 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGCCN: Global Context Convolutional Network
Paper and Code
Oct 22, 2021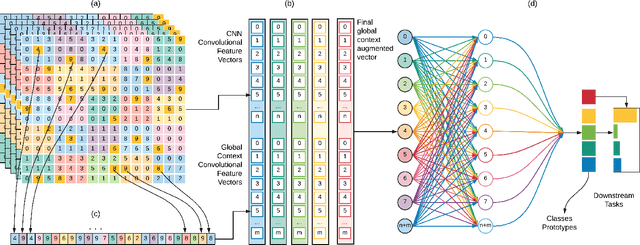
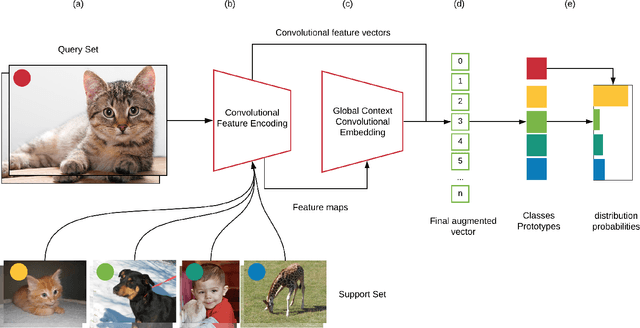
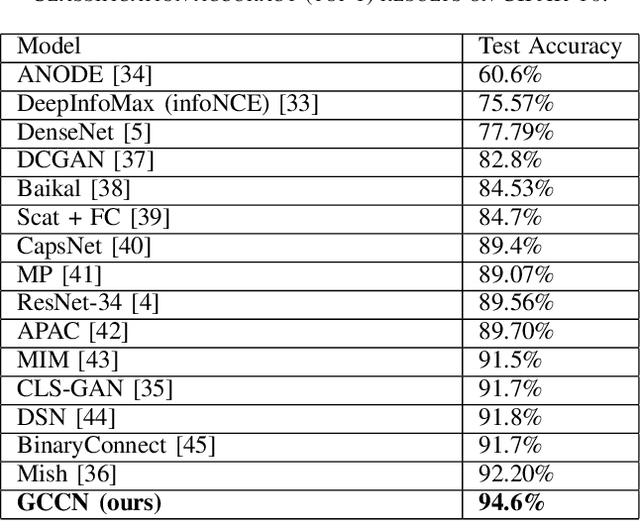
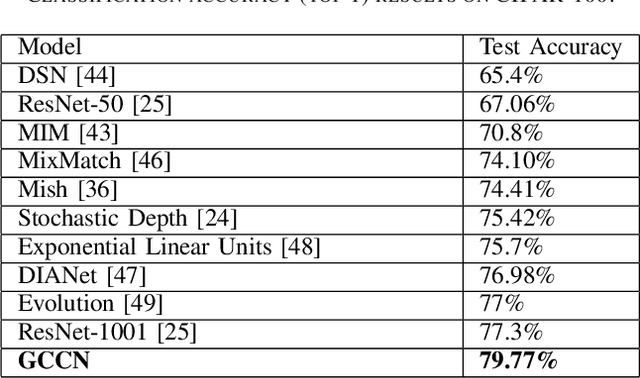
In this paper, we propose Global Context Convolutional Network (GCCN) for visual recognition. GCCN computes global features representing contextual information across image patches. These global contextual features are defined as local maxima pixels with high visual sharpness in each patch. These features are then concatenated and utilised to augment the convolutional features. The learnt feature vector is normalised using the global context features using Frobenius norm. This straightforward approach achieves high accuracy in compassion to the state-of-the-art methods with 94.6% and 95.41% on CIFAR-10 and STL-10 datasets, respectively. To explore potential impact of GCCN on other visual representation tasks, we implemented GCCN as a based model to few-shot image classification. We learn metric distances between the augmented feature vectors and their prototypes representations, similar to Prototypical and Matching Networks. GCCN outperforms state-of-the-art few-shot learning methods achieving 99.9%, 84.8% and 80.74% on Omniglot, MiniImageNet and CUB-200, respectively. GCCN has significantly improved on the accuracy of state-of-the-art prototypical and matching networks by up to 30% in different few-shot learning scenarios.