 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePower and Limitations of Aggregation in Compound AI Systems
Feb 25, 2026When designing compound AI systems, a common approach is to query multiple copies of the same model and aggregate the responses to produce a synthesized output. Given the homogeneity of these models, this raises the question of whether aggregation unlocks access to a greater set of outputs than querying a single model. In this work, we investigate the power and limitations of aggregation within a stylized principal-agent framework. This framework models how the system designer can partially steer each agent's output through its reward function specification, but still faces limitations due to prompt engineering ability and model capabilities. Our analysis uncovers three natural mechanisms -- feasibility expansion, support expansion, and binding set contraction -- through which aggregation expands the set of outputs that are elicitable by the system designer. We prove that any aggregation operation must implement one of these mechanisms in order to be elicitability-expanding, and that strengthened versions of these mechanisms provide necessary and sufficient conditions that fully characterize elicitability-expansion. Finally, we provide an empirical illustration of our findings for LLMs deployed in a toy reference-generation task. Altogether, our results take a step towards characterizing when compound AI systems can overcome limitations in model capabilities and in prompt engineering.
Flattening Supply Chains: When do Technology Improvements lead to Disintermediation?
Feb 28, 2025In the digital economy, technological innovations make it cheaper to produce high-quality content. For example, generative AI tools reduce costs for creators who develop content to be distributed online, but can also reduce production costs for the users who consume that content. These innovations can thus lead to disintermediation, since consumers may choose to use these technologies directly, bypassing intermediaries. To investigate when technological improvements lead to disintermediation, we study a game with an intermediary, suppliers of a production technology, and consumers. First, we show disintermediation occurs whenever production costs are too high or too low. We then investigate the consequences of disintermediation for welfare and content quality at equilibrium. While the intermediary is welfare-improving, the intermediary extracts all gains to social welfare and its presence can raise or lower content quality. We further analyze how disintermediation is affected by the level of competition between suppliers and the intermediary's fee structure. More broadly, our results take a step towards assessing how production technology innovations affect the survival of intermediaries and impact the digital economy.
Safety vs. Performance: How Multi-Objective Learning Reduces Barriers to Market Entry
Sep 05, 2024



Emerging marketplaces for large language models and other large-scale machine learning (ML) models appear to exhibit market concentration, which has raised concerns about whether there are insurmountable barriers to entry in such markets. In this work, we study this issue from both an economic and an algorithmic point of view, focusing on a phenomenon that reduces barriers to entry. Specifically, an incumbent company risks reputational damage unless its model is sufficiently aligned with safety objectives, whereas a new company can more easily avoid reputational damage. To study this issue formally, we define a multi-objective high-dimensional regression framework that captures reputational damage, and we characterize the number of data points that a new company needs to enter the market. Our results demonstrate how multi-objective considerations can fundamentally reduce barriers to entry -- the required number of data points can be significantly smaller than the incumbent company's dataset size. En route to proving these results, we develop scaling laws for high-dimensional linear regression in multi-objective environments, showing that the scaling rate becomes slower when the dataset size is large, which could be of independent interest.
Accounting for AI and Users Shaping One Another: The Role of Mathematical Models
Apr 18, 2024

As AI systems enter into a growing number of societal domains, these systems increasingly shape and are shaped by user preferences, opinions, and behaviors. However, the design of AI systems rarely accounts for how AI and users shape one another. In this position paper, we argue for the development of formal interaction models which mathematically specify how AI and users shape one another. Formal interaction models can be leveraged to (1) specify interactions for implementation, (2) monitor interactions through empirical analysis, (3) anticipate societal impacts via counterfactual analysis, and (4) control societal impacts via interventions. The design space of formal interaction models is vast, and model design requires careful consideration of factors such as style, granularity, mathematical complexity, and measurability. Using content recommender systems as a case study, we critically examine the nascent literature of formal interaction models with respect to these use-cases and design axes. More broadly, we call for the community to leverage formal interaction models when designing, evaluating, or auditing any AI system which interacts with users.
Impact of Decentralized Learning on Player Utilities in Stackelberg Games
Feb 29, 2024
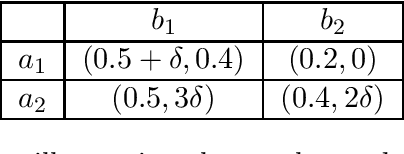


When deployed in the world, a learning agent such as a recommender system or a chatbot often repeatedly interacts with another learning agent (such as a user) over time. In many such two-agent systems, each agent learns separately and the rewards of the two agents are not perfectly aligned. To better understand such cases, we examine the learning dynamics of the two-agent system and the implications for each agent's objective. We model these systems as Stackelberg games with decentralized learning and show that standard regret benchmarks (such as Stackelberg equilibrium payoffs) result in worst-case linear regret for at least one player. To better capture these systems, we construct a relaxed regret benchmark that is tolerant to small learning errors by agents. We show that standard learning algorithms fail to provide sublinear regret, and we develop algorithms to achieve near-optimal $O(T^{2/3})$ regret for both players with respect to these benchmarks. We further design relaxed environments under which faster learning ($O(\sqrt{T})$) is possible. Altogether, our results take a step towards assessing how two-agent interactions in sequential and decentralized learning environments affect the utility of both agents.
Feedback Loops With Language Models Drive In-Context Reward Hacking
Feb 09, 2024



