 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Banking Foundational Model: Learning Language Representations from Few Financial Transactions
Nov 15, 2025



We introduced a multimodal foundational model for financial transactions that integrates both structured attributes and unstructured textual descriptions into a unified representation. By adapting masked language modeling to transaction sequences, we demonstrated that our approach not only outperforms classical feature engineering and discrete event sequence methods but is also particularly effective in data-scarce Open Banking scenarios. To our knowledge, this is the first large-scale study across thousands of financial institutions in North America, providing evidence that multimodal representations can generalize across geographies and institutions. These results highlight the potential of self-supervised models to advance financial applications ranging from fraud prevention and credit risk to customer insights
Hierarchical Fallback Architecture for High Risk Online Machine Learning Inference
Jan 29, 2025

Open Banking powered machine learning applications require novel robustness approaches to deal with challenging stress and failure scenarios. In this paper we propose an hierarchical fallback architecture for improving robustness in high risk machine learning applications with a focus in the financial domain. We define generic failure scenarios often found in online inference that depend on external data providers and we describe in detail how to apply the hierarchical fallback architecture to address them. Finally, we offer a real world example of its applicability in the industry for near-real time transactional fraud risk evaluation using Open Banking data and under extreme stress scenarios.
LinkLogic: A New Method and Benchmark for Explainable Knowledge Graph Predictions
Jun 02, 2024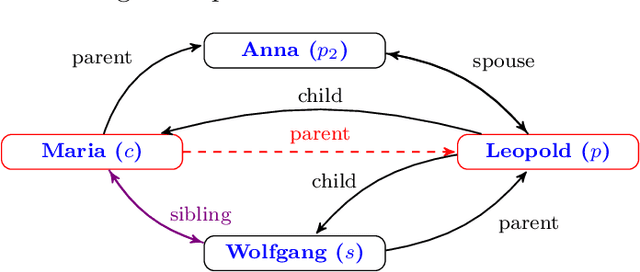
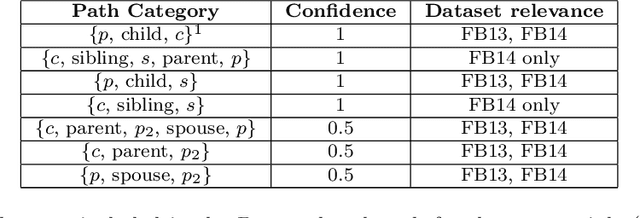
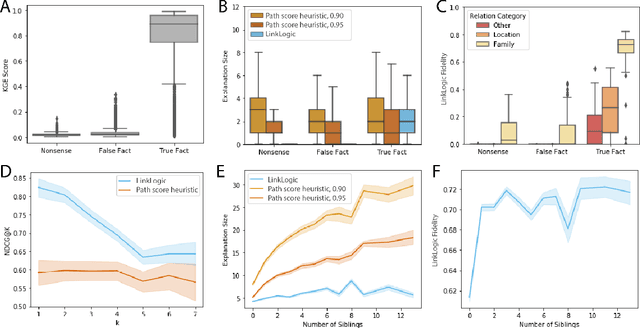
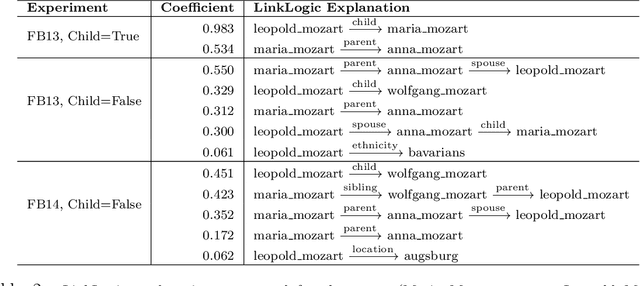
While there are a plethora of methods for link prediction in knowledge graphs, state-of-the-art approaches are often black box, obfuscating model reasoning and thereby limiting the ability of users to make informed decisions about model predictions. Recently, methods have emerged to generate prediction explanations for Knowledge Graph Embedding models, a widely-used class of methods for link prediction. The question then becomes, how well do these explanation systems work? To date this has generally been addressed anecdotally, or through time-consuming user research. In this work, we present an in-depth exploration of a simple link prediction explanation method we call LinkLogic, that surfaces and ranks explanatory information used for the prediction. Importantly, we construct the first-ever link prediction explanation benchmark, based on family structures present in the FB13 dataset. We demonstrate the use of this benchmark as a rich evaluation sandbox, probing LinkLogic quantitatively and qualitatively to assess the fidelity, selectivity and relevance of the generated explanations. We hope our work paves the way for more holistic and empirical assessment of knowledge graph prediction explanation methods in the future.
Building a Language-Learning Game for Brazilian Indigenous Languages: A Case of Study
Mar 21, 2024



In this paper we discuss a first attempt to build a language learning game for brazilian indigenous languages and the challenges around it. We present a design for the tool with gamification aspects. Then we describe a process to automatically generate language exercises and questions from a dependency treebank and a lexical database for Tupian languages. We discuss the limitations of our prototype highlighting ethical and practical implementation concerns. Finally, we conclude that new data gathering processes should be established in partnership with indigenous communities and oriented for educational purposes.