 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGreedy Algorithm for Structured Bandits: A Sharp Characterization of Asymptotic Success / Failure
Mar 06, 2025We study the greedy (exploitation-only) algorithm in bandit problems with a known reward structure. We allow arbitrary finite reward structures, while prior work focused on a few specific ones. We fully characterize when the greedy algorithm asymptotically succeeds or fails, in the sense of sublinear vs. linear regret as a function of time. Our characterization identifies a partial identifiability property of the problem instance as the necessary and sufficient condition for the asymptotic success. Notably, once this property holds, the problem becomes easy -- any algorithm will succeed (in the same sense as above), provided it satisfies a mild non-degeneracy condition. We further extend our characterization to contextual bandits and interactive decision-making with arbitrary feedback, and demonstrate its broad applicability across various examples.
Offline Reinforcement Learning: Fundamental Barriers for Value Function Approximation
Nov 21, 2021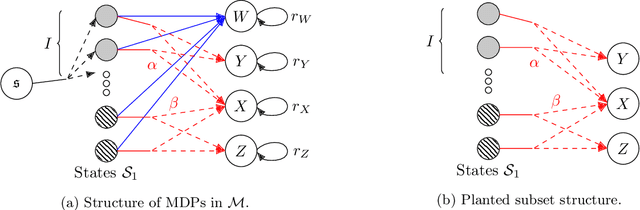

We consider the offline reinforcement learning problem, where the aim is to learn a decision making policy from logged data. Offline RL -- particularly when coupled with (value) function approximation to allow for generalization in large or continuous state spaces -- is becoming increasingly relevant in practice, because it avoids costly and time-consuming online data collection and is well suited to safety-critical domains. Existing sample complexity guarantees for offline value function approximation methods typically require both (1) distributional assumptions (i.e., good coverage) and (2) representational assumptions (i.e., ability to represent some or all $Q$-value functions) stronger than what is required for supervised learning. However, the necessity of these conditions and the fundamental limits of offline RL are not well understood in spite of decades of research. This led Chen and Jiang (2019) to conjecture that concentrability (the most standard notion of coverage) and realizability (the weakest representation condition) alone are not sufficient for sample-efficient offline RL. We resolve this conjecture in the positive by proving that in general, even if both concentrability and realizability are satisfied, any algorithm requires sample complexity polynomial in the size of the state space to learn a non-trivial policy. Our results show that sample-efficient offline reinforcement learning requires either restrictive coverage conditions or representation conditions that go beyond supervised learning, and highlight a phenomenon called over-coverage which serves as a fundamental barrier for offline value function approximation methods. A consequence of our results for reinforcement learning with linear function approximation is that the separation between online and offline RL can be arbitrarily large, even in constant dimension.
Instance-Dependent Complexity of Contextual Bandits and Reinforcement Learning: A Disagreement-Based Perspective
Oct 07, 2020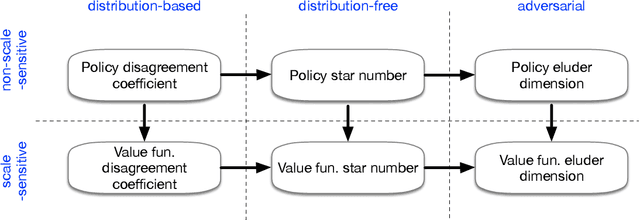

In the classical multi-armed bandit problem, instance-dependent algorithms attain improved performance on "easy" problems with a gap between the best and second-best arm. Are similar guarantees possible for contextual bandits? While positive results are known for certain special cases, there is no general theory characterizing when and how instance-dependent regret bounds for contextual bandits can be achieved for rich, general classes of policies. We introduce a family of complexity measures that are both sufficient and necessary to obtain instance-dependent regret bounds. We then introduce new oracle-efficient algorithms which adapt to the gap whenever possible, while also attaining the minimax rate in the worst case. Finally, we provide structural results that tie together a number of complexity measures previously proposed throughout contextual bandits, reinforcement learning, and active learning and elucidate their role in determining the optimal instance-dependent regret. In a large-scale empirical evaluation, we find that our approach often gives superior results for challenging exploration problems. Turning our focus to reinforcement learning with function approximation, we develop new oracle-efficient algorithms for reinforcement learning with rich observations that obtain optimal gap-dependent sample complexity.
