 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieve to Explain: Evidence-driven Predictions with Language Models
Feb 06, 2024
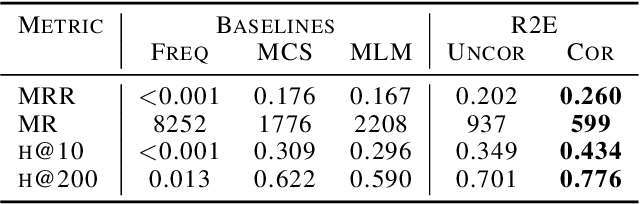


Machine learning models, particularly language models, are notoriously difficult to introspect. Black-box models can mask both issues in model training and harmful biases. For human-in-the-loop processes, opaque predictions can drive lack of trust, limiting a model's impact even when it performs effectively. To address these issues, we introduce Retrieve to Explain (R2E). R2E is a retrieval-based language model that prioritizes amongst a pre-defined set of possible answers to a research question based on the evidence in a document corpus, using Shapley values to identify the relative importance of pieces of evidence to the final prediction. R2E can adapt to new evidence without retraining, and incorporate structured data through templating into natural language. We assess on the use case of drug target identification from published scientific literature, where we show that the model outperforms an industry-standard genetics-based approach on predicting clinical trial outcomes.
Proxy-based Zero-Shot Entity Linking by Effective Candidate Retrieval
Jan 30, 2023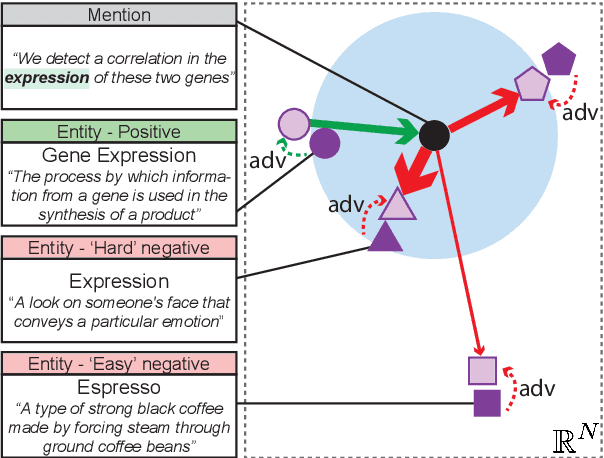

