 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFold-CP: A Context Parallelism Framework for Biomolecular Modeling
Mar 16, 2026Understanding cellular machinery requires atomic-scale reconstruction of large biomolecular assemblies. However, predicting the structures of these systems has been constrained by hardware memory requirements of models like AlphaFold 3, imposing a practical ceiling of a few thousand residues that can be processed on a single GPU. Here we present NVIDIA BioNeMo Fold-CP, a context parallelism framework that overcomes this barrier by distributing the inference and training pipelines of co-folding models across multiple GPUs. We use the Boltz models as open source reference architectures and implement custom multidimensional primitives that efficiently parallelize both the dense triangular updates and the irregular, data-dependent pattern of window-batched local attention. Our approach achieves efficient memory scaling; for an N-token input distributed across P GPUs, per-device memory scales as $O(N^2/P)$, enabling the structure prediction of assemblies exceeding 30,000 residues on 64 NVIDIA B300 GPUs. We demonstrate the scientific utility of this approach through successful developer use cases: Fold-CP enabled the scoring of over 90% of Comprehensive Resource of Mammalian protein complexes (CORUM) database, as well as folding of disease-relevant PI4KA lipid kinase complex bound to an intrinsically disordered region without cropping. By providing a scalable pathway for modeling massive systems with full global context, Fold-CP represents a significant step toward the realization of a virtual cell.
Multitask finetuning and acceleration of chemical pretrained models for small molecule drug property prediction
Oct 14, 2025Chemical pretrained models, sometimes referred to as foundation models, are receiving considerable interest for drug discovery applications. The general chemical knowledge extracted from self-supervised training has the potential to improve predictions for critical drug discovery endpoints, including on-target potency and ADMET properties. Multi-task learning has previously been successfully leveraged to improve predictive models. Here, we show that enabling multitasking in finetuning of chemical pretrained graph neural network models such as Kinetic GROVER Multi-Task (KERMT), an enhanced version of the GROVER model, and Knowledge-guided Pre-training of Graph Transformer (KGPT) significantly improves performance over non-pretrained graph neural network models. Surprisingly, we find that the performance improvement from finetuning KERMT in a multitask manner is most significant at larger data sizes. Additionally, we publish two multitask ADMET data splits to enable more accurate benchmarking of multitask deep learning methods for drug property prediction. Finally, we provide an accelerated implementation of the KERMT model on GitHub, unlocking large-scale pretraining, finetuning, and inference in industrial drug discovery workflows.
Rethinking Molecule Synthesizability with Chain-of-Reaction
Sep 19, 2025A well-known pitfall of molecular generative models is that they are not guaranteed to generate synthesizable molecules. There have been considerable attempts to address this problem, but given the exponentially large combinatorial space of synthesizable molecules, existing methods have shown limited coverage of the space and poor molecular optimization performance. To tackle these problems, we introduce ReaSyn, a generative framework for synthesizable projection where the model explores the neighborhood of given molecules in the synthesizable space by generating pathways that result in synthesizable analogs. To fully utilize the chemical knowledge contained in the synthetic pathways, we propose a novel perspective that views synthetic pathways akin to reasoning paths in large language models (LLMs). Specifically, inspired by chain-of-thought (CoT) reasoning in LLMs, we introduce the chain-of-reaction (CoR) notation that explicitly states reactants, reaction types, and intermediate products for each step in a pathway. With the CoR notation, ReaSyn can get dense supervision in every reaction step to explicitly learn chemical reaction rules during supervised training and perform step-by-step reasoning. In addition, to further enhance the reasoning capability of ReaSyn, we propose reinforcement learning (RL)-based finetuning and goal-directed test-time compute scaling tailored for synthesizable projection. ReaSyn achieves the highest reconstruction rate and pathway diversity in synthesizable molecule reconstruction and the highest optimization performance in synthesizable goal-directed molecular optimization, and significantly outperforms previous synthesizable projection methods in synthesizable hit expansion. These results highlight ReaSyn's superior ability to navigate combinatorially-large synthesizable chemical space.
