 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Can We Learn From The Selective Prediction And Uncertainty Estimation Performance Of 523 Imagenet Classifiers
Feb 23, 2023When deployed for risk-sensitive tasks, deep neural networks must include an uncertainty estimation mechanism. Here we examine the relationship between deep architectures and their respective training regimes, with their corresponding selective prediction and uncertainty estimation performance. We consider some of the most popular estimation performance metrics previously proposed including AUROC, ECE, AURC as well as coverage for selective accuracy constraint. We present a novel and comprehensive study of selective prediction and the uncertainty estimation performance of 523 existing pretrained deep ImageNet classifiers that are available in popular repositories. We identify numerous and previously unknown factors that affect uncertainty estimation and examine the relationships between the different metrics. We find that distillation-based training regimes consistently yield better uncertainty estimations than other training schemes such as vanilla training, pretraining on a larger dataset and adversarial training. Moreover, we find a subset of ViT models that outperform any other models in terms of uncertainty estimation performance. For example, we discovered an unprecedented 99% top-1 selective accuracy on ImageNet at 47% coverage (and 95% top-1 accuracy at 80%) for a ViT model, whereas a competing EfficientNet-V2-XL cannot obtain these accuracy constraints at any level of coverage. Our companion paper, also published in ICLR 2023 (A framework for benchmarking class-out-of-distribution detection and its application to ImageNet), examines the performance of these classifiers in a class-out-of-distribution setting.
* Published in ICLR 2023. arXiv admin note: substantial text overlap with arXiv:2206.02152
A framework for benchmarking class-out-of-distribution detection and its application to ImageNet
Feb 23, 2023When deployed for risk-sensitive tasks, deep neural networks must be able to detect instances with labels from outside the distribution for which they were trained. In this paper we present a novel framework to benchmark the ability of image classifiers to detect class-out-of-distribution instances (i.e., instances whose true labels do not appear in the training distribution) at various levels of detection difficulty. We apply this technique to ImageNet, and benchmark 525 pretrained, publicly available, ImageNet-1k classifiers. The code for generating a benchmark for any ImageNet-1k classifier, along with the benchmarks prepared for the above-mentioned 525 models is available at https://github.com/mdabbah/COOD_benchmarking. The usefulness of the proposed framework and its advantage over alternative existing benchmarks is demonstrated by analyzing the results obtained for these models, which reveals numerous novel observations including: (1) knowledge distillation consistently improves class-out-of-distribution (C-OOD) detection performance; (2) a subset of ViTs performs better C-OOD detection than any other model; (3) the language--vision CLIP model achieves good zero-shot detection performance, with its best instance outperforming 