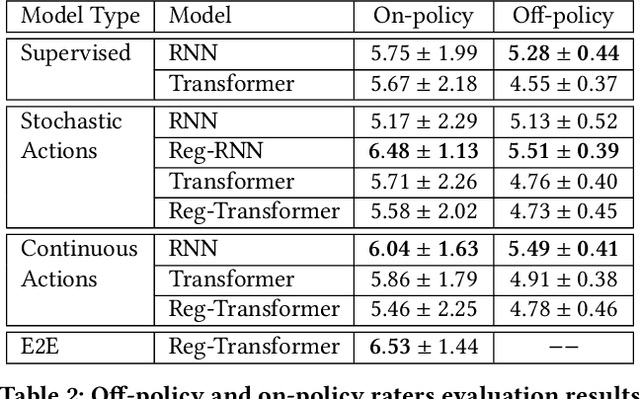
In risk-averse reinforcement learning (RL), the goal is to optimize some risk measure of the returns. A risk measure often focuses on the worst returns out of the agent's experience. As a result, standard methods for risk-averse RL often ignore high-return strategies. We prove that under certain conditions this inevitably leads to a local-optimum barrier, and propose a soft risk mechanism to bypass it. We also devise a novel Cross Entropy module for risk sampling, which (1) preserves risk aversion despite the soft risk; (2) independently improves sample efficiency. By separating the risk aversion of the sampler and the optimizer, we can sample episodes with poor conditions, yet optimize with respect to successful strategies. We combine these two concepts in CeSoR - Cross-entropy Soft-Risk optimization algorithm - which can be applied on top of any risk-averse policy gradient (PG) method. We demonstrate improved risk aversion in maze navigation, autonomous driving, and resource allocation benchmarks, including in scenarios where standard risk-averse PG completely fails.
Continuous Forecasting via Neural Eigen Decomposition of Stochastic Dynamics
Feb 02, 2022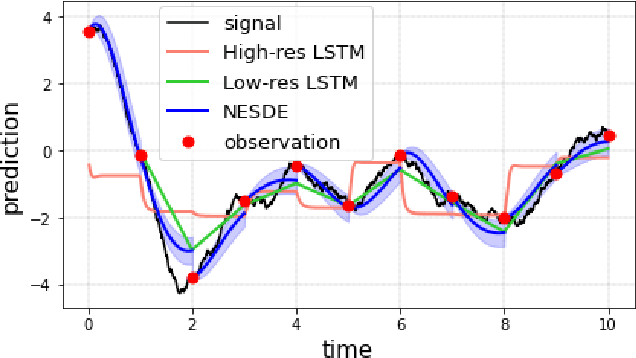
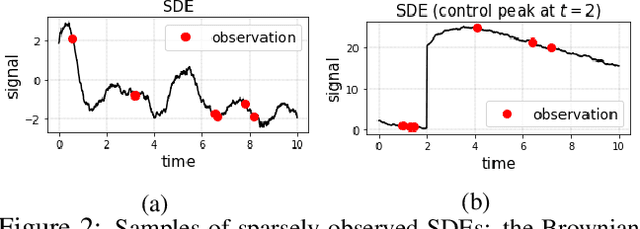
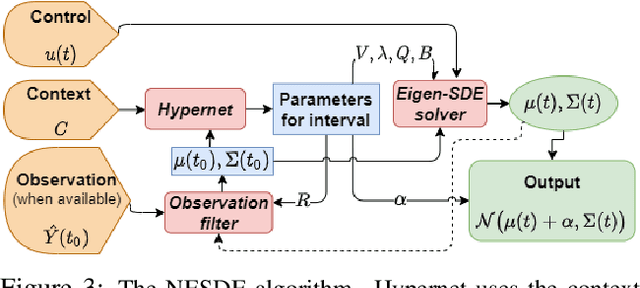
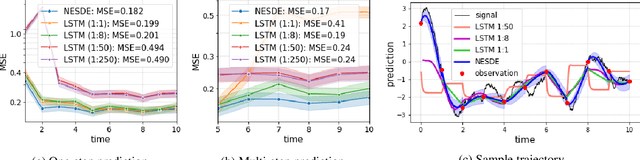
Motivated by a real-world problem of blood coagulation control in Heparin-treated patients, we use Stochastic Differential Equations (SDEs) to formulate a new class of sequential prediction problems -- with an unknown latent space, unknown non-linear dynamics, and irregular sparse observations. We introduce the Neural Eigen-SDE (NESDE) algorithm for sequential prediction with sparse observations and adaptive dynamics. NESDE applies eigen-decomposition to the dynamics model to allow efficient frequent predictions given sparse observations. In addition, NESDE uses a learning mechanism for adaptive dynamics model, which handles changes in the dynamics both between sequences and within sequences. We demonstrate the accuracy and efficacy of NESDE for both synthetic problems and real-world data. In particular, to the best of our knowledge, we are the first to provide a patient-adapted prediction for blood coagulation following Heparin dosing in the MIMIC-IV dataset. Finally, we publish a simulated gym environment based on our prediction model, for experimentation in algorithms for blood coagulation control.
