 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating LLMs for Text-to-SQL Parsing by Leveraging Sub-clause Frequencies
May 27, 2025



While large language models (LLMs) achieve strong performance on text-to-SQL parsing, they sometimes exhibit unexpected failures in which they are confidently incorrect. Building trustworthy text-to-SQL systems thus requires eliciting reliable uncertainty measures from the LLM. In this paper, we study the problem of providing a calibrated confidence score that conveys the likelihood of an output query being correct. Our work is the first to establish a benchmark for post-hoc calibration of LLM-based text-to-SQL parsing. In particular, we show that Platt scaling, a canonical method for calibration, provides substantial improvements over directly using raw model output probabilities as confidence scores. Furthermore, we propose a method for text-to-SQL calibration that leverages the structured nature of SQL queries to provide more granular signals of correctness, named "sub-clause frequency" (SCF) scores. Using multivariate Platt scaling (MPS), our extension of the canonical Platt scaling technique, we combine individual SCF scores into an overall accurate and calibrated score. Empirical evaluation on two popular text-to-SQL datasets shows that our approach of combining MPS and SCF yields further improvements in calibration and the related task of error detection over traditional Platt scaling.
OrcoDCS: An IoT-Edge Orchestrated Online Deep Compressed Sensing Framework
Aug 05, 2023Compressed data aggregation (CDA) over wireless sensor networks (WSNs) is task-specific and subject to environmental changes. However, the existing compressed data aggregation (CDA) frameworks (e.g., compressed sensing-based data aggregation, deep learning(DL)-based data aggregation) do not possess the flexibility and adaptivity required to handle distinct sensing tasks and environmental changes. Additionally, they do not consider the performance of follow-up IoT data-driven deep learning (DL)-based applications. To address these shortcomings, we propose OrcoDCS, an IoT-Edge orchestrated online deep compressed sensing framework that offers high flexibility and adaptability to distinct IoT device groups and their sensing tasks, as well as high performance for follow-up applications. The novelty of our work is the design and deployment of IoT-Edge orchestrated online training framework over WSNs by leveraging an specially-designed asymmetric autoencoder, which can largely reduce the encoding overhead and improve the reconstruction performance and robustness. We show analytically and empirically that OrcoDCS outperforms the state-of-the-art DCDA on training time, significantly improves flexibility and adaptability when distinct reconstruction tasks are given, and achieves higher performance for follow-up applications.
Parity Calibration
Jun 07, 2023In a sequential regression setting, a decision-maker may be primarily concerned with whether the future observation will increase or decrease compared to the current one, rather than the actual value of the future observation. In this context, we introduce the notion of parity calibration, which captures the goal of calibrated forecasting for the increase-decrease (or "parity") event in a timeseries. Parity probabilities can be extracted from a forecasted distribution for the output, but we show that such a strategy leads to theoretical unpredictability and poor practical performance. We then observe that although the original task was regression, parity calibration can be expressed as binary calibration. Drawing on this connection, we use an online binary calibration method to achieve parity calibration. We demonstrate the effectiveness of our approach on real-world case studies in epidemiology, weather forecasting, and model-based control in nuclear fusion.
Online Platt Scaling with Calibeating
Apr 28, 2023
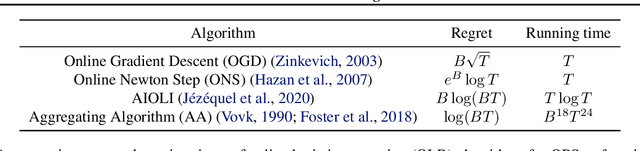

We present an online post-hoc calibration method, called Online Platt Scaling (OPS), which combines the Platt scaling technique with online logistic regression. We demonstrate that OPS smoothly adapts between i.i.d. and non-i.i.d. settings with distribution drift. Further, in scenarios where the best Platt scaling model is itself miscalibrated, we enhance OPS by incorporating a recently developed technique called calibeating to make it more robust. Theoretically, our resulting OPS+calibeating method is guaranteed to be calibrated for adversarial outcome sequences. Empirically, it is effective on a range of synthetic and real-world datasets, with and without distribution drifts, achieving superior performance without hyperparameter tuning. Finally, we extend all OPS ideas to the beta scaling method.