96% of all other models evaluated; (4) accuracy and in-distribution ranking are positively correlated to C-OOD detection; and (5) we compare various confidence functions for C-OOD detection. Our companion paper, also published in ICLR 2023 (What Can We Learn From The Selective Prediction And Uncertainty Estimation Performance Of 523 Imagenet Classifiers), examines the uncertainty estimation performance (ranking, calibration, and selective prediction performance) of these classifiers in an in-distribution setting.
* Published in ICLR 2023. arXiv admin note: text overlap with arXiv:2206.02152
Which models are innately best at uncertainty estimation?
Jun 05, 2022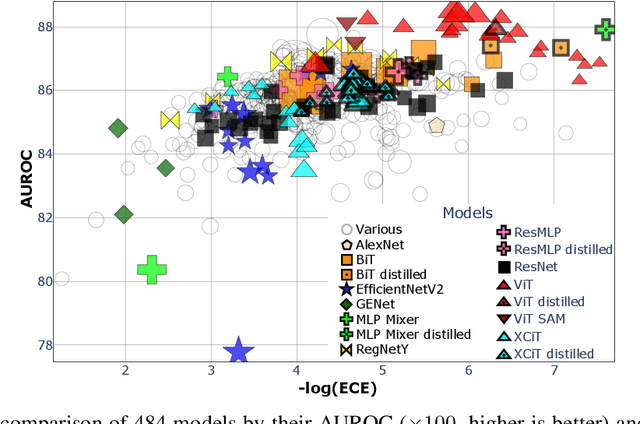
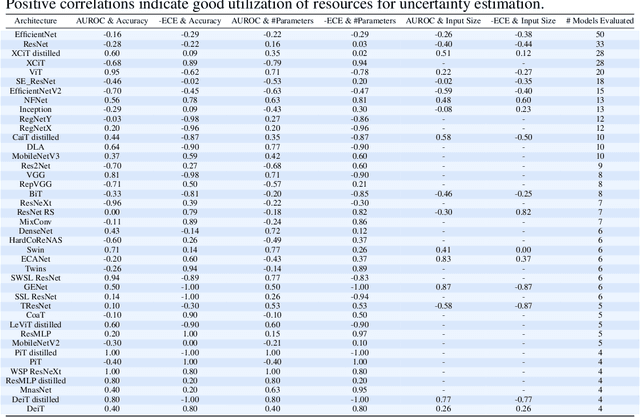
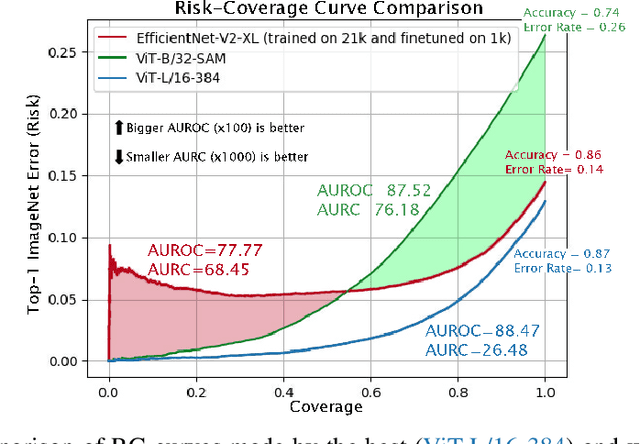
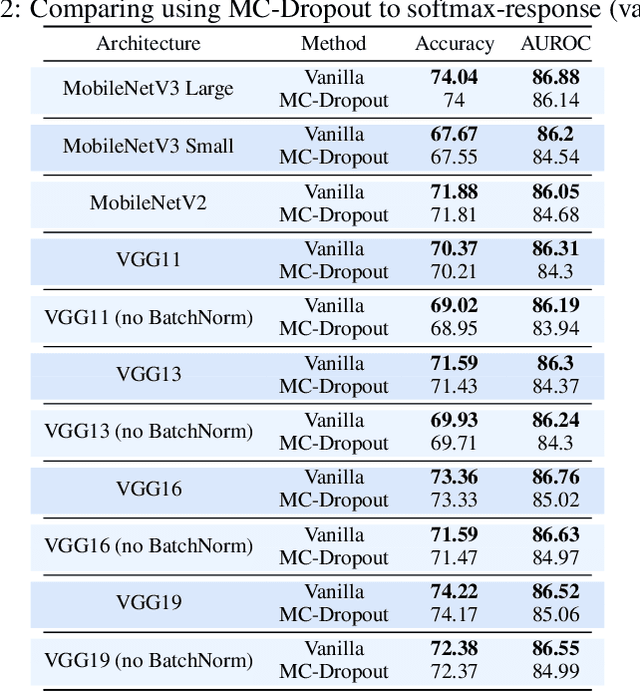
Deep neural networks must be equipped with an uncertainty estimation mechanism when deployed for risk-sensitive tasks. This paper studies the relationship between deep architectures and their training regimes with their corresponding selective prediction and uncertainty estimation performance. We consider both in-distribution uncertainties and class-out-of-distribution ones. Moreover, we consider some of the most popular estimation performance metrics previously proposed including AUROC, ECE, AURC, and coverage for selective accuracy constraint. We present a novel and comprehensive study of selective prediction and the uncertainty estimation performance of 484 existing pretrained deep ImageNet classifiers that are available at popular repositories. We identify numerous and previously unknown factors that affect uncertainty estimation and examine the relationships between the different metrics. We find that distillation-based training regimes consistently yield better uncertainty estimations than other training schemes such as vanilla training, pretraining on a larger dataset and adversarial training. We also provide strong empirical evidence showing that ViT is by far the most superior architecture in terms of uncertainty estimation performance, judging by any aspect, in both in-distribution and class-out-of-distribution scenarios.
Using Fictitious Class Representations to Boost Discriminative Zero-Shot Learners
Nov 26, 2021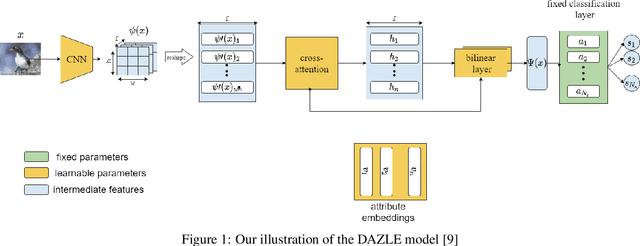
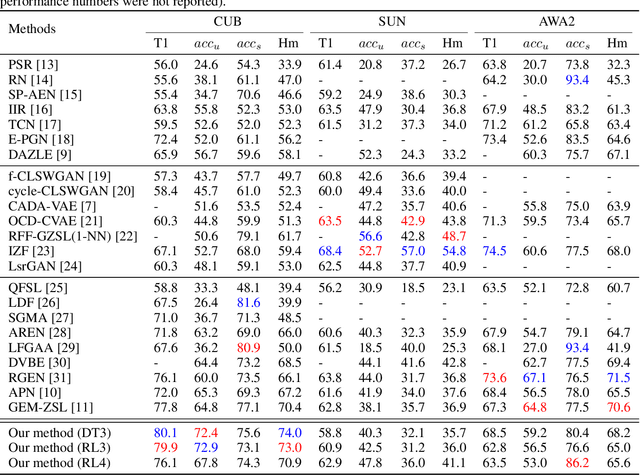
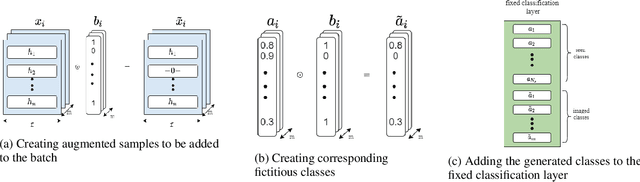

Focusing on discriminative zero-shot learning, in this work we introduce a novel mechanism that dynamically augments during training the set of seen classes to produce additional fictitious classes. These fictitious classes diminish the model's tendency to fixate during training on attribute correlations that appear in the training set but will not appear in newly exposed classes. The proposed model is tested within the two formulations of the zero-shot learning framework; namely, generalized zero-shot learning (GZSL) and classical zero-shot learning (CZSL). Our model improves the state-of-the-art performance on the CUB dataset and reaches comparable results on the other common datasets, AWA2 and SUN. We investigate the strengths and weaknesses of our method, including the effects of catastrophic forgetting when training an end-to-end zero-shot model.