 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization or Architecture: How to Hack Kalman Filtering
Oct 01, 2023



In non-linear filtering, it is traditional to compare non-linear architectures such as neural networks to the standard linear Kalman Filter (KF). We observe that this mixes the evaluation of two separate components: the non-linear architecture, and the parameters optimization method. In particular, the non-linear model is often optimized, whereas the reference KF model is not. We argue that both should be optimized similarly, and to that end present the Optimized KF (OKF). We demonstrate that the KF may become competitive to neural models - if optimized using OKF. This implies that experimental conclusions of certain previous studies were derived from a flawed process. The advantage of OKF over the standard KF is further studied theoretically and empirically, in a variety of problems. Conveniently, OKF can replace the KF in real-world systems by merely updating the parameters.
Noise Estimation Is Not Optimal: How To Use Kalman Filter The Right Way
May 04, 2021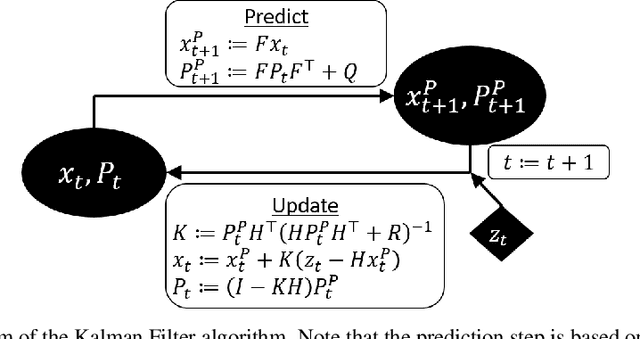
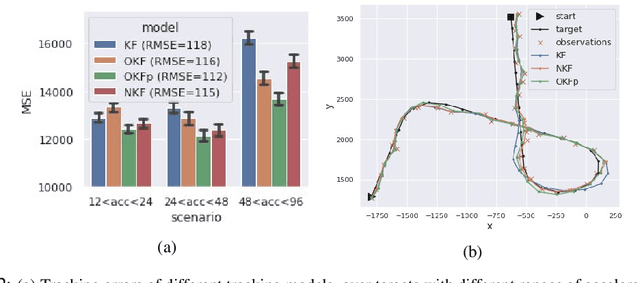
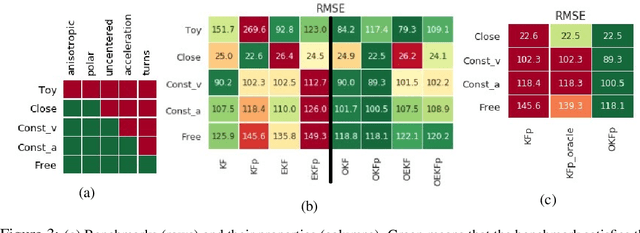
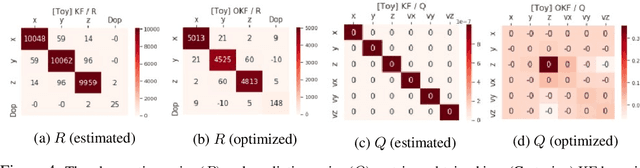
Determining the noise parameters of a Kalman Filter (KF) has been researched for decades. The research focuses on the task of estimation of the noise under various conditions, since precise noise estimation is considered equivalent to errors minimization. However, we show that even a small violation of KF assumptions can significantly modify the effective noise, breaking the equivalence between the tasks and making noise estimation an inferior strategy. We show that such violations are very common, and are often not trivial to handle or even notice. Consequentially, we argue that a robust solution is needed - rather than choosing a dedicated model per problem. To that end, we use a simple parameterization to apply gradient-based optimization efficiently to the symmetric and positive-definite parameters of KF. In radar tracking and video tracking, we show that the optimization improves both the accuracy of KF and its robustness to design decisions. In addition, we demonstrate how a neural network model can seem to reduce the errors significantly compared to a KF - and how this reduction vanishes once the KF is optimized. This indicates how complicated models can be wrongly identified as superior to KF, while in fact they were merely over-optimized.