 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich models are innately best at uncertainty estimation?
Paper and Code
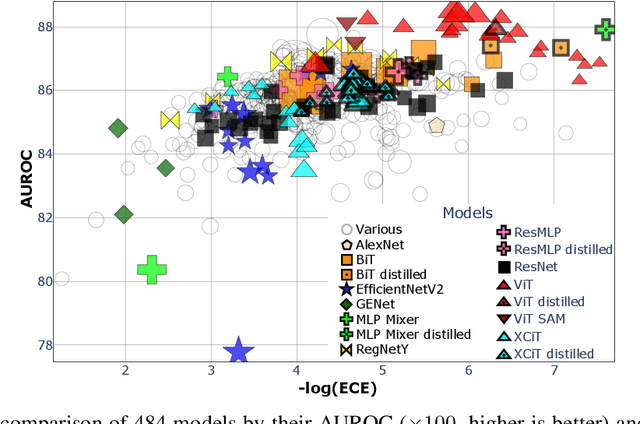
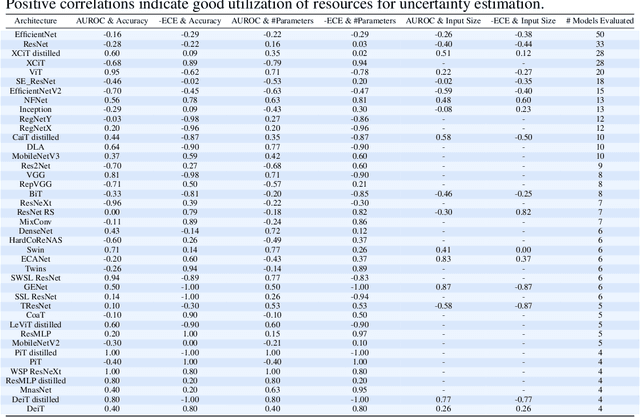
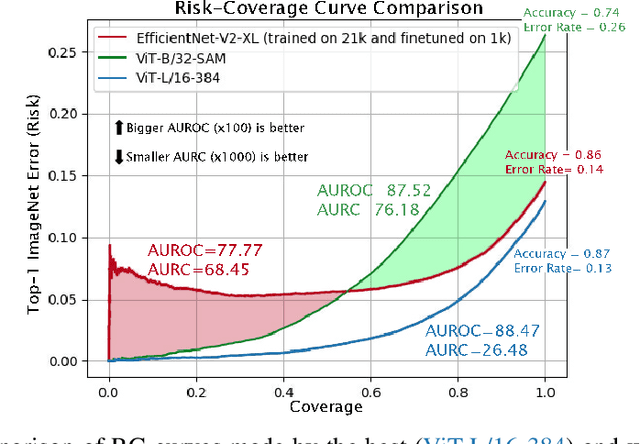
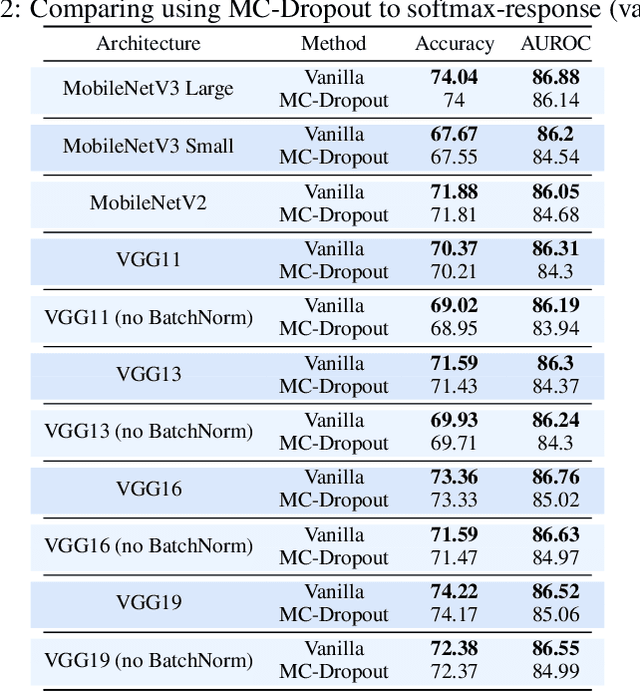
Deep neural networks must be equipped with an uncertainty estimation mechanism when deployed for risk-sensitive tasks. This paper studies the relationship between deep architectures and their training regimes with their corresponding selective prediction and uncertainty estimation performance. We consider both in-distribution uncertainties and class-out-of-distribution ones. Moreover, we consider some of the most popular estimation performance metrics previously proposed including AUROC, ECE, AURC, and coverage for selective accuracy constraint. We present a novel and comprehensive study of selective prediction and the uncertainty estimation performance of 484 existing pretrained deep ImageNet classifiers that are available at popular repositories. We identify numerous and previously unknown factors that affect uncertainty estimation and examine the relationships between the different metrics. We find that distillation-based training regimes consistently yield better uncertainty estimations than other training schemes such as vanilla training, pretraining on a larger dataset and adversarial training. We also provide strong empirical evidence showing that ViT is by far the most superior architecture in terms of uncertainty estimation performance, judging by any aspect, in both in-distribution and class-out-of-distribution scenarios.