Noise Estimation Is Not Optimal: How To Use Kalman Filter The Right Way
May 04, 2021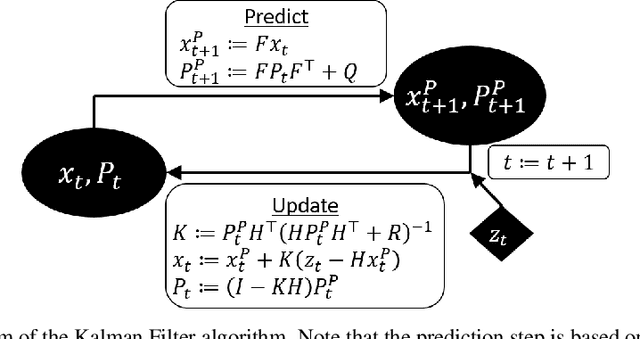
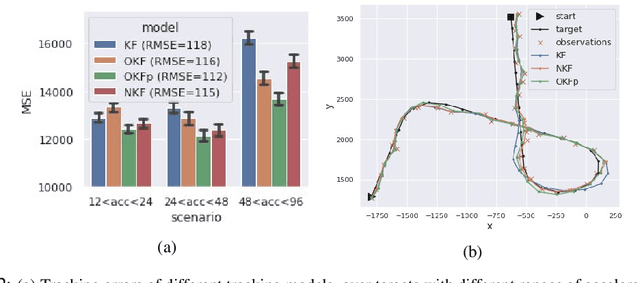
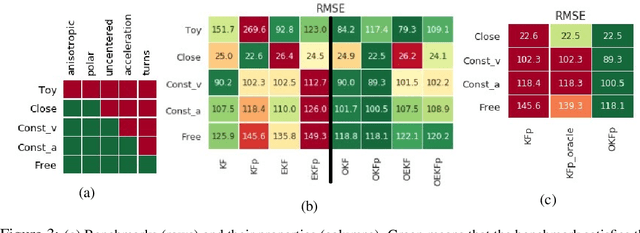
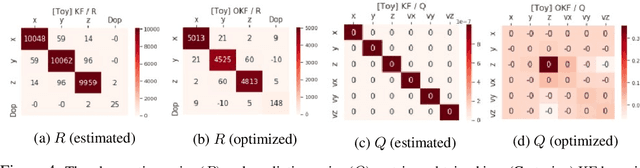
Determining the noise parameters of a Kalman Filter (KF) has been researched for decades. The research focuses on the task of estimation of the noise under various conditions, since precise noise estimation is considered equivalent to errors minimization. However, we show that even a small violation of KF assumptions can significantly modify the effective noise, breaking the equivalence between the tasks and making noise estimation an inferior strategy. We show that such violations are very common, and are often not trivial to handle or even notice. Consequentially, we argue that a robust solution is needed - rather than choosing a dedicated model per problem. To that end, we use a simple parameterization to apply gradient-based optimization efficiently to the symmetric and positive-definite parameters of KF. In radar tracking and video tracking, we show that the optimization improves both the accuracy of KF and its robustness to design decisions. In addition, we demonstrate how a neural network model can seem to reduce the errors significantly compared to a KF - and how this reduction vanishes once the KF is optimized. This indicates how complicated models can be wrongly identified as superior to KF, while in fact they were merely over-optimized.
Drift Detection in Episodic Data: Detect When Your Agent Starts Faltering
Oct 22, 2020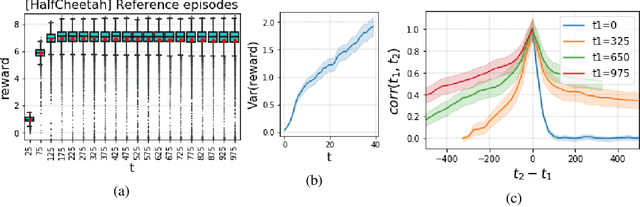

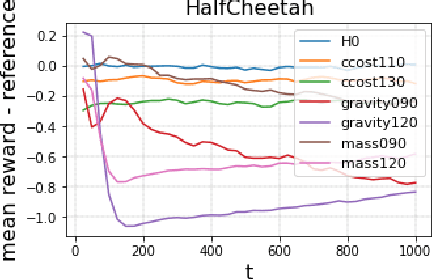
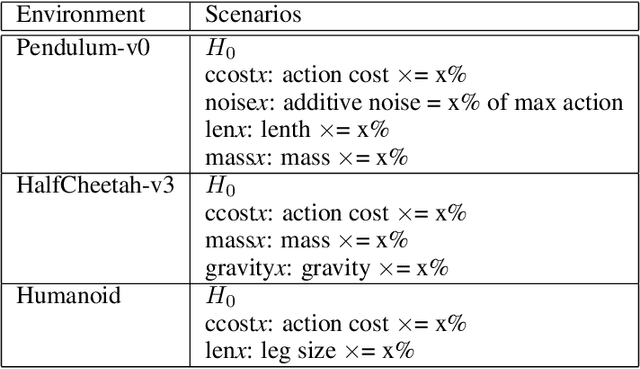
Detection of deterioration of agent performance in dynamic environments is challenging due to the non-i.i.d nature of the observed performance. We consider an episodic framework, where the objective is to detect when an agent begins to falter. We devise a hypothesis testing procedure for non-i.i.d rewards, which is optimal under certain conditions. To apply the procedure sequentially in an online manner, we also suggest a novel Bootstrap mechanism for False Alarm Rate control (BFAR). We demonstrate our procedure in problems where the rewards are not independent, nor identically-distributed, nor normally-distributed. The statistical power of the new testing procedure is shown to outperform alternative tests - often by orders of magnitude - for a variety of environment modifications (which cause deterioration in agent performance). Our detection method is entirely external to the agent, and in particular does not require model-based learning. Furthermore, it can be applied to detect changes or drifts in any episodic signal.