Bypassing the Monster: A Faster and Simpler Optimal Algorithm for Contextual Bandits under Realizability
Apr 05, 2020
We consider the general (stochastic) contextual bandit problem under the realizability assumption, i.e., the expected reward, as a function of contexts and actions, belongs to a general function class $\mathcal{F}$. We design a fast and simple algorithm that achieves the statistically optimal regret with only ${O}(\log T)$ calls to an offline least-squares regression oracle across all $T$ rounds. The number of oracle calls can be further reduced to $O(\log\log T)$ if $T$ is known in advance. Our results provide the first universal and optimal reduction from contextual bandits to offline regression, solving an important open problem for the realizable setting of contextual bandits. A direct consequence of our results is that any advances in offline regression immediately translate to contextual bandits, statistically and computationally. This leads to faster algorithms and improved regret guarantees for broader classes of contextual bandit problems.
Network Revenue Management with Limited Switches: Known and Unknown Demand Distributions
Nov 18, 2019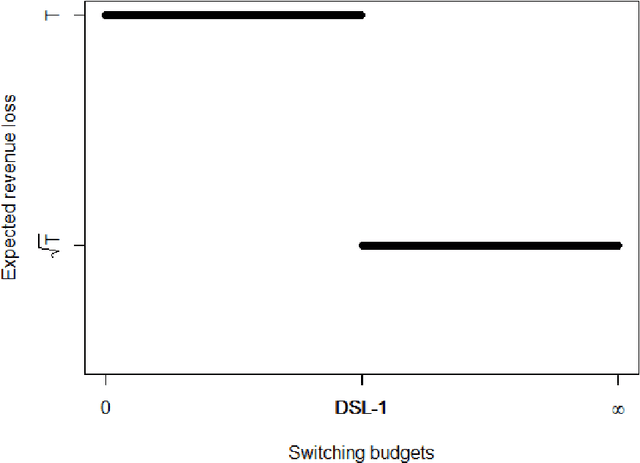
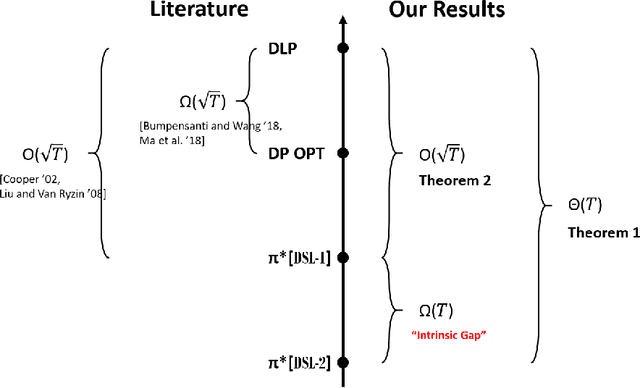
This work is motivated by a practical concern from our retail partner. While they respect the advantages of dynamic pricing, they must limit the number of price changes to be within some constant. We study the classical price-based network revenue management problem, where a retailer has finite initial inventory of multiple resources to sell over a finite time horizon. We consider both known and unknown distribution settings, and derive policies that have the best-possible asymptotic performance in both settings. Our results suggest an intrinsic difference between the expected revenue associated with how many switches are allowed, which further depends on the number of resources. Our results are also the first to show a separation between the regret bounds associated with different number of resources.
