 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInverse Reinforcement Learning in Contextual MDPs
May 29, 2019
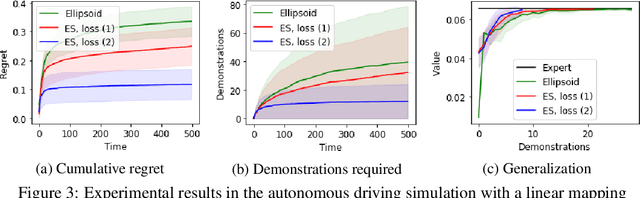

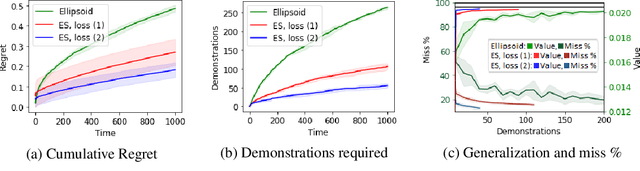
We consider the Inverse Reinforcement Learning (IRL) problem in Contextual Markov Decision Processes (CMDPs). Here, the reward of the environment, which is not available to the agent, depends on a static parameter referred to as the context. Each context defines an MDP (with a different reward signal), and the agent is provided demonstrations by an expert, for different contexts. The goal is to learn a mapping from contexts to rewards, such that planning with respect to the induced reward will perform similarly to the expert, even for unseen contexts. We suggest two learning algorithms for this scenario. (1) For rewards that are a linear function of the context, we provide a method that is guaranteed to return an $\epsilon$-optimal solution after a polynomial number of demonstrations. (2) For general reward functions, we propose black-box descent methods based on evolutionary strategies capable of working with nonlinear estimators (e.g., neural networks). We evaluate our algorithms in autonomous driving and medical treatment simulations and demonstrate their ability to learn and generalize to unseen contexts.