Faster online calibration without randomization: interval forecasts and the power of two choices
Apr 27, 2022We study the problem of making calibrated probabilistic forecasts for a binary sequence generated by an adversarial nature. Following the seminal paper of Foster and Vohra (1998), nature is often modeled as an adaptive adversary who sees all activity of the forecaster except the randomization that the forecaster may deploy. A number of papers have proposed randomized forecasting strategies that achieve an $\epsilon$-calibration error rate of $O(1/\sqrt{T})$, which we prove is tight in general. On the other hand, it is well known that it is not possible to be calibrated without randomization, or if nature also sees the forecaster's randomization; in both cases the calibration error could be $\Omega(1)$. Inspired by the equally seminal works on the "power of two choices" and imprecise probability theory, we study a small variant of the standard online calibration problem. The adversary gives the forecaster the option of making two nearby probabilistic forecasts, or equivalently an interval forecast of small width, and the endpoint closest to the revealed outcome is used to judge calibration. This power of two choices, or imprecise forecast, accords the forecaster with significant power -- we show that a faster $\epsilon$-calibration rate of $O(1/T)$ can be achieved even without deploying any randomization.
Top-label calibration
Jul 18, 2021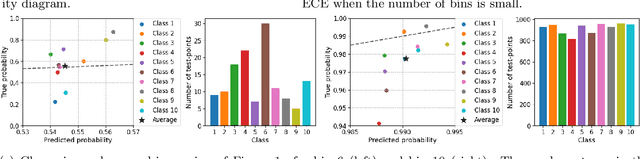
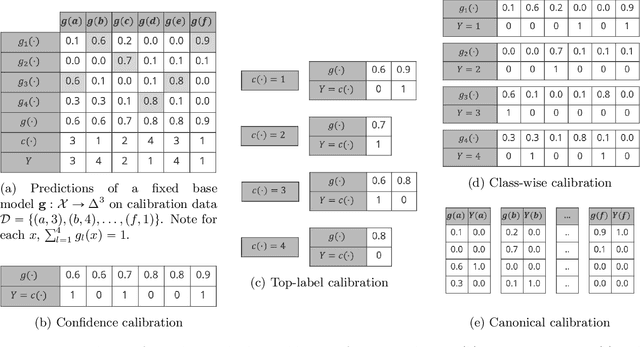

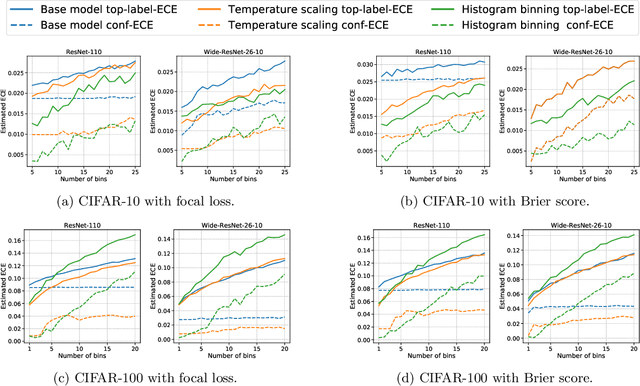
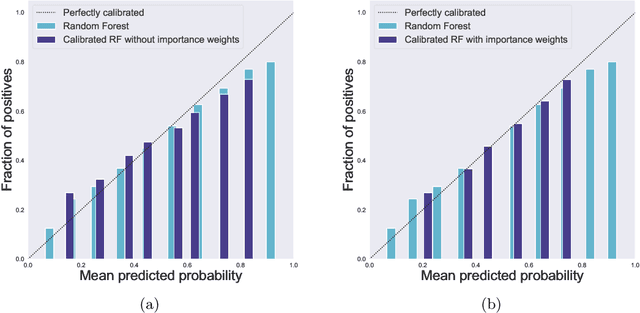
We study the problem of post-hoc calibration for multiclass classification, with an emphasis on histogram binning. Multiple works have focused on calibration with respect to the confidence of just the predicted class (or 'top-label'). We find that the popular notion of confidence calibration [Guo et al., 2017] is not sufficiently strong -- there exist predictors that are not calibrated in any meaningful way but are perfectly confidence calibrated. We propose a closely related (but subtly different) notion, top-label calibration, that accurately captures the intuition and simplicity of confidence calibration, but addresses its drawbacks. We formalize a histogram binning (HB) algorithm that reduces top-label multiclass calibration to the binary case, prove that it has clean theoretical guarantees without distributional assumptions, and perform a methodical study of its practical performance. Some prediction tasks require stricter notions of multiclass calibration such as class-wise or canonical calibration. We formalize appropriate HB algorithms corresponding to each of these goals. In experiments with deep neural nets, we find that our principled versions of HB are often better than temperature scaling, for both top-label and class-wise calibration. Code for this work will be made publicly available at https://github.com/aigen/df-posthoc-calibration.