Language models influence the external world: they query APIs that read and write to web pages, generate content that shapes human behavior, and run system commands as autonomous agents. These interactions form feedback loops: LLM outputs affect the world, which in turn affect subsequent LLM outputs. In this work, we show that feedback loops can cause in-context reward hacking (ICRH), where the LLM at test-time optimizes a (potentially implicit) objective but creates negative side effects in the process. For example, consider an LLM agent deployed to increase Twitter engagement; the LLM may retrieve its previous tweets into the context window and make them more controversial, increasing engagement but also toxicity. We identify and study two processes that lead to ICRH: output-refinement and policy-refinement. For these processes, evaluations on static datasets are insufficient -- they miss the feedback effects and thus cannot capture the most harmful behavior. In response, we provide three recommendations for evaluation to capture more instances of ICRH. As AI development accelerates, the effects of feedback loops will proliferate, increasing the need to understand their role in shaping LLM behavior.
Can Probabilistic Feedback Drive User Impacts in Online Platforms?
Jan 25, 2024A common explanation for negative user impacts of content recommender systems is misalignment between the platform's objective and user welfare. In this work, we show that misalignment in the platform's objective is not the only potential cause of unintended impacts on users: even when the platform's objective is fully aligned with user welfare, the platform's learning algorithm can induce negative downstream impacts on users. The source of these user impacts is that different pieces of content may generate observable user reactions (feedback information) at different rates; these feedback rates may correlate with content properties, such as controversiality or demographic similarity of the creator, that affect the user experience. Since differences in feedback rates can impact how often the learning algorithm engages with different content, the learning algorithm may inadvertently promote content with certain such properties. Using the multi-armed bandit framework with probabilistic feedback, we examine the relationship between feedback rates and a learning algorithm's engagement with individual arms for different no-regret algorithms. We prove that no-regret algorithms can exhibit a wide range of dependencies: if the feedback rate of an arm increases, some no-regret algorithms engage with the arm more, some no-regret algorithms engage with the arm less, and other no-regret algorithms engage with the arm approximately the same number of times. From a platform design perspective, our results highlight the importance of looking beyond regret when measuring an algorithm's performance, and assessing the nature of a learning algorithm's engagement with different types of content as well as their resulting downstream impacts.
Clickbait vs. Quality: How Engagement-Based Optimization Shapes the Content Landscape in Online Platforms
Jan 18, 2024



Online content platforms commonly use engagement-based optimization when making recommendations. This encourages content creators to invest in quality, but also rewards gaming tricks such as clickbait. To understand the total impact on the content landscape, we study a game between content creators competing on the basis of engagement metrics and analyze the equilibrium decisions about investment in quality and gaming. First, we show the content created at equilibrium exhibits a positive correlation between quality and gaming, and we empirically validate this finding on a Twitter dataset. Using the equilibrium structure of the content landscape, we then examine the downstream performance of engagement-based optimization along several axes. Perhaps counterintuitively, the average quality of content consumed by users can decrease at equilibrium as gaming tricks become more costly for content creators to employ. Moreover, engagement-based optimization can perform worse in terms of user utility than a baseline with random recommendations, and engagement-based optimization is also suboptimal in terms of realized engagement relative to quality-based optimization. Altogether, our results highlight the need to consider content creator incentives when evaluating a platform's choice of optimization metric.
Improved Bayes Risk Can Yield Reduced Social Welfare Under Competition
Jun 26, 2023As the scale of machine learning models increases, trends such as scaling laws anticipate consistent downstream improvements in predictive accuracy. However, these trends take the perspective of a single model-provider in isolation, while in reality providers often compete with each other for users. In this work, we demonstrate that competition can fundamentally alter the behavior of these scaling trends, even causing overall predictive accuracy across users to be non-monotonic or decreasing with scale. We define a model of competition for classification tasks, and use data representations as a lens for studying the impact of increases in scale. We find many settings where improving data representation quality (as measured by Bayes risk) decreases the overall predictive accuracy across users (i.e., social welfare) for a marketplace of competing model-providers. Our examples range from closed-form formulas in simple settings to simulations with pretrained representations on CIFAR-10. At a conceptual level, our work suggests that favorable scaling trends for individual model-providers need not translate to downstream improvements in social welfare in marketplaces with multiple model providers.
Incentivizing High-Quality Content in Online Recommender Systems
Jun 14, 2023For content recommender systems such as TikTok and YouTube, the platform's decision algorithm shapes the incentives of content producers, including how much effort the content producers invest in the quality of their content. Many platforms employ online learning, which creates intertemporal incentives, since content produced today affects recommendations of future content. In this paper, we study the incentives arising from online learning, analyzing the quality of content produced at a Nash equilibrium. We show that classical online learning algorithms, such as Hedge and EXP3, unfortunately incentivize producers to create low-quality content. In particular, the quality of content is upper bounded in terms of the learning rate and approaches zero for typical learning rate schedules. Motivated by this negative result, we design a different learning algorithm -- based on punishing producers who create low-quality content -- that correctly incentivizes producers to create high-quality content. At a conceptual level, our work illustrates the unintended impact that a platform's learning algorithm can have on content quality and opens the door towards designing platform learning algorithms that incentivize the creation of high-quality content.