Applications of Modular Co-Design for De Novo 3D Molecule Generation
May 23, 2025De novo 3D molecule generation is a pivotal task in drug discovery. However, many recent geometric generative models struggle to produce high-quality 3D structures, even if they maintain 2D validity and topological stability. To tackle this issue and enhance the learning of effective molecular generation dynamics, we present Megalodon-a family of scalable transformer models. These models are enhanced with basic equivariant layers and trained using a joint continuous and discrete denoising co-design objective. We assess Megalodon's performance on established molecule generation benchmarks and introduce new 3D structure benchmarks that evaluate a model's capability to generate realistic molecular structures, particularly focusing on energetics. We show that Megalodon achieves state-of-the-art results in 3D molecule generation, conditional structure generation, and structure energy benchmarks using diffusion and flow matching. Furthermore, doubling the number of parameters in Megalodon to 40M significantly enhances its performance, generating up to 49x more valid large molecules and achieving energy levels that are 2-10x lower than those of the best prior generative models.
GenMol: A Drug Discovery Generalist with Discrete Diffusion
Jan 10, 2025



Drug discovery is a complex process that involves multiple scenarios and stages, such as fragment-constrained molecule generation, hit generation and lead optimization. However, existing molecular generative models can only tackle one or two of these scenarios and lack the flexibility to address various aspects of the drug discovery pipeline. In this paper, we present Generalist Molecular generative model (GenMol), a versatile framework that addresses these limitations by applying discrete diffusion to the Sequential Attachment-based Fragment Embedding (SAFE) molecular representation. GenMol generates SAFE sequences through non-autoregressive bidirectional parallel decoding, thereby allowing utilization of a molecular context that does not rely on the specific token ordering and enhanced computational efficiency. Moreover, under the discrete diffusion framework, we introduce fragment remasking, a strategy that optimizes molecules by replacing fragments with masked tokens and regenerating them, enabling effective exploration of chemical space. GenMol significantly outperforms the previous GPT-based model trained on SAFE representations in de novo generation and fragment-constrained generation, and achieves state-of-the-art performance in goal-directed hit generation and lead optimization. These experimental results demonstrate that GenMol can tackle a wide range of drug discovery tasks, providing a unified and versatile approach for molecular design.
Molecule Generation with Fragment Retrieval Augmentation
Nov 18, 2024



Fragment-based drug discovery, in which molecular fragments are assembled into new molecules with desirable biochemical properties, has achieved great success. However, many fragment-based molecule generation methods show limited exploration beyond the existing fragments in the database as they only reassemble or slightly modify the given ones. To tackle this problem, we propose a new fragment-based molecule generation framework with retrieval augmentation, namely Fragment Retrieval-Augmented Generation (f-RAG). f-RAG is based on a pre-trained molecular generative model that proposes additional fragments from input fragments to complete and generate a new molecule. Given a fragment vocabulary, f-RAG retrieves two types of fragments: (1) hard fragments, which serve as building blocks that will be explicitly included in the newly generated molecule, and (2) soft fragments, which serve as reference to guide the generation of new fragments through a trainable fragment injection module. To extrapolate beyond the existing fragments, f-RAG updates the fragment vocabulary with generated fragments via an iterative refinement process which is further enhanced with post-hoc genetic fragment modification. f-RAG can achieve an improved exploration-exploitation trade-off by maintaining a pool of fragments and expanding it with novel and high-quality fragments through a strong generative prior.
BioNeMo Framework: a modular, high-performance library for AI model development in drug discovery
Nov 15, 2024



Artificial Intelligence models encoding biology and chemistry are opening new routes to high-throughput and high-quality in-silico drug development. However, their training increasingly relies on computational scale, with recent protein language models (pLM) training on hundreds of graphical processing units (GPUs). We introduce the BioNeMo Framework to facilitate the training of computational biology and chemistry AI models across hundreds of GPUs. Its modular design allows the integration of individual components, such as data loaders, into existing workflows and is open to community contributions. We detail technical features of the BioNeMo Framework through use cases such as pLM pre-training and fine-tuning. On 256 NVIDIA A100s, BioNeMo Framework trains a three billion parameter BERT-based pLM on over one trillion tokens in 4.2 days. The BioNeMo Framework is open-source and free for everyone to use.