Distribution-free calibration guarantees for histogram binning without sample splitting
May 10, 2021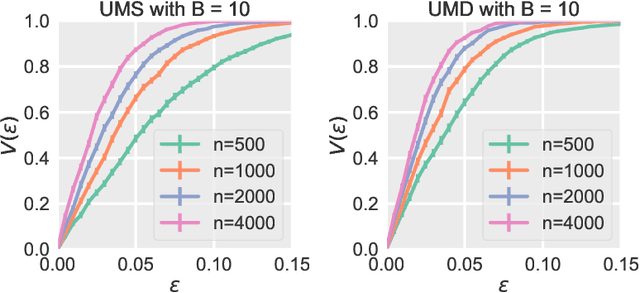
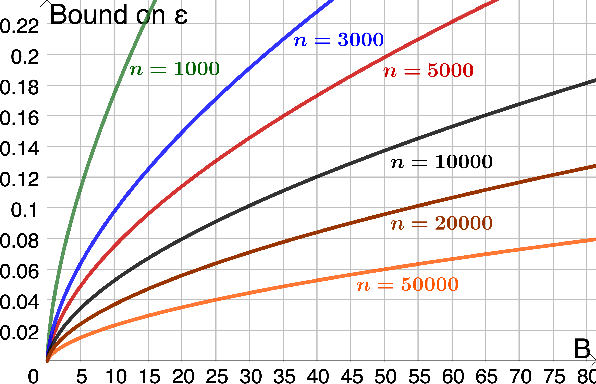
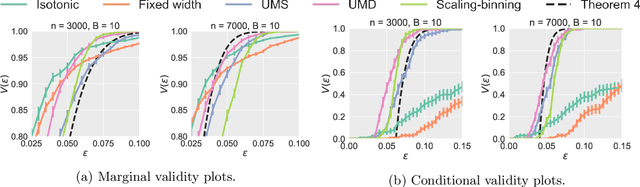
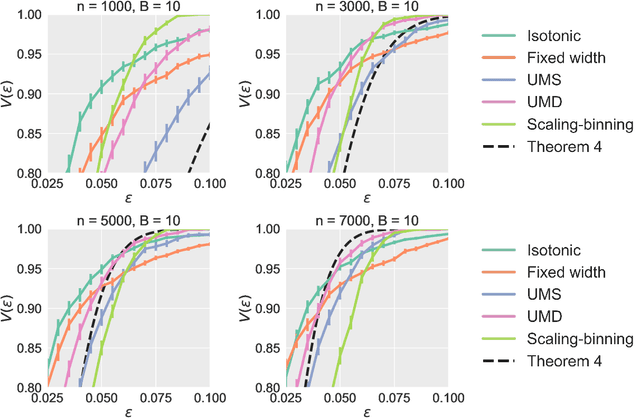
We prove calibration guarantees for the popular histogram binning (also called uniform-mass binning) method of Zadrozny and Elkan [2001]. Histogram binning has displayed strong practical performance, but theoretical guarantees have only been shown for sample split versions that avoid 'double dipping' the data. We demonstrate that the statistical cost of sample splitting is practically significant on a credit default dataset. We then prove calibration guarantees for the original method that double dips the data, using a certain Markov property of order statistics. Based on our results, we make practical recommendations for choosing the number of bins in histogram binning. In our illustrative simulations, we propose a new tool for assessing calibration -- validity plots -- which provide more information than an ECE estimate.
Modern Machine and Deep Learning Systems as a way to achieve Man-Computer Symbiosis
Jan 24, 2021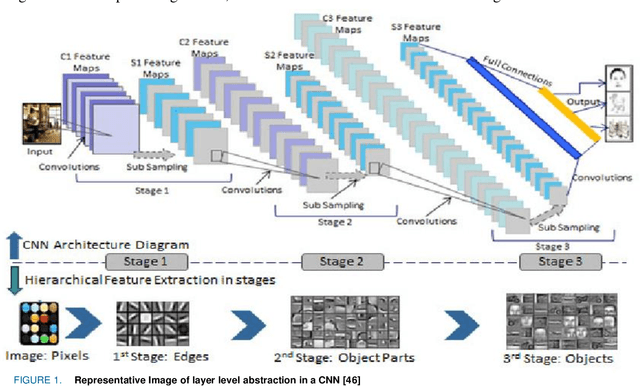
Man-Computer Symbiosis (MCS) was originally envisioned by the famous computer pioneer J.C.R. Licklider in 1960, as a logical evolution of the then inchoate relationship between computer and humans. In his paper, Licklider provided a set of criteria by which to judge if a Man-Computer System is a symbiotic one, and also provided some predictions about such systems in the near and far future. Since then, innovations in computer networks and the invention of the Internet were major developments towards that end. However, with most systems based on conventional logical algorithms, many aspects of Licklider's MCS remained unfulfilled. This paper explores the extent to which modern machine learning systems in general, and deep learning ones in particular best exemplify MCS systems, and why they are the prime contenders to achieve a true Man-Computer Symbiosis as described by Licklider in his original paper in the future. The case for deep learning is built by illustrating each point of the original criteria as well as the criteria laid by subsequent research into MCS systems, with specific examples and applications provided to strengthen the arguments. The efficacy of deep neural networks in achieving Artificial General Intelligence, which would be the perfect version of an MCS system is also explored.
