 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividualized Dosing Dynamics via Neural Eigen Decomposition
Jun 24, 2023



Dosing models often use differential equations to model biological dynamics. Neural differential equations in particular can learn to predict the derivative of a process, which permits predictions at irregular points of time. However, this temporal flexibility often comes with a high sensitivity to noise, whereas medical problems often present high noise and limited data. Moreover, medical dosing models must generalize reliably over individual patients and changing treatment policies. To address these challenges, we introduce the Neural Eigen Stochastic Differential Equation algorithm (NESDE). NESDE provides individualized modeling (using a hypernetwork over patient-level parameters); generalization to new treatment policies (using decoupled control); tunable expressiveness according to the noise level (using piecewise linearity); and fast, continuous, closed-form prediction (using spectral representation). We demonstrate the robustness of NESDE in both synthetic and real medical problems, and use the learned dynamics to publish simulated medical gym environments.
Continuous Forecasting via Neural Eigen Decomposition of Stochastic Dynamics
Feb 02, 2022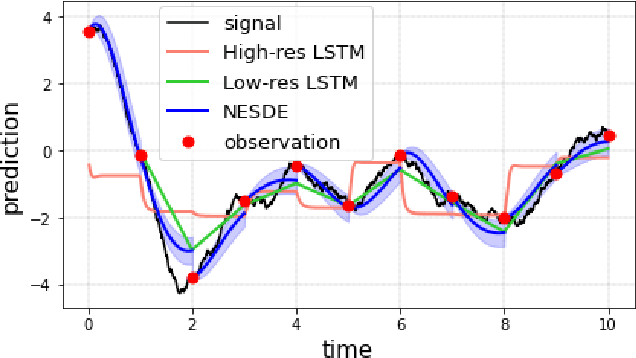
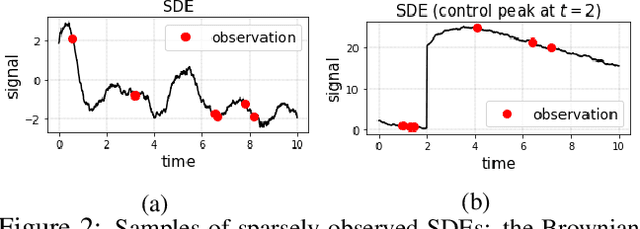
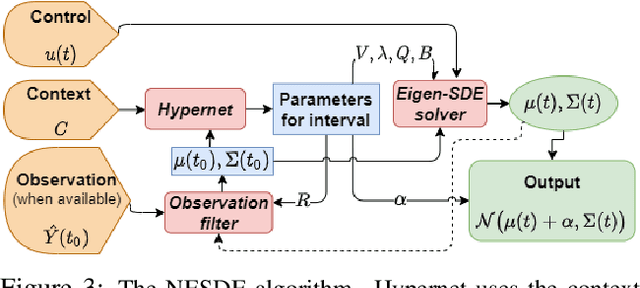
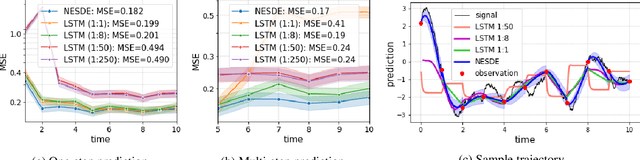
Motivated by a real-world problem of blood coagulation control in Heparin-treated patients, we use Stochastic Differential Equations (SDEs) to formulate a new class of sequential prediction problems -- with an unknown latent space, unknown non-linear dynamics, and irregular sparse observations. We introduce the Neural Eigen-SDE (NESDE) algorithm for sequential prediction with sparse observations and adaptive dynamics. NESDE applies eigen-decomposition to the dynamics model to allow efficient frequent predictions given sparse observations. In addition, NESDE uses a learning mechanism for adaptive dynamics model, which handles changes in the dynamics both between sequences and within sequences. We demonstrate the accuracy and efficacy of NESDE for both synthetic problems and real-world data. In particular, to the best of our knowledge, we are the first to provide a patient-adapted prediction for blood coagulation following Heparin dosing in the MIMIC-IV dataset. Finally, we publish a simulated gym environment based on our prediction model, for experimentation in algorithms for blood coagulation control.
Inverse Reinforcement Learning in Contextual MDPs
May 29, 2019
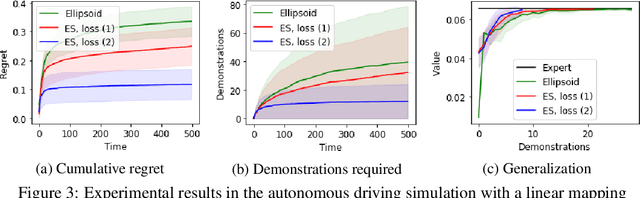

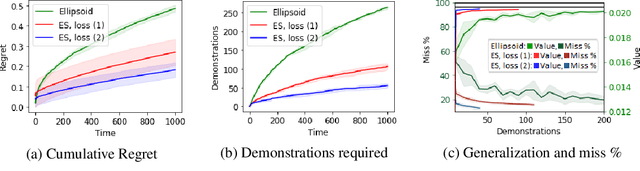
We consider the Inverse Reinforcement Learning (IRL) problem in Contextual Markov Decision Processes (CMDPs). Here, the reward of the environment, which is not available to the agent, depends on a static parameter referred to as the context. Each context defines an MDP (with a different reward signal), and the agent is provided demonstrations by an expert, for different contexts. The goal is to learn a mapping from contexts to rewards, such that planning with respect to the induced reward will perform similarly to the expert, even for unseen contexts. We suggest two learning algorithms for this scenario. (1) For rewards that are a linear function of the context, we provide a method that is guaranteed to return an $\epsilon$-optimal solution after a polynomial number of demonstrations. (2) For general reward functions, we propose black-box descent methods based on evolutionary strategies capable of working with nonlinear estimators (e.g., neural networks). We evaluate our algorithms in autonomous driving and medical treatment simulations and demonstrate their ability to learn and generalize to unseen contexts.