Online Pricing with Offline Data: Phase Transition and Inverse Square Law
Nov 06, 2019


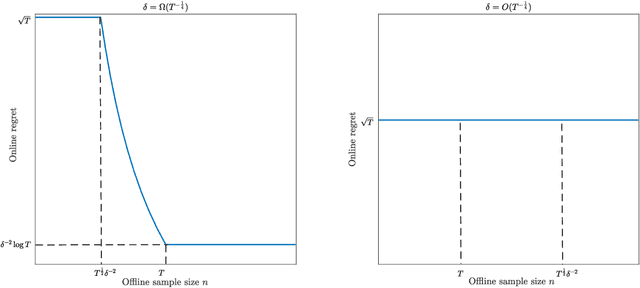
This paper investigates the impact of pre-existing offline data on online learning, in the context of dynamic pricing. We study a single-product dynamic pricing problem over a selling horizon of $T$ periods. The demand in each period is determined by the price of the product according to a linear demand model with unknown parameters. We assume that the seller already has some pre-existing offline data before the start of the selling horizon. The offline data set contains $n$ samples, each of which is an input-output pair consists of a historical price and an associated demand observation. The seller wants to utilize both the pre-existing offline data and the sequential online data to minimize the regret of the online learning process. We characterize the joint effect of the size, location and dispersion of offline data on the optimal regret of the online learning process. Specifically, the size, location and dispersion of offline data are measured by the number of historical samples $n$, the absolute difference between the average historical price and the optimal price $\delta$, and the standard deviation of the historical prices $\sigma$, respectively. We show that the best achievable regret is $\tilde\Theta\left(\sqrt{T}\wedge\frac{T}{n\sigma^2+(n\wedge T)\delta^2}\right)$. We design a learning algorithm based on the "optimism in the face of uncertainty" principle, whose regret is optimal up to a logarithmic factor. Our results reveal surprising transformations of the optimal regret rate with respect to the size of offline data, which we refer to as phase transitions. In addition, our results demonstrate that the location and dispersion of the offline data set also have an intrinsic effect on the optimal regret, and we quantify this effect via the inverse-square law.
Phase Transitions and Cyclic Phenomena in Bandits with Switching Constraints
Jun 06, 2019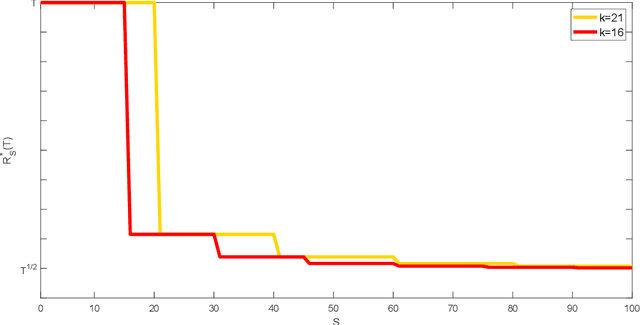

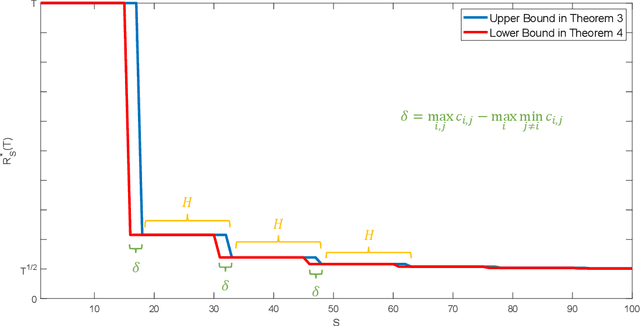
We consider the classical stochastic multi-armed bandit problem with a constraint on the total cost incurred by switching between actions. We prove matching upper and lower bounds on regret and provide near-optimal algorithms for this problem. Surprisingly, we discover phase transitions and cyclic phenomena of the optimal regret. That is, we show that associated with the multi-armed bandit problem, there are phases defined by the number of arms and switching costs, where the regret upper and lower bounds in each phase remain the same and drop significantly between phases. The results enable us to fully characterize the trade-off between regret and incurred switching cost in the stochastic multi-armed bandit problem, contributing new insights to this fundamental problem. Under the general switching cost structure, the results reveal a deep connection between bandit problems and graph traversal problems, such as the shortest Hamiltonian path problem.