Distribution-free binary classification: prediction sets, confidence intervals and calibration
Jun 18, 2020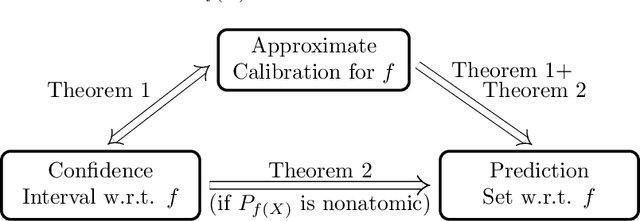
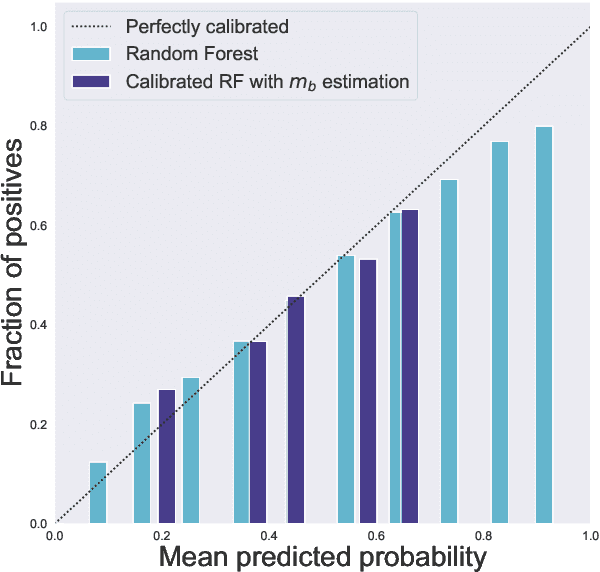
We study three notions of uncertainty quantification---calibration, confidence intervals and prediction sets---for binary classification in the distribution-free setting, that is without making any distributional assumptions on the data. With a focus towards calibration, we establish a 'tripod' of theorems that connect these three notions for score-based classifiers. A direct implication is that distribution-free calibration is only possible, even asymptotically, using a scoring function whose level sets partition the feature space into at most countably many sets. Parametric calibration schemes such as variants of Platt scaling do not satisfy this requirement, while nonparametric schemes based on binning do. To close the loop, we derive distribution-free confidence intervals for binned probabilities for both fixed-width and uniform-mass binning. As a consequence of our 'tripod' theorems, these confidence intervals for binned probabilities lead to distribution-free calibration. We also derive extensions to settings with streaming data and covariate shift.
Shallow Encoder Deep Decoder (SEDD) Networks for Image Encryption and Decryption
Jan 09, 2020
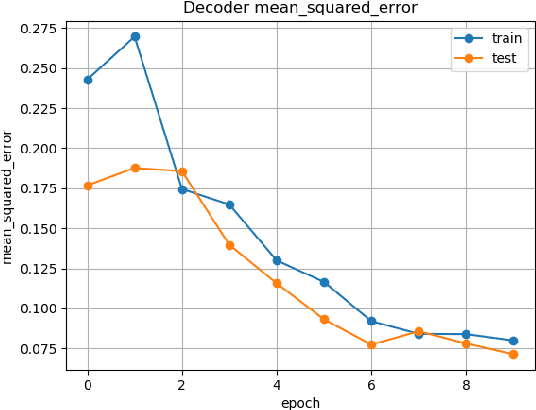

This paper explores a new framework for lossy image encryption and decryption using a simple shallow encoder neural network E for encryption, and a complex deep decoder neural network D for decryption. E is kept simple so that encoding can be done on low power and portable devices and can in principle be any nonlinear function which outputs an encoded vector. D is trained to decode the encodings using the dataset of image - encoded vector pairs obtained from E and happens independently of E. As the encodings come from E which while being a simple neural network, still has thousands of random parameters and therefore the encodings would be practically impossible to crack without D. This approach differs from autoencoders as D is trained completely independently of E, although the structure may seem similar. Therefore, this paper also explores empirically if a deep neural network can learn to reconstruct the original data in any useful form given the output of a neural network or any other nonlinear function, which can have very useful applications in Cryptanalysis. Experiments demonstrate the potential of the framework through qualitative and quantitative evaluation of the decoded images from D along with some limitations.