 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair Polylog-Approximate Low-Cost Hierarchical Clustering
Nov 21, 2023Research in fair machine learning, and particularly clustering, has been crucial in recent years given the many ethical controversies that modern intelligent systems have posed. Ahmadian et al. [2020] established the study of fairness in \textit{hierarchical} clustering, a stronger, more structured variant of its well-known flat counterpart, though their proposed algorithm that optimizes for Dasgupta's [2016] famous cost function was highly theoretical. Knittel et al. [2023] then proposed the first practical fair approximation for cost, however they were unable to break the polynomial-approximate barrier they posed as a hurdle of interest. We break this barrier, proposing the first truly polylogarithmic-approximate low-cost fair hierarchical clustering, thus greatly bridging the gap between the best fair and vanilla hierarchical clustering approximations.
Generalized Reductions: Making any Hierarchical Clustering Fair and Balanced with Low Cost
May 27, 2022
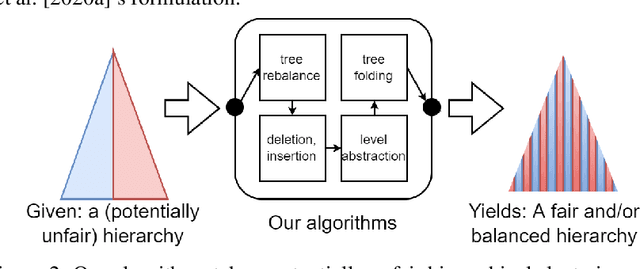

Clustering is a fundamental building block of modern statistical analysis pipelines. Fair clustering has seen much attention from the machine learning community in recent years. We are some of the first to study fairness in the context of hierarchical clustering, after the results of Ahmadian et al. from NeurIPS in 2020. We evaluate our results using Dasgupta's cost function, perhaps one of the most prevalent theoretical metrics for hierarchical clustering evaluation. Our work vastly improves the previous $O(n^{5/6}poly\log(n))$ fair approximation for cost to a near polylogarithmic $O(n^\delta poly\log(n))$ fair approximation for any constant $\delta\in(0,1)$. This result establishes a cost-fairness tradeoff and extends to broader fairness constraints than the previous work. We also show how to alter existing hierarchical clusterings to guarantee fairness and cluster balance across any level in the hierarchy.
The Dichotomous Affiliate Stable Matching Problem: Approval-Based Matching with Applicant-Employer Relations
Feb 22, 2022

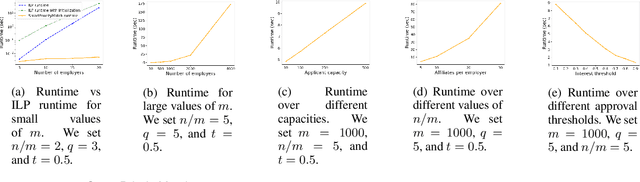
While the stable marriage problem and its variants model a vast range of matching markets, they fail to capture complex agent relationships, such as the affiliation of applicants and employers in an interview marketplace. To model this problem, the existing literature on matching with externalities permits agents to provide complete and total rankings over matchings based off of both their own and their affiliates' matches. This complete ordering restriction is unrealistic, and further the model may have an empty core. To address this, we introduce the Dichotomous Affiliate Stable Matching (DASM) Problem, where agents' preferences indicate dichotomous acceptance or rejection of another agent in the marketplace, both for themselves and their affiliates. We also assume the agent's preferences over entire matchings are determined by a general weighted valuation function of their (and their affiliates') matches. Our results are threefold: (1) we use a human study to show that real-world matching rankings follow our assumed valuation function; (2) we prove that there always exists a stable solution by providing an efficient, easily-implementable algorithm that finds such a solution; and (3) we experimentally validate the efficiency of our algorithm versus a linear-programming-based approach.
Fair Hierarchical Clustering
Jun 19, 2020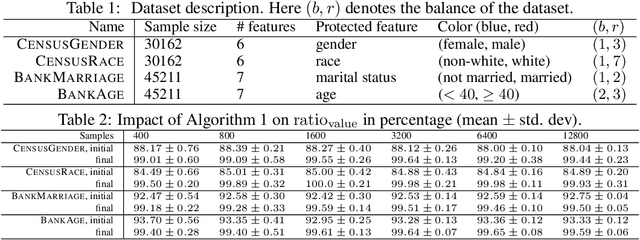
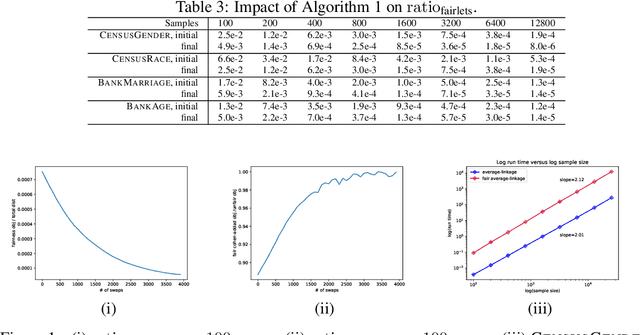
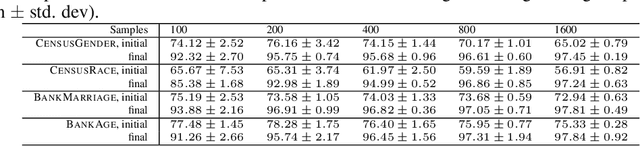

As machine learning has become more prevalent, researchers have begun to recognize the necessity of ensuring machine learning systems are fair. Recently, there has been an interest in defining a notion of fairness that mitigates over-representation in traditional clustering. In this paper we extend this notion to hierarchical clustering, where the goal is to recursively partition the data to optimize a specific objective. For various natural objectives, we obtain simple, efficient algorithms to find a provably good fair hierarchical clustering. Empirically, we show that our algorithms can find a fair hierarchical clustering, with only a negligible loss in the objective.