 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignature-Graph Networks
Paper and Code
Oct 22, 2021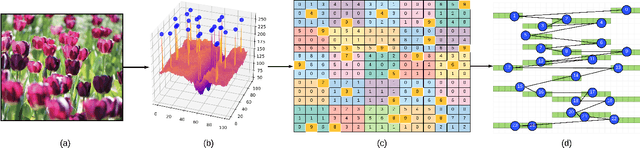
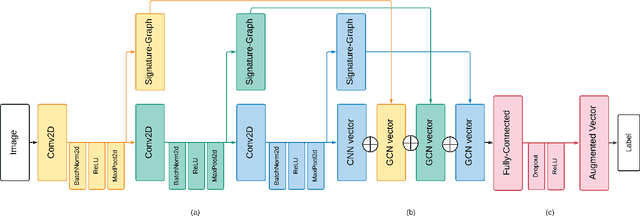
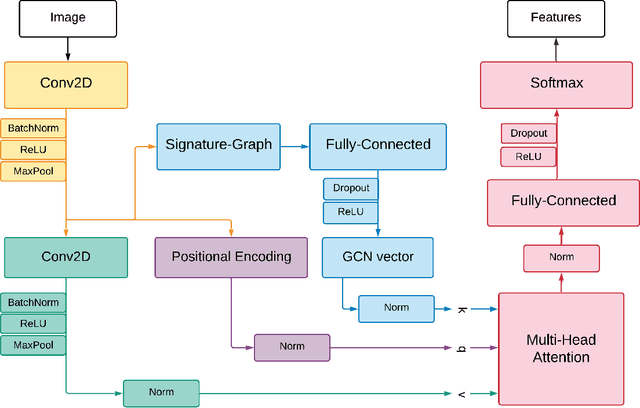
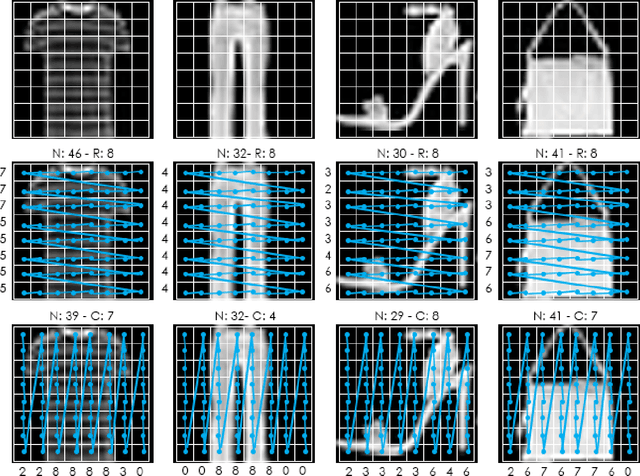
We propose a novel approach for visual representation learning called Signature-Graph Neural Networks (SGN). SGN learns latent global structures that augment the feature representation of Convolutional Neural Networks (CNN). SGN constructs unique undirected graphs for each image based on the CNN feature maps. The feature maps are partitioned into a set of equal and non-overlapping patches. The graph nodes are located on high-contrast sharp convolution features with the local maxima or minima in these patches. The node embeddings are aggregated through novel Signature-Graphs based on horizontal and vertical edge connections. The representation vectors are then computed based on the spectral Laplacian eigenvalues of the graphs. SGN outperforms existing methods of recent graph convolutional networks, generative adversarial networks, and auto-encoders with image classification accuracy of 99.65% on ASIRRA, 99.91% on MNIST, 98.55% on Fashion-MNIST, 96.18% on CIFAR-10, 84.71% on CIFAR-100, 94.36% on STL10, and 95.86% on SVHN datasets. We also introduce a novel implementation of the state-of-the-art multi-head attention (MHA) on top of the proposed SGN. Adding SGN to MHA improved the image classification accuracy from 86.92% to 94.36% on the STL10 dataset