LinkLogic: A New Method and Benchmark for Explainable Knowledge Graph Predictions
Jun 02, 2024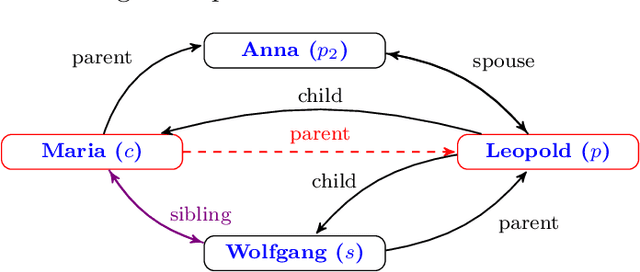
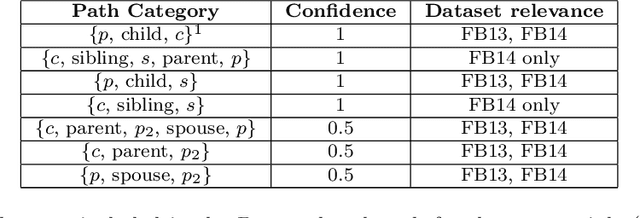
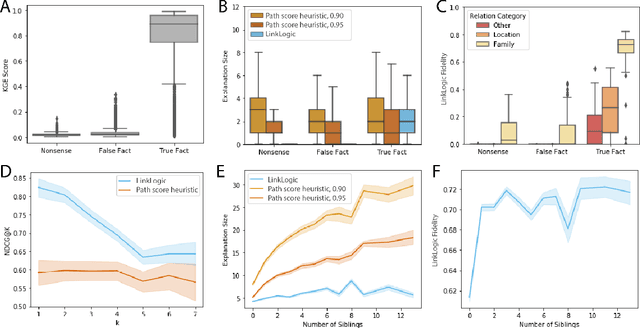
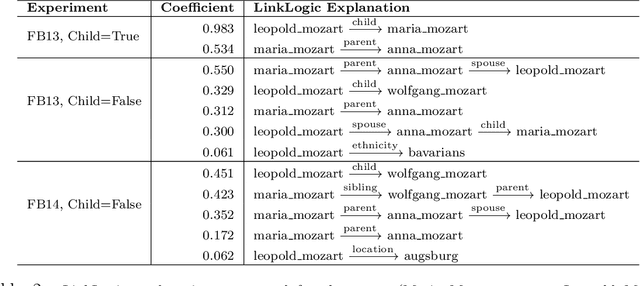
While there are a plethora of methods for link prediction in knowledge graphs, state-of-the-art approaches are often black box, obfuscating model reasoning and thereby limiting the ability of users to make informed decisions about model predictions. Recently, methods have emerged to generate prediction explanations for Knowledge Graph Embedding models, a widely-used class of methods for link prediction. The question then becomes, how well do these explanation systems work? To date this has generally been addressed anecdotally, or through time-consuming user research. In this work, we present an in-depth exploration of a simple link prediction explanation method we call LinkLogic, that surfaces and ranks explanatory information used for the prediction. Importantly, we construct the first-ever link prediction explanation benchmark, based on family structures present in the FB13 dataset. We demonstrate the use of this benchmark as a rich evaluation sandbox, probing LinkLogic quantitatively and qualitatively to assess the fidelity, selectivity and relevance of the generated explanations. We hope our work paves the way for more holistic and empirical assessment of knowledge graph prediction explanation methods in the future.