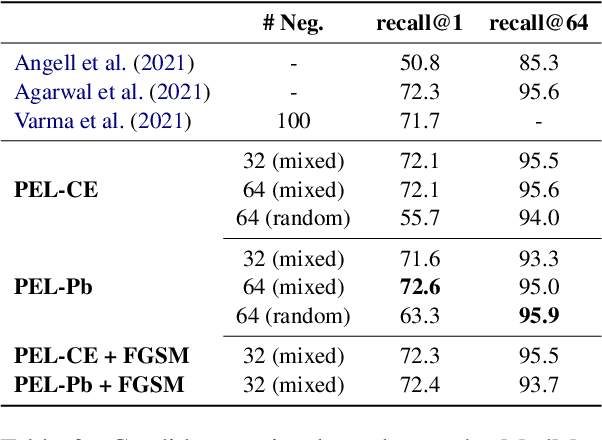

A recent advancement in the domain of biomedical Entity Linking is the development of powerful two-stage algorithms, an initial candidate retrieval stage that generates a shortlist of entities for each mention, followed by a candidate ranking stage. However, the effectiveness of both stages are inextricably dependent on computationally expensive components. Specifically, in candidate retrieval via dense representation retrieval it is important to have hard negative samples, which require repeated forward passes and nearest neighbour searches across the entire entity label set throughout training. In this work, we show that pairing a proxy-based metric learning loss with an adversarial regularizer provides an efficient alternative to hard negative sampling in the candidate retrieval stage. In particular, we show competitive performance on the recall@1 metric, thereby providing the option to leave out the expensive candidate ranking step. Finally, we demonstrate how the model can be used in a zero-shot setting to discover out of knowledge base biomedical entities.
Pseudo-Riemannian Embedding Models for Multi-Relational Graph Representations
Dec 02, 2022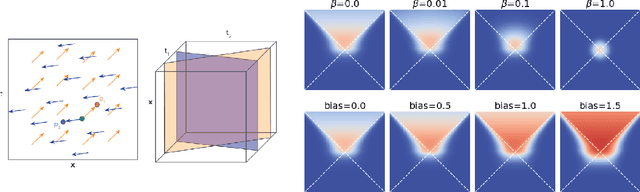
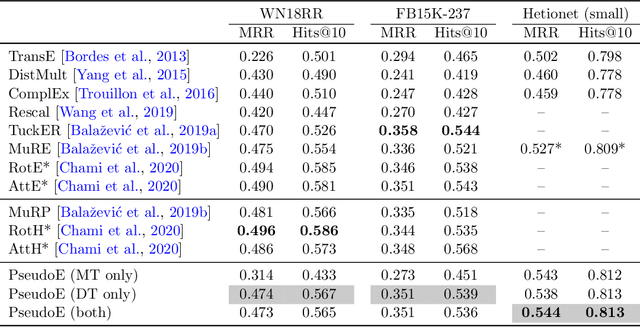
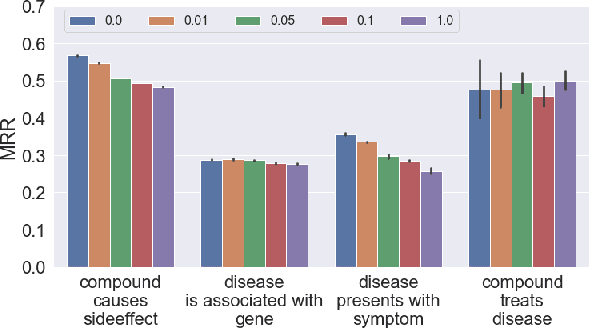
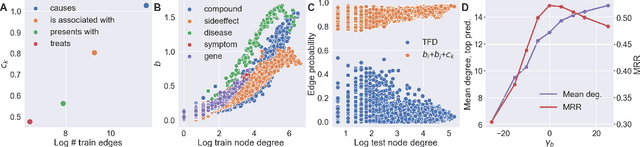
In this paper we generalize single-relation pseudo-Riemannian graph embedding models to multi-relational networks, and show that the typical approach of encoding relations as manifold transformations translates from the Riemannian to the pseudo-Riemannian case. In addition we construct a view of relations as separate spacetime submanifolds of multi-time manifolds, and consider an interpolation between a pseudo-Riemannian embedding model and its Wick-rotated Riemannian counterpart. We validate these extensions in the task of link prediction, focusing on flat Lorentzian manifolds, and demonstrate their use in both knowledge graph completion and knowledge discovery in a biological domain.
* 11 pages, 3 figures, AKBC 2022 conference
Directed Graph Embeddings in Pseudo-Riemannian Manifolds
Jun 16, 2021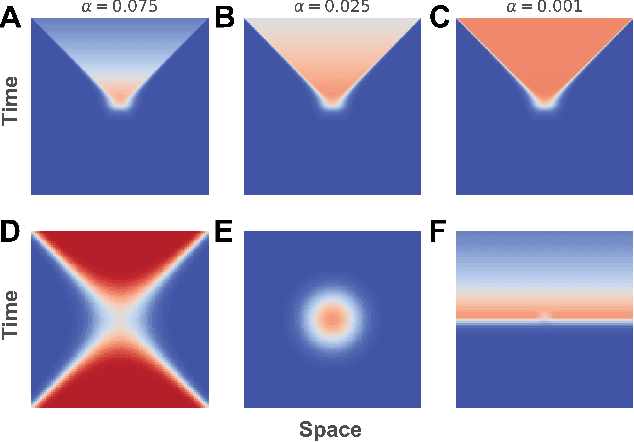

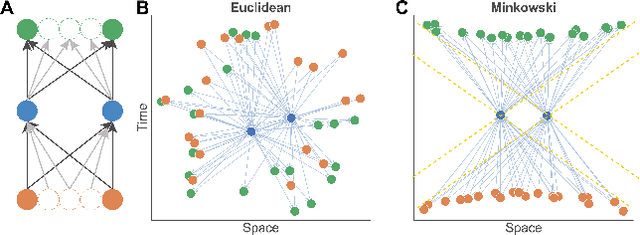
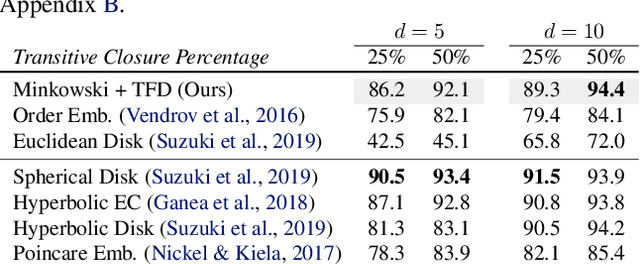
The inductive biases of graph representation learning algorithms are often encoded in the background geometry of their embedding space. In this paper, we show that general directed graphs can be effectively represented by an embedding model that combines three components: a pseudo-Riemannian metric structure, a non-trivial global topology, and a unique likelihood function that explicitly incorporates a preferred direction in embedding space. We demonstrate the representational capabilities of this method by applying it to the task of link prediction on a series of synthetic and real directed graphs from natural language applications and biology. In particular, we show that low-dimensional cylindrical Minkowski and anti-de Sitter spacetimes can produce equal or better graph representations than curved Riemannian manifolds of higher dimensions.