Pseudo-Riemannian Embedding Models for Multi-Relational Graph Representations
Dec 02, 2022
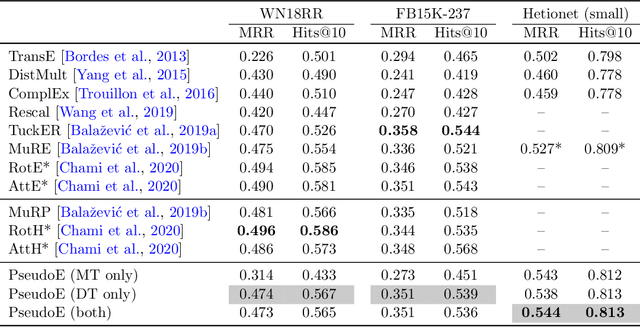
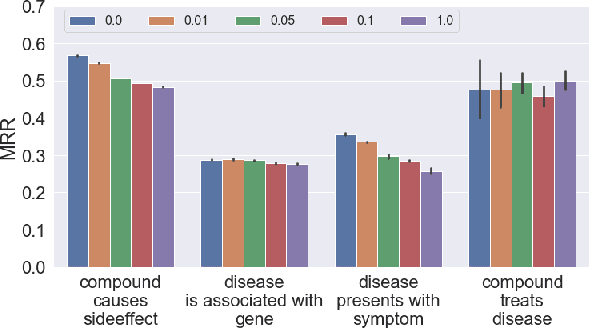
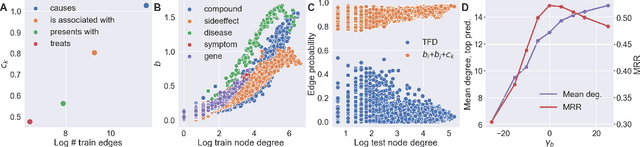
In this paper we generalize single-relation pseudo-Riemannian graph embedding models to multi-relational networks, and show that the typical approach of encoding relations as manifold transformations translates from the Riemannian to the pseudo-Riemannian case. In addition we construct a view of relations as separate spacetime submanifolds of multi-time manifolds, and consider an interpolation between a pseudo-Riemannian embedding model and its Wick-rotated Riemannian counterpart. We validate these extensions in the task of link prediction, focusing on flat Lorentzian manifolds, and demonstrate their use in both knowledge graph completion and knowledge discovery in a biological domain.
* 11 pages, 3 figures, AKBC 2022 conference
Directed Graph Embeddings in Pseudo-Riemannian Manifolds
Jun 16, 2021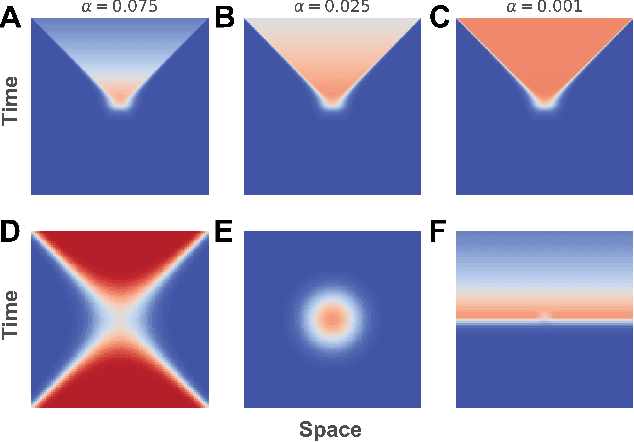

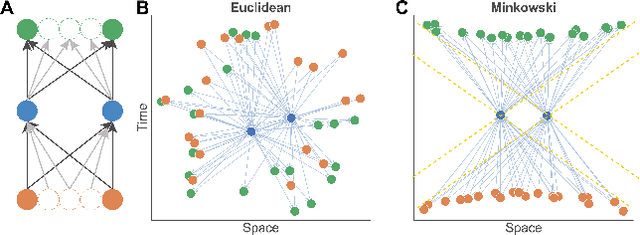
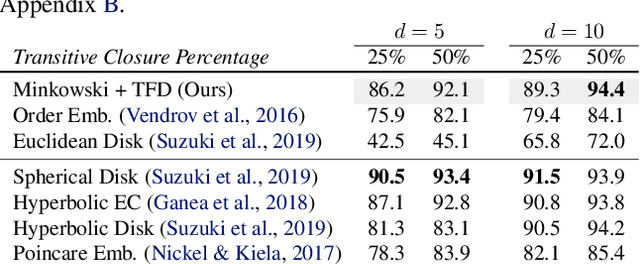
The inductive biases of graph representation learning algorithms are often encoded in the background geometry of their embedding space. In this paper, we show that general directed graphs can be effectively represented by an embedding model that combines three components: a pseudo-Riemannian metric structure, a non-trivial global topology, and a unique likelihood function that explicitly incorporates a preferred direction in embedding space. We demonstrate the representational capabilities of this method by applying it to the task of link prediction on a series of synthetic and real directed graphs from natural language applications and biology. In particular, we show that low-dimensional cylindrical Minkowski and anti-de Sitter spacetimes can produce equal or better graph representations than curved Riemannian manifolds of higher dimensions.